参考
存储
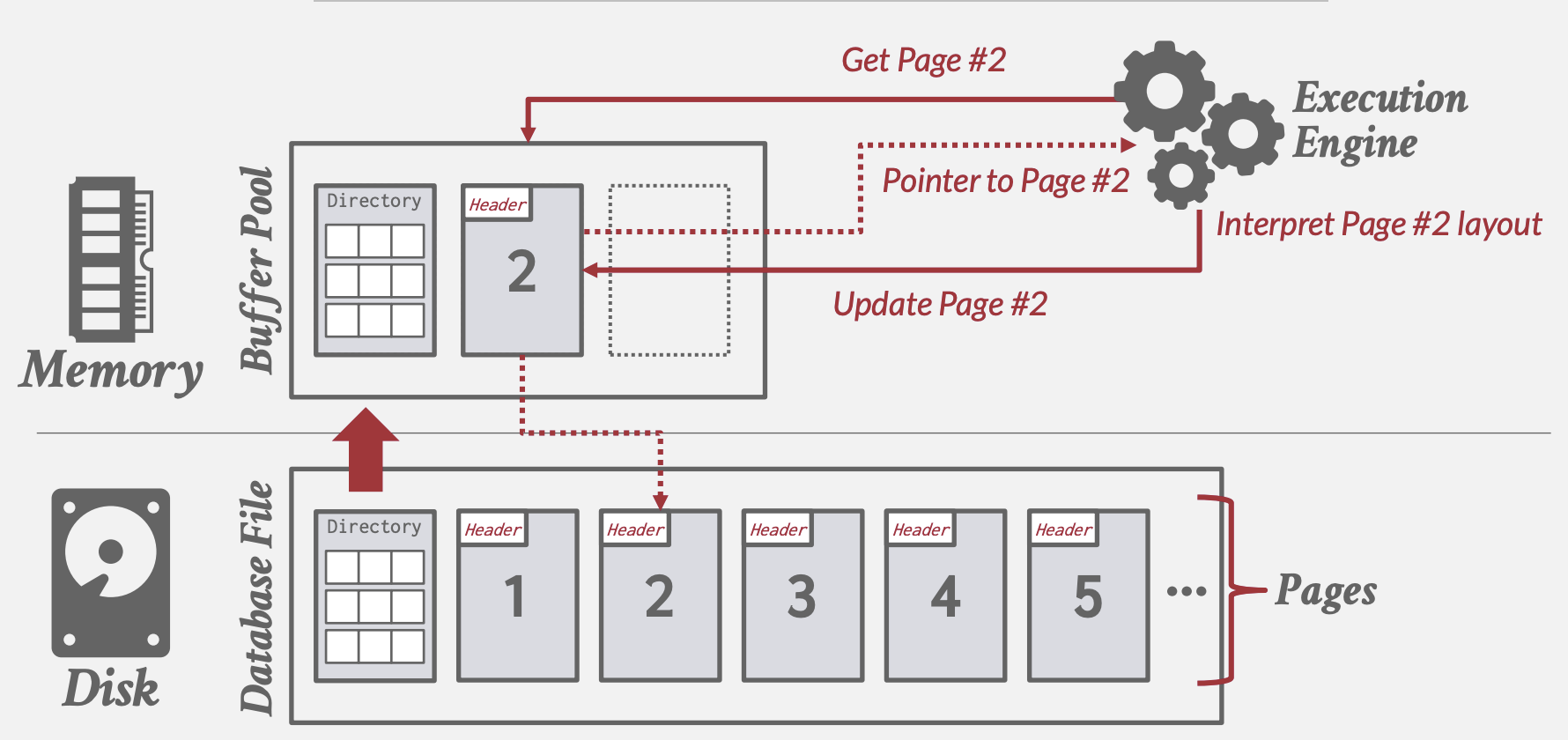
Disk-Oriented DBMS
面向磁盘的DBMS将数据存放于非易失性磁盘,操作数据前需将数据从磁盘读入内存。
- 通过Buffer Pool来管理数据在内存和磁盘之间的置换
- Execution Engine执行查询,向Buffer Pool请求指定page的数据,后者负责将page读入内存返回内存指针
- Buffer Pool Manager需保证该page在Execution Engine执行期间保持在该内存中
虚拟内存的问题
为什么不直接以来操作系统虚拟内存? 操作系统虚拟内存(mmap)管理文件在内存和硬盘中的置换,适合只读文件。数据库一般自己管理实现定制化功能(madvice, mlock, msync):
- 事务需要以正确的顺序flush脏页(并发控制)
- 数据预读取
- 基于语义实现更高效率的缓存置换策略,减少停顿时间
- 线程调度优化
- mmap异常处理困难:校验页, SIGBUS处理
- mmap会导致OS数据结构竞争:TLB shootdowns
文件表示
存储管理器(存储引擎)
- 以pages形式管理数据库文件:跟踪页面读写和可用空间
- 读写调度以优化page时间空间局部性
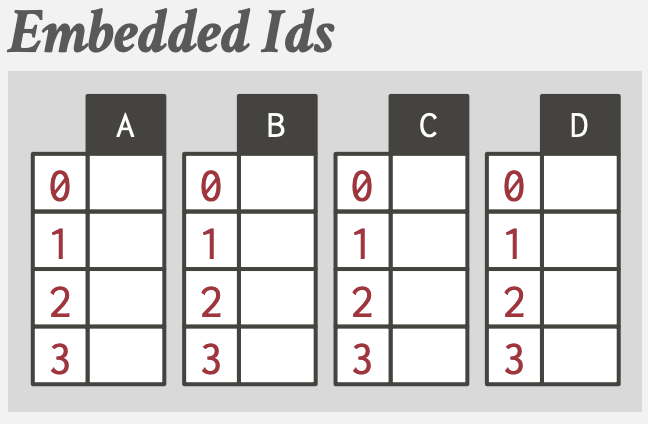
Page
固定大小的数据块,用于存储数据库记录。
- 可以包含Tuple(行)、元数据、索引、日志记录等
- 大多数数据库不混存不同类型数据
- 一些数据库要求页面内容必须自包含(页面存放描述该页内容的元数据,其它页的丢失不会影响该页内容读取)
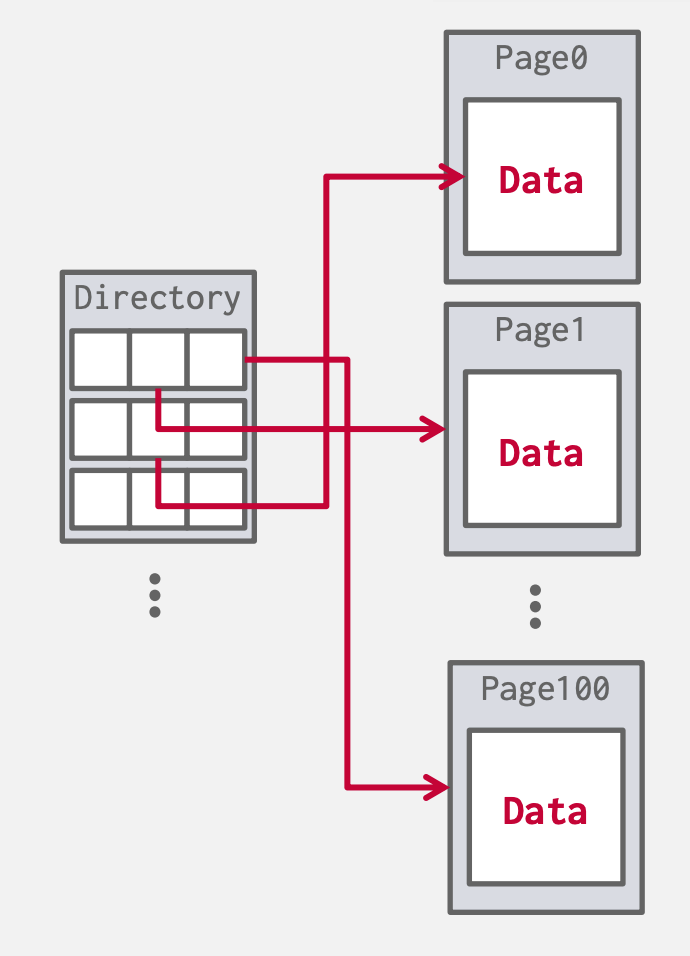
- 每个页面需要有一个唯一标识,数据库通过间接层来映射page ids和物理存储位置(方便管理,文件位置移动只需修改Page Directory)
- 数据库页面大小:512B-16KB
硬件页:设备能够保证“故障安全写入(failsafe)”/原子写入的块
Heap file
- 一组无序的page集合
- API: Create/Get/Write/Delete Page
- 支持遍历所有页面
- 通过元数据跟踪已存页面和空余空间
Page Directory 特殊的Page:
- 记录每个page id到文件位置的映射
- 记录每个page空闲slots数
- 维护空闲的页面
- 确保Page Directory和数据Page间同步(通过日志解决两种页无法原子写入)
Page的布局
每个Page面包含header记录了该页的元数据:
- Page size.
- Checksum.
- DBMS version.
- Transaction visibility
- Self-containment. (自包含元数据)
Page内部如何存储数据
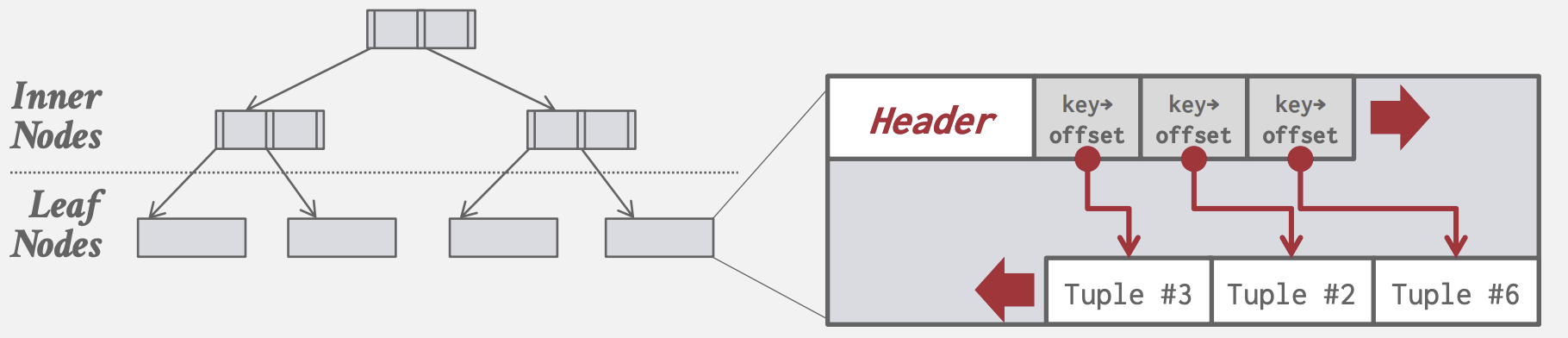
Slotted Pages Storage
多数DBMS使用的方法
- slot数组: 映射每个元组(Tuple)的起始偏移量。
- Header记录已使用slot数,最后一个slot的偏移量
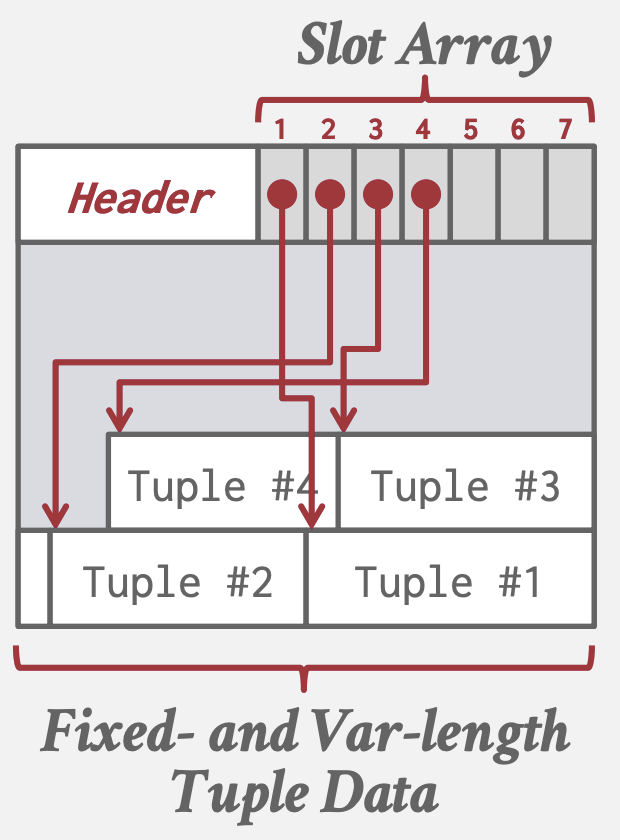
- 添加tupe时, slot数组从头部向尾部增长, 而tupe数据则从尾部向头部增长,两个部分重叠时标志page已满
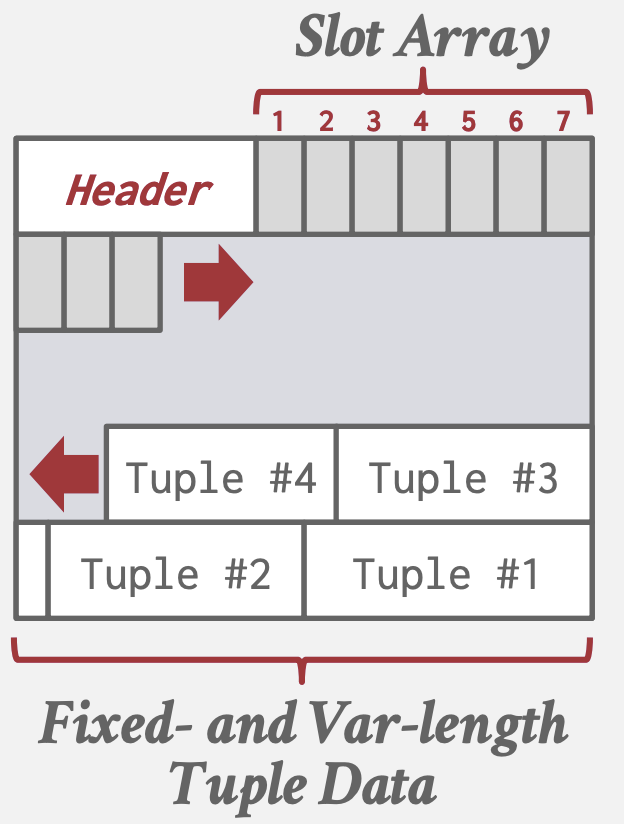
- 通过slot数组的间接映射,page内部可实现系统上层无感地移动Tuple,只需修改对应slo数组偏移量即可,上层依旧能通过同样的page id + slot数组下标查找,如一些数据库会在Tuple删除后执行compact操作。
缺点
- 碎片化:删除tuples会在page中产生gap
- 随机IO访问: 更新不同位置的tuples性能差
- 多余的IO: 更新tuples需要读取整块磁盘page
Index-Organized Storage
- Page存储索引数据结构
- 将Tuple作为value存储至索引数据结构中
- 通常根据key的排序存储
- 如MySQL的聚簇索引将tuple存储在B+树的叶子结点中
Record Id
- 标识Tuple的唯一id
- 通常为: file_id + page_id + offset/slot
- 可能包含文件位置的时机
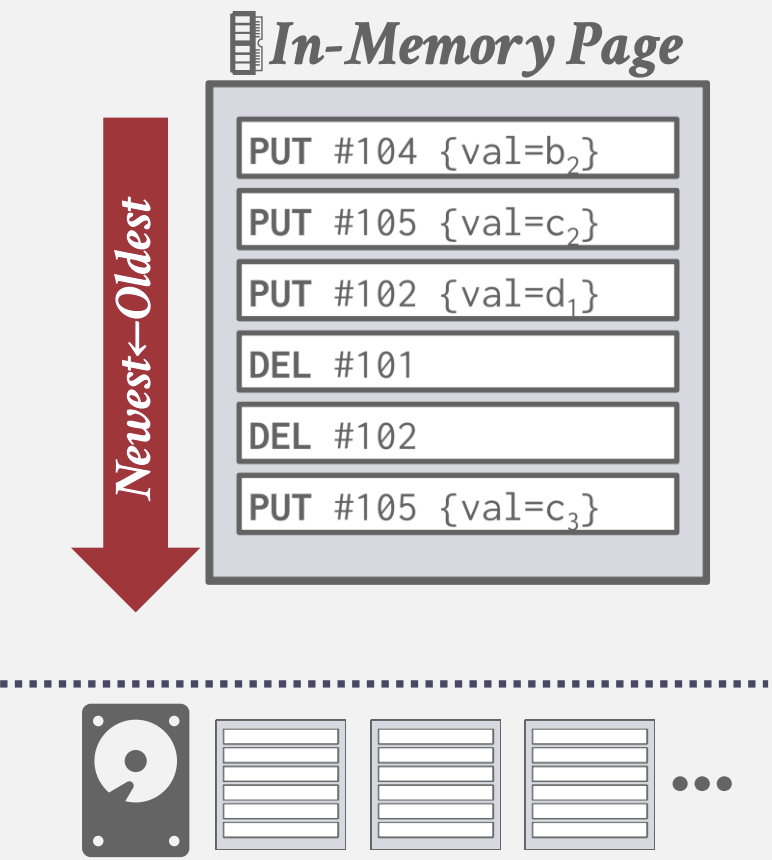
Log Structured Storage
- Page中存储Log Records: 记录了Tuple的修改信息
- 每个Log Entry表示了一个Tuple的Put/Delete操作, 且包含Tuple的唯一标识
- Put Record包含了Tuple内容, Delete Record将Tuple标记为已删除
- 利用磁盘顺序访问速度快的特性: 在内存中append Log Records, 顺序地写入磁盘, 已落盘page不可修改
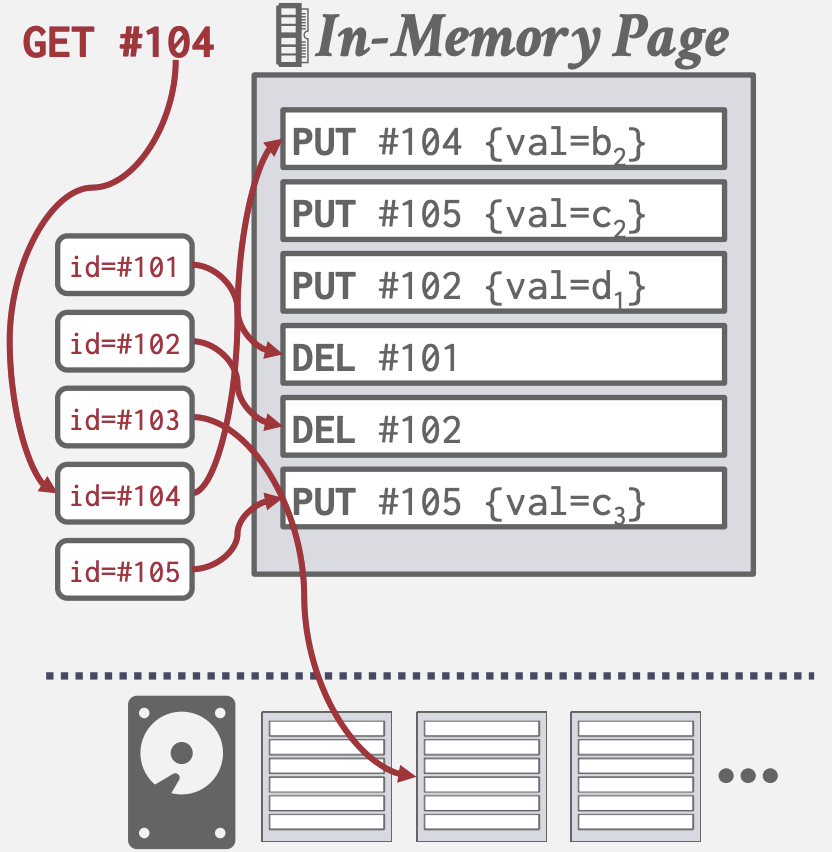
- 但读取时需要从新到旧扫描Log Records
- 通过构建index,将Tuple映射到最新Log Record偏移量
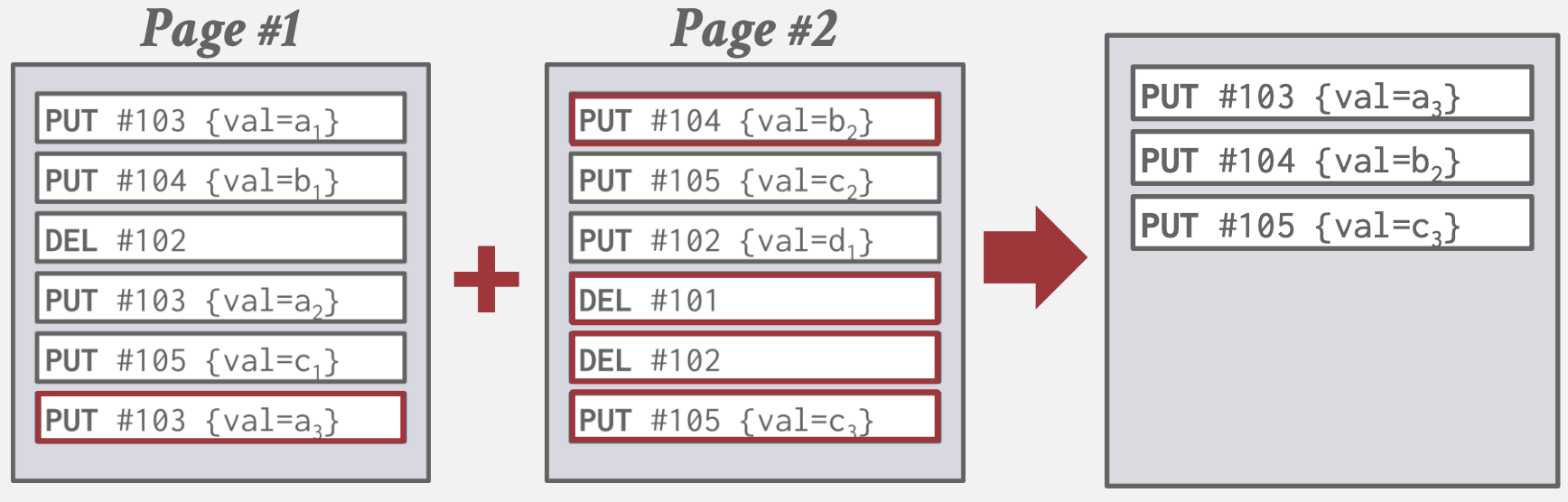
- 可以周期性compact, 使Tuple只保留一条记录
- 通过Sorted String Tables(SSTables)维护id有序索引加速查找
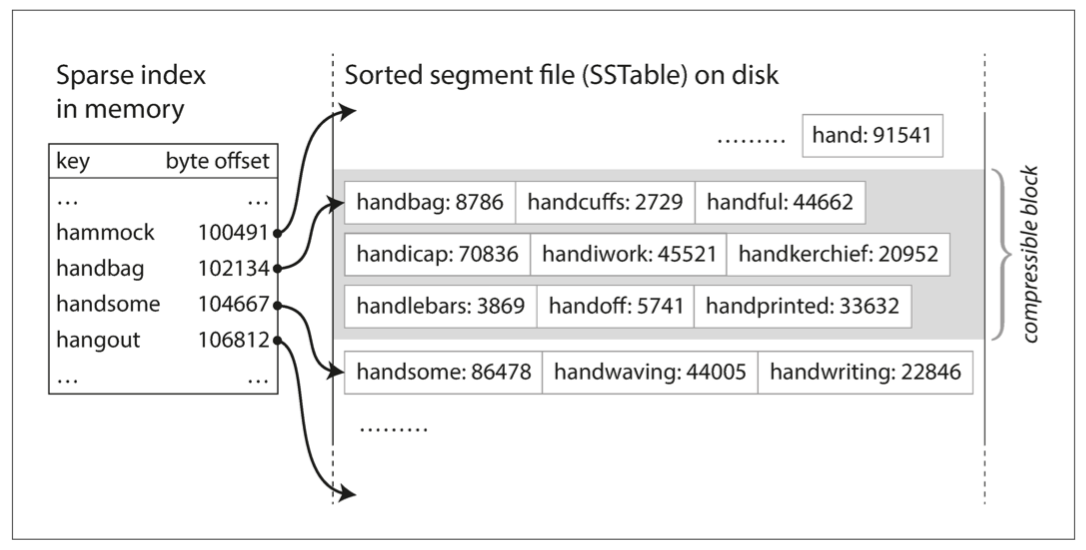
- 分层并维护多个SSTables即Log-Structured Merge-Tree(LSM tree)
- Write-Amplification(写入放大): compact时需要从磁盘读出, 合并后再次写入
Tuple的布局
Tuple:
| Header | Attribute Data |
- Header记录元数据如:可见信息、NULL值的BitMap等
- Data部分存放属性的实际值(以字节序列形式),通常按创建table时指定的顺序存储
- Catalogs包含table的schema信息, 以此来解释Attribute Data的类型和值
- 多数DBMS不允许Tuple大小超过一个page,因为要额外的元数据和指针来表示剩余部分所在overflow page
- 可能有反范式化Tuple数据,如prejoin会将不同表的相关的Tuples存储到同个page。可读取降低IO但是更新成本高
字长对齐
- 为了性能: 减少跨缓存行
- 减少错误: 有些ISA不支持非对齐访问(如ARM早期版本) 对齐方式有:
- 添加padding字节
- 重排序tuple的属性凑整字节
数据类型表示
- 变长类型如VARCHAR/VARBINARY/TEXT/BLOB: header记录长度, 跟着实际数据字节序列(大数据则存储指向External File的指针)
- 时间日期类型如TIME/DATE/TIMESTAMP: 32/64位integer表示的Unix Epoch时间戳
- Null Data Types:
- NULL Column Bitmap Header: 常用, bitmap指明哪些属性为NULL
- Special Value: 如用
INT_32MIN来代表NULL - 各属性都记录一个NULL Flag: 由于字节对齐可能会耗费超过1bit空间
- 定点数类型如NUMERIC/DECIMAL: 通常以精确的变长二进制形式(如string) + 额外的元数据(如长度和小数点位置)存储,如PostgreSQL和MySQL。以性能换准确性, 如PostgreSQL 和MySQL
Catalogs
Catalogs存放了数据库的元数据:
- Tables, columns, indexes, views
- Users, permissions
- Internal statistics
多数DBMS将Catalogs存储在特殊的tables中,如INFORMATION_SCHEMA, 用代码初始化该table
存储模型
工作负载类型
- 联机事务处理OLTP(On-Line Transaction Processing): 简单读写少量entity数据
- 联机分析处理OLAP(On-Line Analytical Processing): 读取大数据进行复杂查询
- 混合事物分析处理HTAP(Hybrid Transaction/Analytical Processing): 同时支持OLTP和OLAP 不同的存储模型适应于不同的工作负载:
N-ary Storage Model
即Row Storage(行式存储). 将每个tuple的属性连续存储到page中 适用于OLTP: 只操作常数个entity, 大量执行insert操作.
- +insert, update, delete 很快
- +对于需要整个tuple的查询很友好
- +可以利用Index-Organized Storage
-
-对于扫描大量tuple且只要其部分属性的查询效率低: 读取大量无用数据, 内存局部性差
SELECT COUNT(U.lastLogin), EXTRACT(month FROM U.lastLogin) AS month FROM useracct AS U WHERE U.hostname LIKE '%.gov' GROUP BY EXTRACT(month FROM U.lastLogin)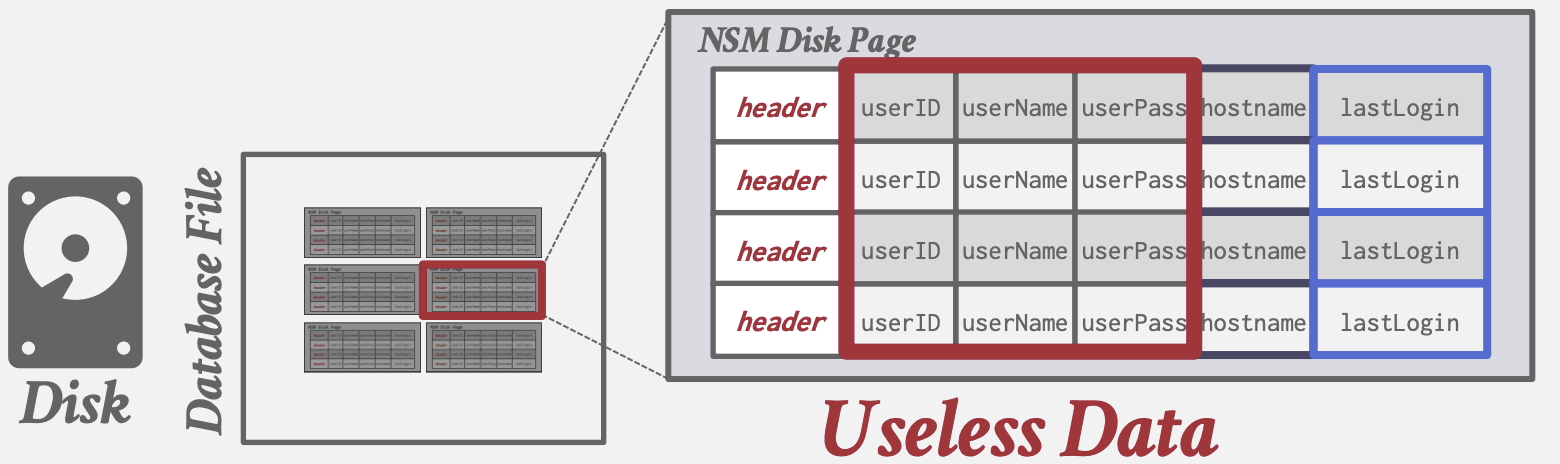
- -不利于压缩: 单个tupe各属性值域不同压缩率低
Decomposition Storage Model
即Column Storage(列式存储). 将所有tuple中一列属性连续存储到page中
适用于OLAP: 只读扫描整个table的部分属性
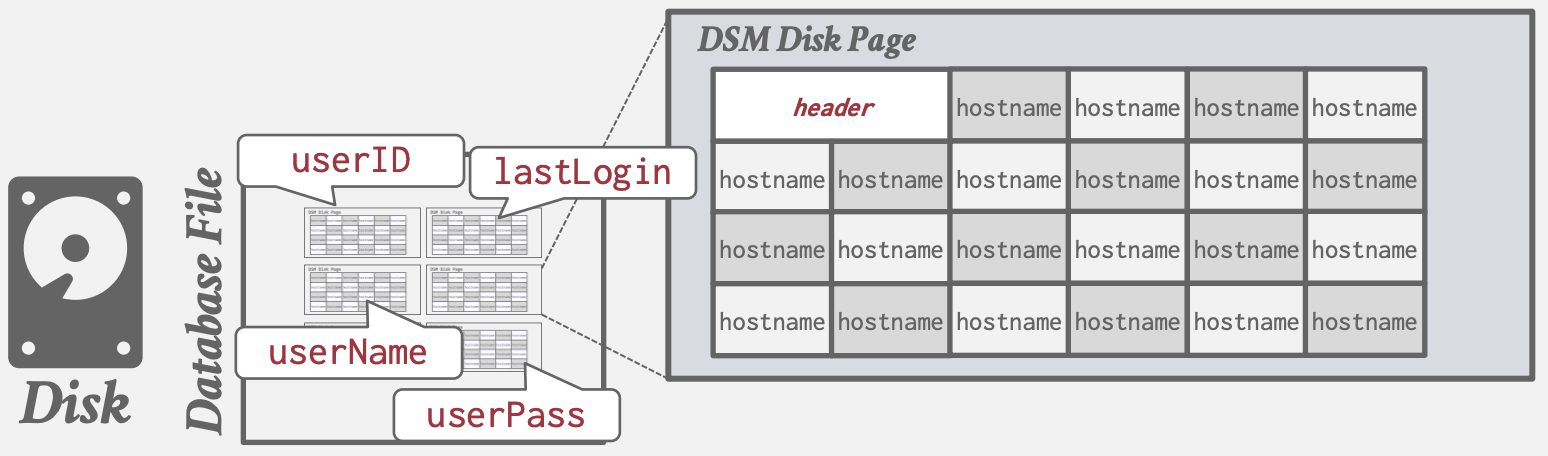
- +减少不必要的IO, 只读取需要的属性
- +提高了内存局部性和缓存命中率
- +更利于数据压缩
- -对于点查询, inserts, updates, deletes慢, 因为Tuple得进行splitting拆分/stitching拼接/reorganization重组
Tuple拆分和拼接(关联同个Tuple的不同属性):
- Fixed-length Offsets: 同一个属性, 值的长度相同. 同个tuple不同列值的offset相同, 该offset = 内存偏移地址 / 属性固定长度. 通过dictionary compression将变长数据转换为定长值.
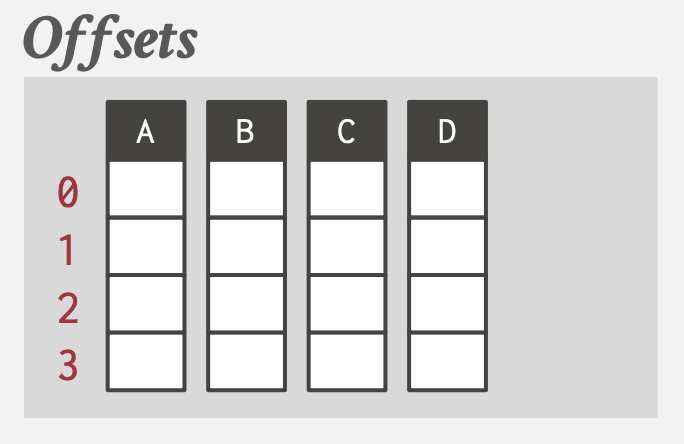
- 内置tuple id: 列的每一个值都额外保存一个tuple id; 还需要一个表来映射tuple id到所有属性值的位置.
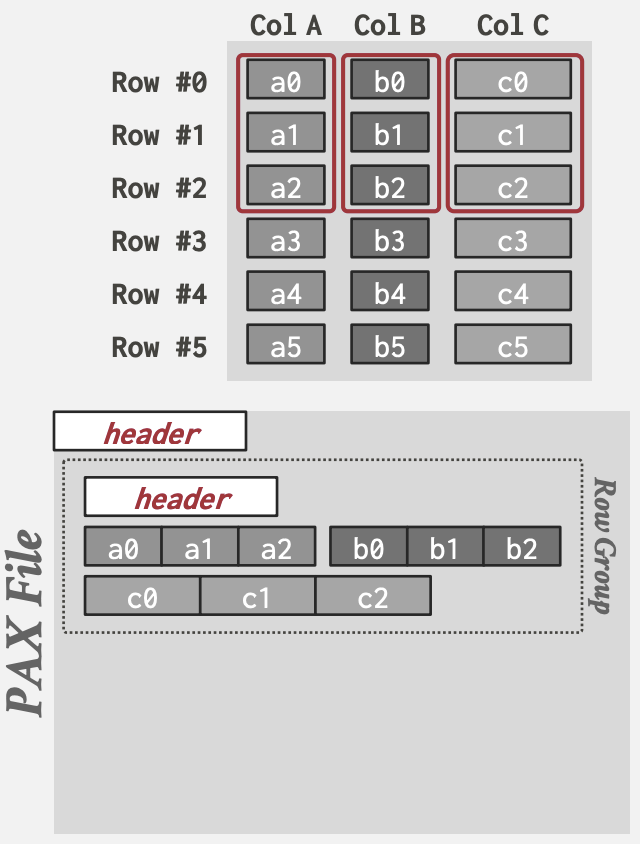
Partition Attributes Across
混合了两种模式, 为了能获益于DSM的性能同时保持NSM的空间局部性: 前面OLAP查询例子中WHERE如果需要扫描多个属性, DSM的拆分会导致局部性不佳.
先将table的rows水平分割成rows group, 每个row group的属性再垂直切割成按列存储.
全局header中directory维护每个row group在文件中的offset.
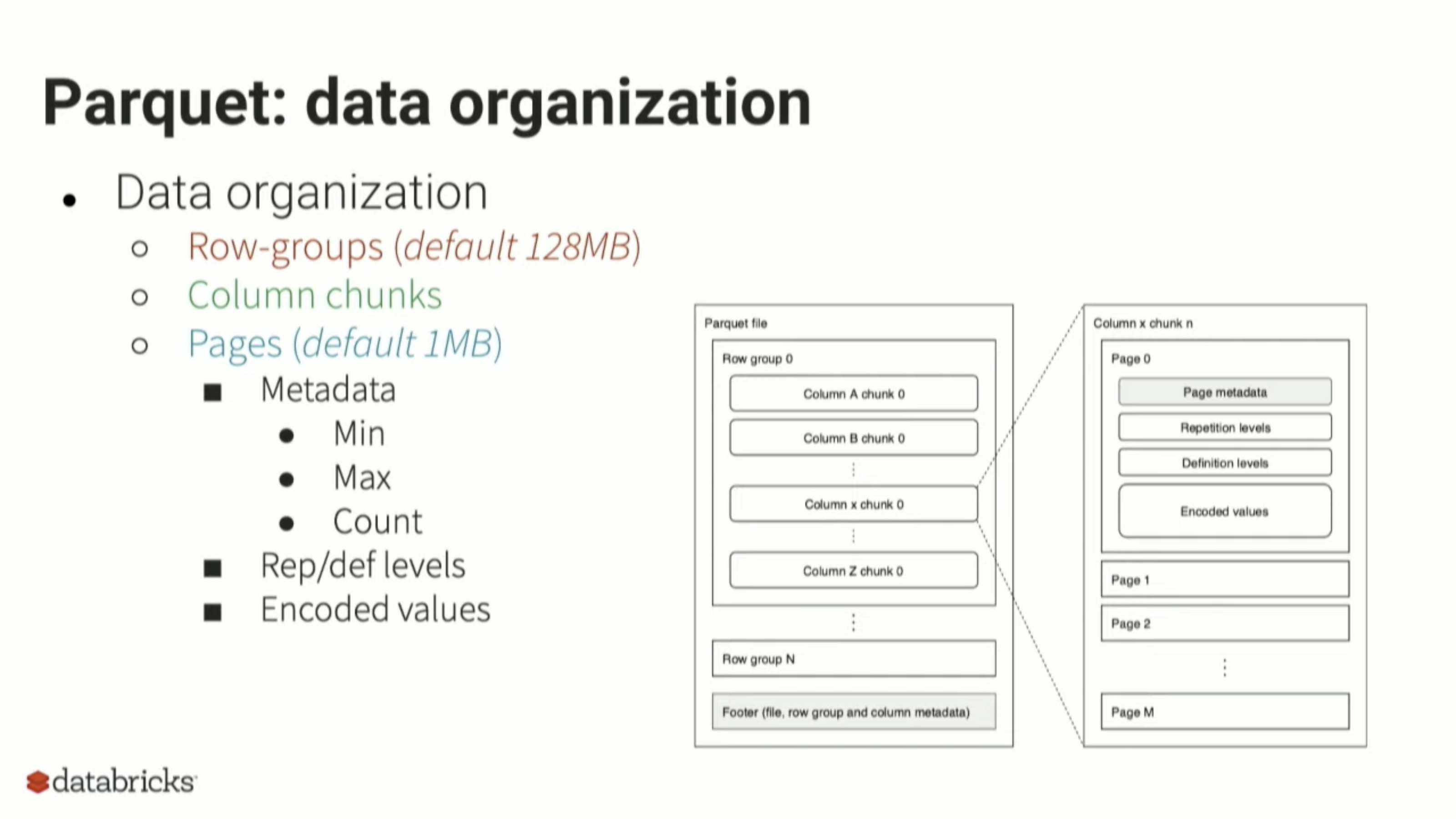
比如, Parquet将row group大小设置为128MB:
压缩
- 压缩能增加每次IO获取的数据量, 减少DRAM要求
- 权衡计算速度 vs 压缩率
目标
- 生成定长值(变长的属性存到另外的pool)
- 执行查询时尽量推迟解压缩
- 无损
粒度
- Block Level: Tuple中的块
- Tuple Level: 整个tuple (适用于NSM)
- Attribute Level: 一个tuple中的一或多个属性
- Columnar Level: 多个tuple的相同属性(适用于DSM)
Naive Compression
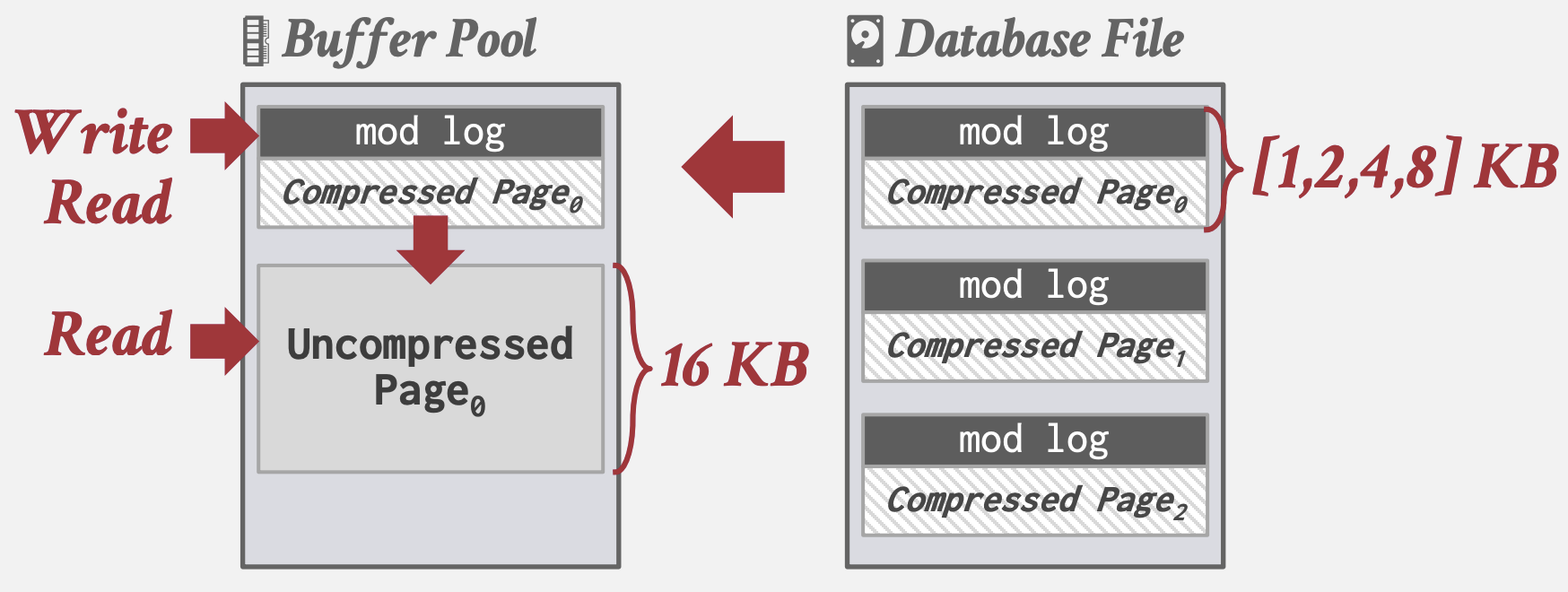
朴素地使用通用压缩算法以二进制形式压缩, 如gzip, LZO, LZ4, Snappy, Brotli, Oracle OZIP, Zstd. 工程上通常不会用太高压缩率的算法保证压缩/解压速度. 朴素压缩没有考虑schema的高级语义, 无法对查询计划进行优化. MySQL Innodb使用了该方式:
- 将Page划分对齐为若干KB, 以减少每次读写时压缩解压的范围, 存储到Buffer Pool
- 为了避免每次写都进行解压, 将写记录到额外的mod log; 读取时记录在mod log则无序解压已压缩Page.
Columnar Compression
我们希望DBMS能够无需解压, 通过将查询转换, 直接操作已压缩数据. 可以利用以下DSM的Columnar Compression算法 Run-Length Encoding (RLE)
- 将列中相同的值压缩为3元组: (属性值, 开始位置, 连续个数)
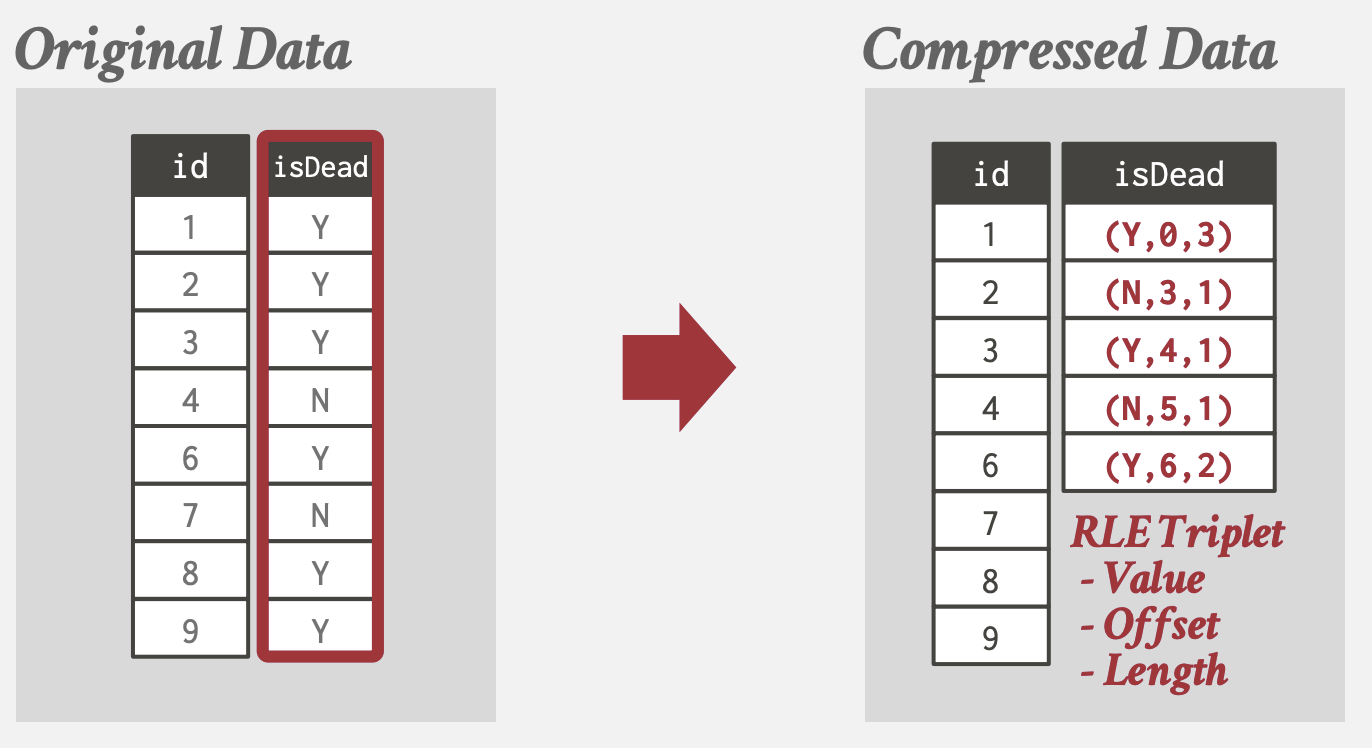
- 更适用于已排序列
- 通过转换查询直接操作已压缩数据:
SELECT isDead, COUNT(*)
FROM users
GROUP BY isDead
-- 转化为sum(连续个数)
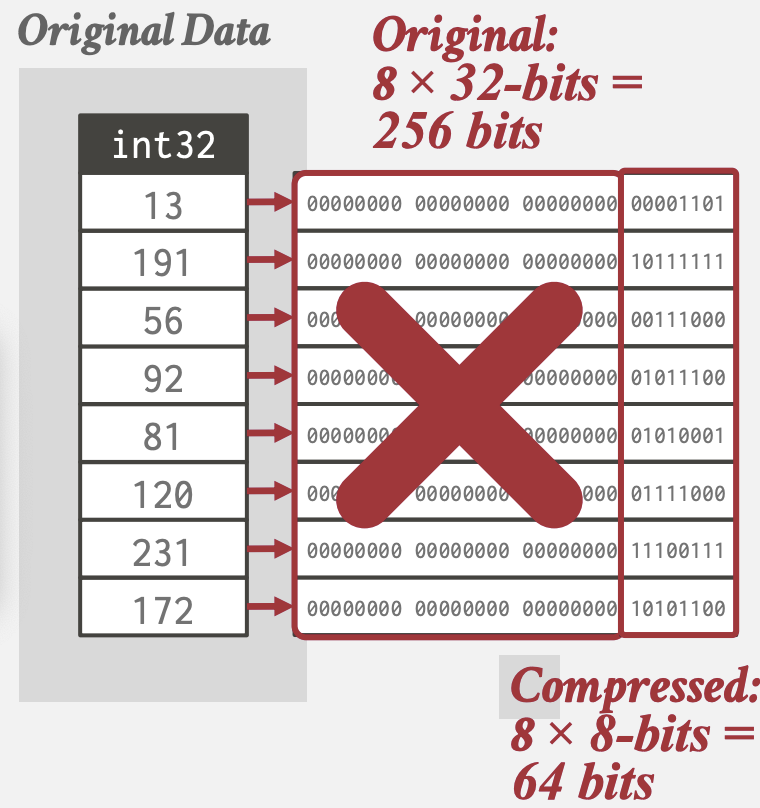
Bit-Packing Encoding
列中所有值都比数据类型定义的范围小, 则直接截断bit数
Mostly Encoding
Bit-Packing的变种, 对于小部分超出范围无法压缩的值特别维护一张表存储.
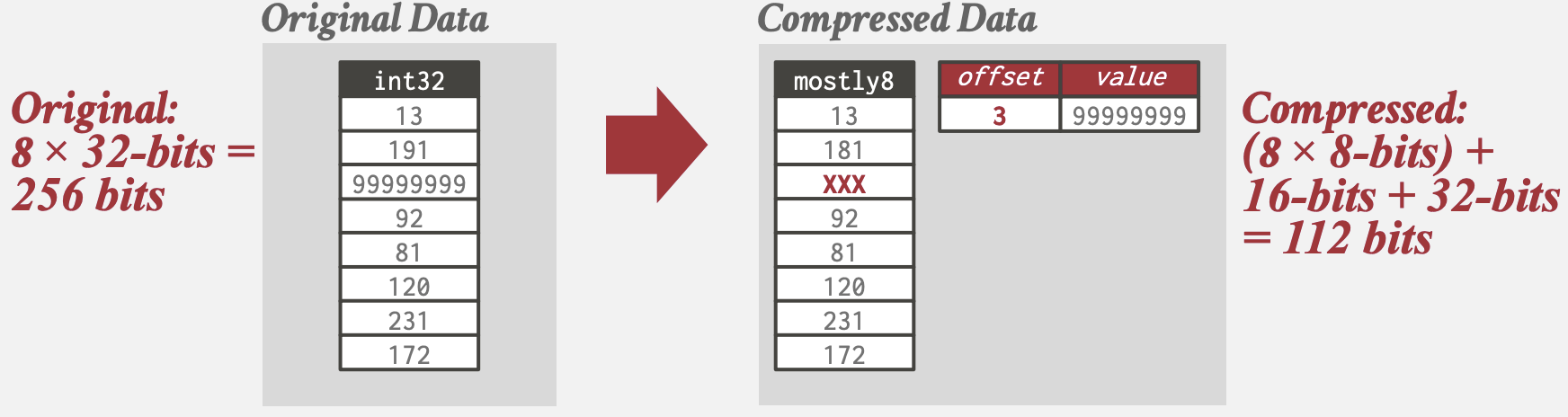
如Amazon Redshift使用了Mostly Encoding
Bitmap Encoding
- 为属性的每个唯一value存储一个bitmap, 某value的bitmap的第i位代表第i个tuple是否有该value, 从而无需重复地存储重复的value
- 为了避免分配大块连续内存, 可以将bitmap分割成若干block
- 仅适用于value集合的基数/势较低的属性, 否则bitmap可能比原始数据大

如一些数据库提供的bitmap indexes
Delta Encoding
- 记录同一列中相邻value的差值
- 基值可以是原列中的的, 或单独存储一个查找表
- 可以结合RLE使用

Dictionary Compression
- 将频次高的value替换为更小的定长code, 并维护code到原始值的映射(dictionary)
- DBMS最常使用的压缩方式
- 支持快速编码/解码以及范围查询
- 支持保留与原始值相同的顺序排序
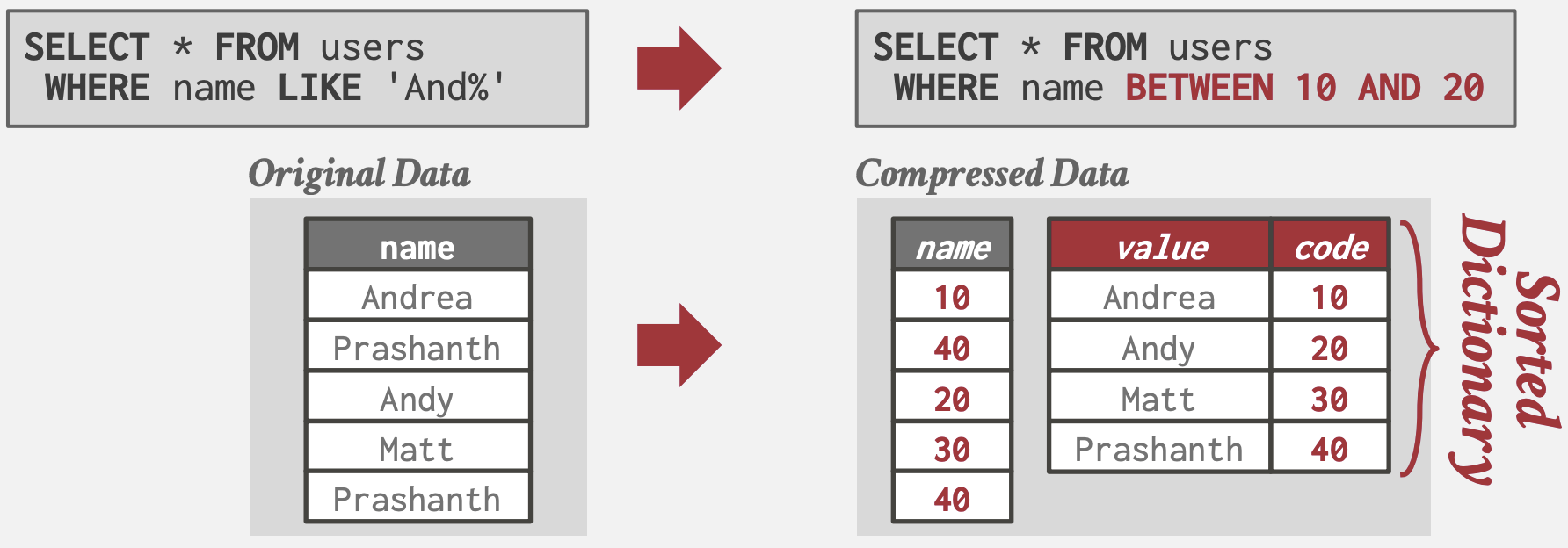
- 优化: 如果只对压缩列进行distinct查询, 则只需读取dictionary无需扫描原列:
-- 仍然需扫描原列
SELECT name FROM users
WHERE name LIKE 'And%'
-- 只需读取dictionary
SELECT DISTINCT name
FROM users
WHERE name LIKE 'And%'
Dictionary数据结构
- Array: 简单但更新成本高; 适用于不可变数据
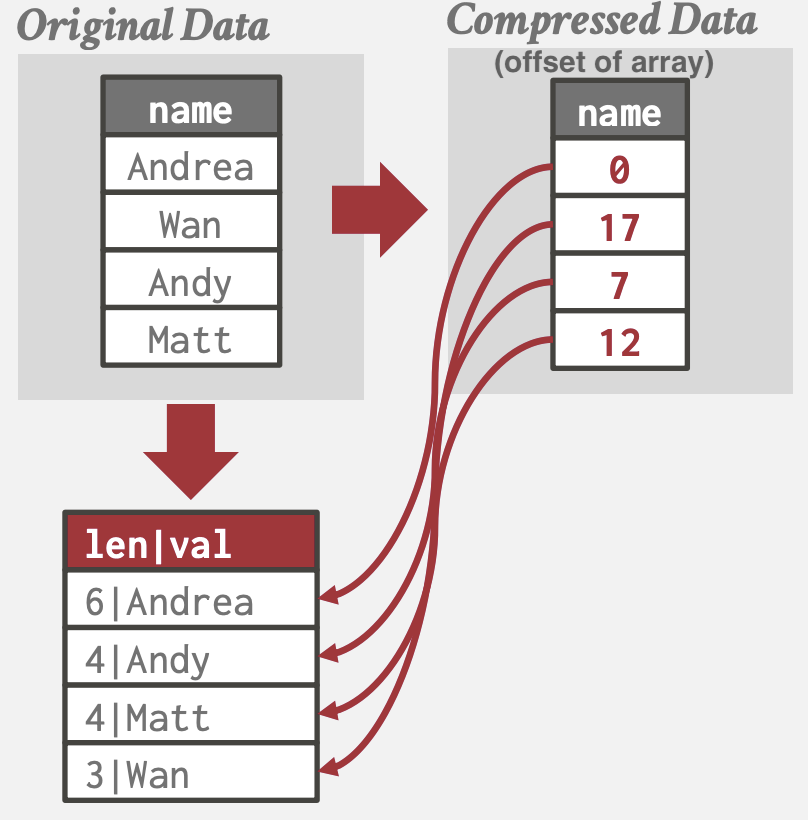
- Hash: 速度快且紧凑; 但不支持范围和前缀查询
- B+ Tree: 比hash table慢些, 且占用更多内存; 但支持范围查询和前缀查询
内存管理
目的
空间控制
- Page在磁盘上的写入位置
- 目标: 尽可能将经常一起使用的Page在磁盘上物理上靠近
时间控制
- 何时将Page读入内存以及何时将其写入磁盘
- 目标: 最小化由于从磁盘读取数据而导致的停顿次数
Locks和Latches
Locks
- 高级别的逻辑原语,用于保护数据库的逻辑内容(如元组、表、数据库)免受其他事务的干扰
- Lock将在其整个事务持续时间内持有
- 数据库系统可以向用户公开查询运行时持有的锁
- 锁需要能够回滚更改
Latches
- DBMS在其内部数据结构(如哈希表、内存区域)的临界区使用的低级别保护原语
- 只在执行操作的时间内持有
- 无需回滚更改
Buffer Pool
内存组织
- 在数据库内分配的一个大内存区域,用于存储从磁盘读取的Page
- 组织成一个Page的数组, 每个条目称为一个frame
- 当DBMS请求一个Page时,它会从磁盘复制到Buffer Pool的一个Frame中
- 脏页面可以被缓存起来,不立即写回
- 需要Latch来解决Page Table的线程竞争修改
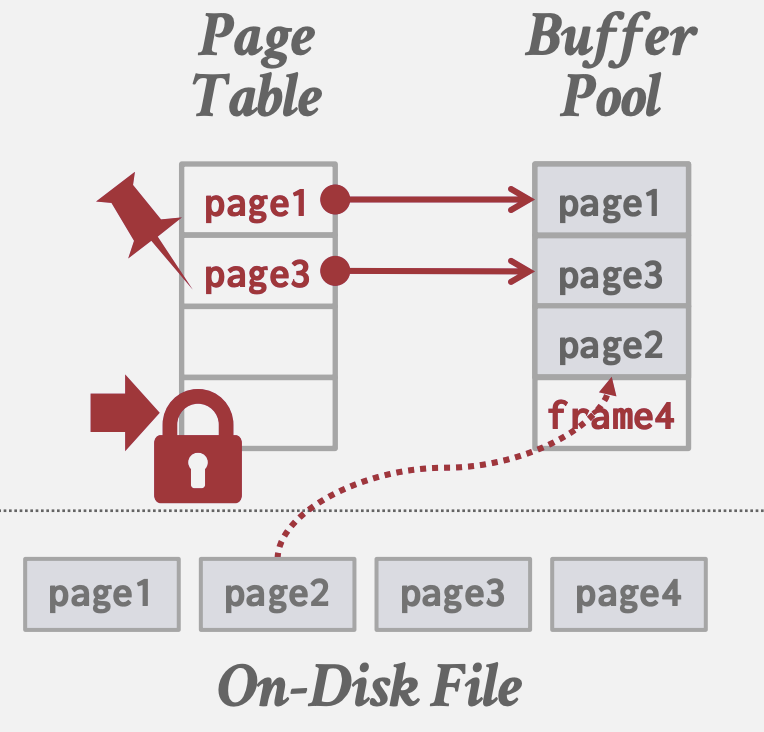
Page Table
- 一个在内存中的哈希表,用于跟踪当前在内存中的Page
- 将Page ID映射到Buffer Pool中的Frame位置; 由于Buffer Pool中Page的顺序不一定和磁盘上的顺序一致,需要该间接层来确定Page位置
- 维护每个Page的额外元数据:
- 脏标志: 由线程在修改Page时设置, 向存储管理器指示Page必须写回磁盘
- 引用计数: 跟踪当前访问该Page的线程数(读取或修改), 大于零则不允许存储管理器从内存中逐出该Page
- 访问跟踪信息
内存分配策略
全局策略
为所有活动事务找到分配内存的最佳决策
本地策略
- 使单个查询或事务运行更快的决策, 不考虑并发的事务
- 但需要支持page共享
大多数系统使用全局和本地视图的组合
Buffer Pool优化
Multiple Buffer Pools
DBMS可以为不同的目的维护多个Buffer Pool, 如:
- 每个数据库一个Buffer Pool
- 每个Page类型一个Buffer Pool。如为索引创建更小Page大小的Buffer Pool: 索引节点大小
每个Buffer Pool都可以采用适合其存储数据的策略; 有助于减少Latch争用并提高局部性。
将Page映射到Buffer Pool的方法:
- Object ID: 扩展Record ID以包含Object ID, 通过其将对象映射到特定Buffer Pool
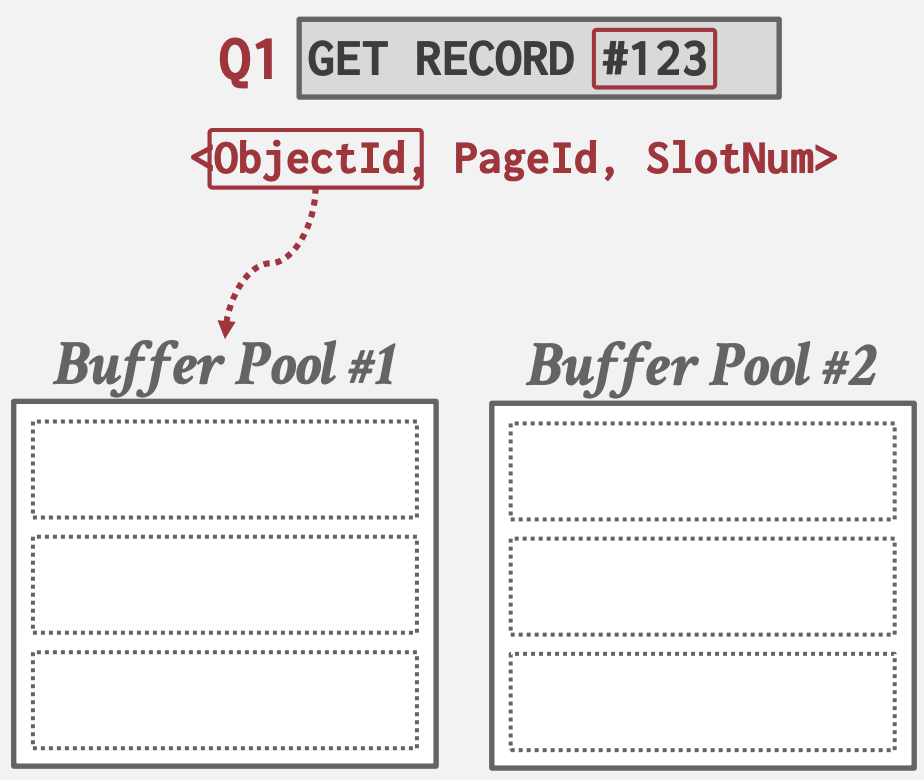
- Hash: 对PageID进行哈希以选择Buffer Pool。
Pre-fetching
通过基于查询计划, 进行Page预取来进行优化:
- 在处理第一组Page时,预取第二组Page
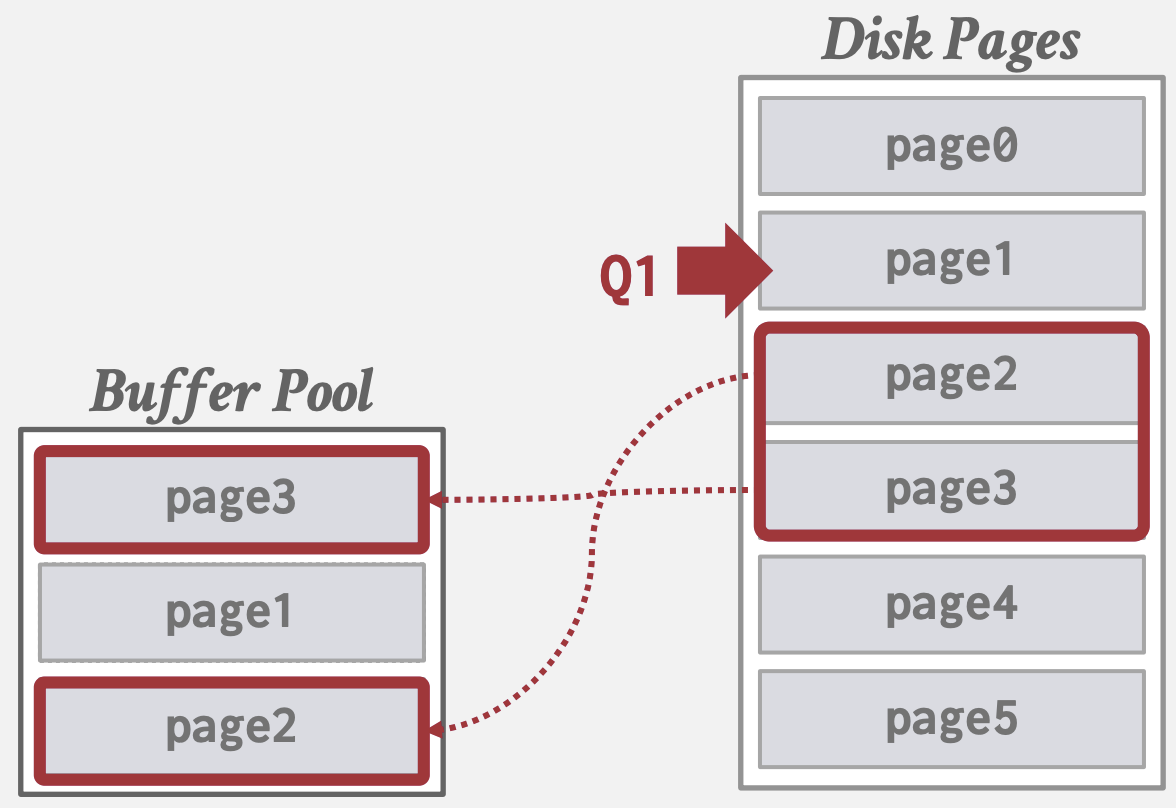
- 根据树索引预取叶子Page
SELECT * FROM A
WHERE val BETWEEN 100 AND 250
Scan Sharing (Synchronized Scans)
查询游标可以重用从存储中检索的数据, 或完成计算的操作数据:
- 允许多个查询连接到扫描表的单个游标
- 如果一个新查询将开始扫描表,发现存在现有查询正在执行此操作,那么DBMS会将新查询的游标连接到现有游标。DBMS跟踪新查询加入现有查询时的位置,以便在到达数据结构末尾时继续完成扫描。
Buffer Pool Bypass
不将顺序扫描操作获取的Page存储到Buffer Pool中以避免污染, 因为这些页面再次命中率低:
- 使用本查询的本地内存
- 也会用于需要存储临时数据的操作, 如sorting, joins
例子: Informix的Light Scans
替换策略
在需要内存空间时决定从Buffer Pool中驱逐哪些Page以腾出空间。
目标
- 正确性: 还未使用完成的page不能被淘汰
- 准确性: 淘汰的page应该是未来不太会被用到的
- 速度: 算法足够高效
- 元数据开销: 减少内存开销
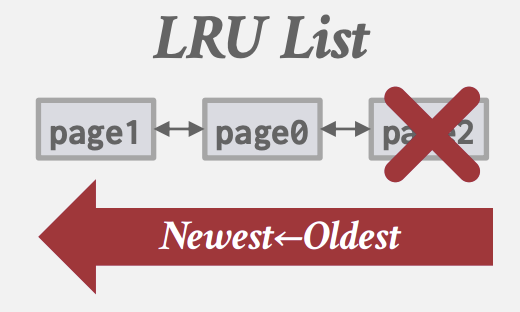
最近最少使用(LRU)
- DBMS选择驱逐具有最旧上次访问时间的Page
- 可以使用list排序, 每次访问取出并重新插入头部
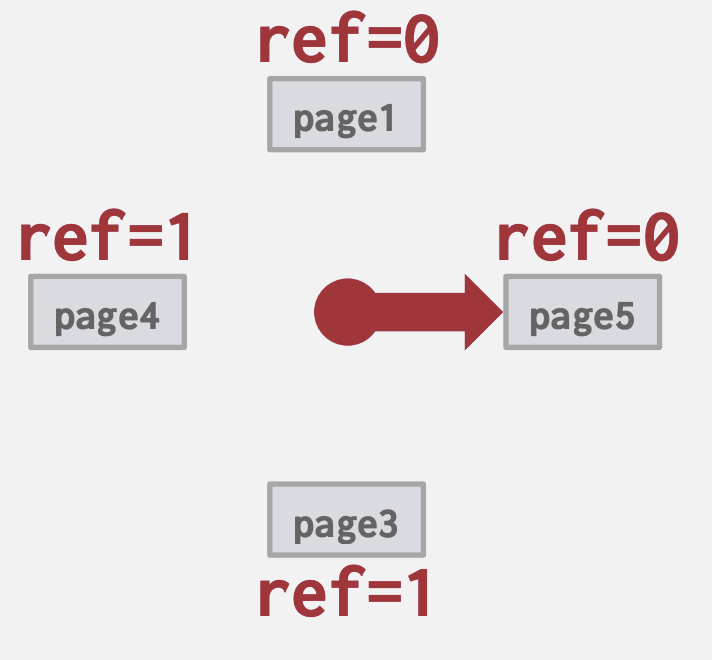
CLOCK
LRU的一种近似, 无需精确地维护Page的访问顺序
- 每个Page都有一个引用位: 当访问Page时,将其设置为1。
- 将Page组织成带有“时钟手”的循环缓冲区
- 在扫描时,检查Page的位是否设置为1。如果是,则将其设置为零;如果不是,则将其淘汰。
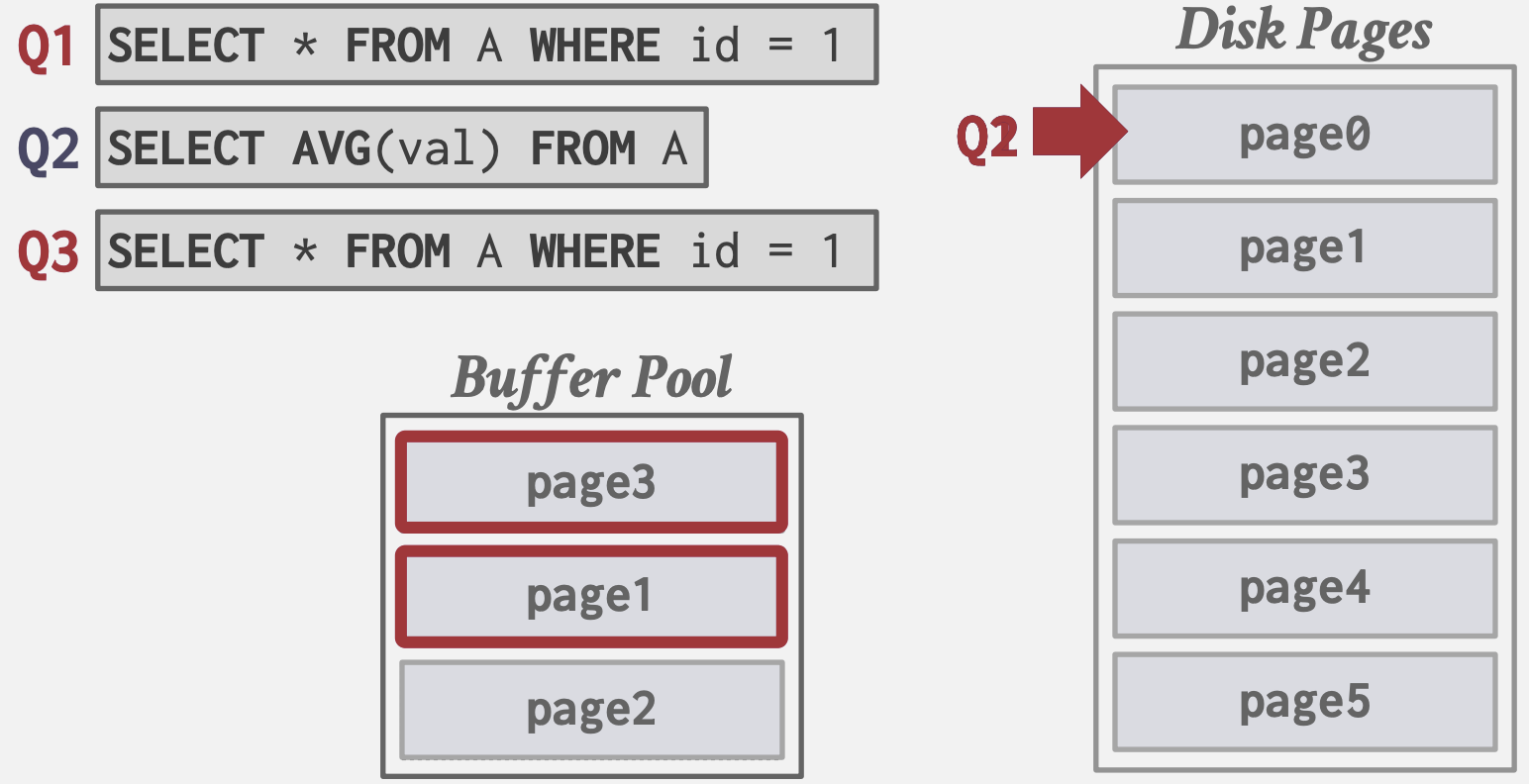
顺序泛洪问题
LRU和CLOCK易受到sequential flooding(顺序泛洪)的影响: 由于顺序扫描而使Buffer Pool的内容受污染, 这些页面再次命中率低。 因为LRU和CLOCK只跟踪上次访问时间, 而不是页面使用的频次
解决方案:
- LRU-K: 跟踪最近K次引用的历史时间戳,并计算连续访问之间的间隔。淘汰掉间隔最大的Page。
MySQL的近似LRU-K:
- 为LRU List维护两个HEAD, Young Head和Old Head, 将List划分为Young List和Old List.
- 新Page先插入Old Head;
- Old List里的Page被再次访问时, 将其插入到Young Head
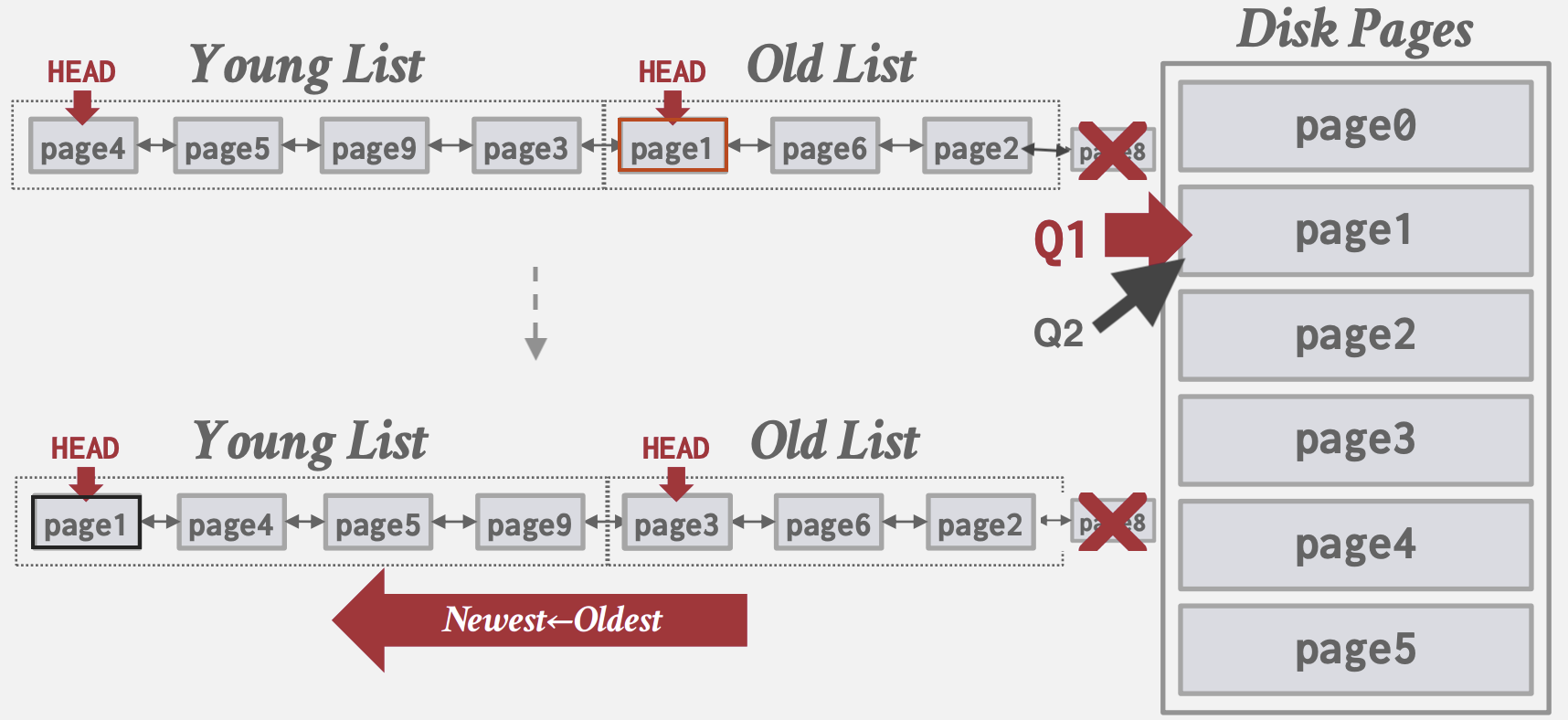
- 查询的本地化: DBMS在每个事务/查询基础上选择淘汰哪些Page。这减少了每个查询对Buffer Pool的污染。
- 优先级提示: 事务根据查询执行的上下文, 告诉Buffer Pool哪些Page是重要/不重要。比如:
- 将tree index的root所在page设置高优先级
- 自增id插入时将覆盖id范围的page设置高优先级
脏页淘汰
处理带有脏标志的Page的方法:
- 最快的方式: 丢弃不带脏标志的任何Page
- 较慢的方式: 将脏页写回磁盘,确保其更改被持久化。
需根据硬件性能权衡: 快速淘汰干净Page, 还是将不会再次读取的脏Page写回。 通过定期后台写入脏页任务可以取消脏标志。
其他内存池
DBMS需要内存来存储除了Tuple和索引之外的其他信息。根据具体实现, 这些内存池可能并不总是需要写入磁盘:
- 排序 + 连接缓冲区
- 查询缓存
- 维护缓冲区
- 日志缓冲区
- 字典缓存
磁盘IO调度
多数DBMS文档推荐将OS调度器设置为Deadline或NOOP(FIFO), 并自己维护内部队列在更高语义上跟踪来自整个系统的页面读写请求, 以优化IO性能。如: Oracle, Vertica, MySQL
任务的优先级取决于多个因素:
- 顺序 vs 随机IO
- 关键任务 vs 后台任务
- 表 vs 索引(有latch故高优先级) vs 日志(尽快写出) vs 临时数据
- 事务信息
- 基于用户的服务水平协议(SLAs)
OS Page Cache
通常系统会维护自身文件页缓存,这会导致一份数据分别在操作系统和 DBMS 中被缓存两次。大多数DBMS都会使用 (O_DIRECT) 来告诉 OS 不要缓存这些数据
DBMS内部数据结构
DBMS在系统内部的许多不同部分使用各种数据结构。比如:
- 内部元数据:这是用于跟踪有关数据库和系统状态的信息的数据。例如: Page Tables, Page Directory
- 核心数据存储:用来存储Tuples的数据结构, 如: 聚簇索引(Hash Tables, B+ Trees)
- 临时数据结构:DBMS可以在处理查询时即时构建临时数据结构,以加快执行速度(例如,连接操作的Hash Tables)
- 表索引:可用于更快地查找特定的Tuples的辅助数据结构
在实现DBMS的数据结构时,有两个主要的设计决策需要考虑:
- 数据组织:我们需要确定如何布局内存以及在数据结构内存储哪些信息,以支持高效的访问
- 并发性:我们还需要考虑如何支持多个线程访问数据结构而不引起问题,确保数据保持正确和可靠
Hash Tables
哈希表: 将键映射到值的无序数组
- 时间复杂度: 平均 O(1) , 最坏 O(n)。在实际应用中需考虑常数因子的优化
- 空间复杂度: O(n)
哈希表的实现包括两个部分:
- 哈希函数:如何将一个大的键空间映射到较小的域。它用于计算数组桶或槽的索引。需要权衡: 快速执行 vs 冲突率。在一个极端情况下,有一个始终返回常数的哈希函数(非常快,但存在冲突)。在另一个极端情况下,有一个“完美”的哈希函数,没有冲突,但计算时间极长。理想的设计通常位于两者之间。
- 哈希方案:在哈希后如何处理键冲突。需要权衡: 分配一个大的哈希表以减少冲突 vs 在发生冲突时执行额外指令
哈希函数
哈希函数接受任何键作为输入,返回该键的整数表示。该函数的输出是确定性的(即,相同的键应始终生成相同的哈希输出)。 DBMS关注哈希函数的速度和冲突率, 比较好的选择是Facebook XXHash3
静态哈希方案
一种哈希表大小固定的方案。这意味着如果DBMS在哈希表中的存储空间用尽,那么它必须从头开始重新构建一个更大的哈希表,这是非常昂贵的。通常,新的哈希表的大小是原始哈希表大小的两倍。 为了减少不必要的比较次数,避免哈希键的冲突是很重要的。通常,我们使用预期元素数量的两倍作为槽位的数量。 通常以下假设在现实中不成立:
- 元素数量是预先已知的。
- 键是唯一的。
- 存在一个完美的哈希函数。 因此,我们需要适当选择哈希函数和哈希方案。
线性探测哈希
使用一个循环数组槽。插入发生冲突时,我们线性搜索相邻的槽,直到找到一个空槽。 对于查找操作,我们可以检查键散列到的槽,并线性搜索直到找到所需的条目。如果我们达到了一个空槽或者遍历了哈希表中的每个槽,那么该键不在表中。这意味着我们必须在槽中存储键和值,以便我们可以检查条目是否是所需的条目。 删除操作更加棘手,因为这可能会导致之后无法找到被删条目后面的条目。解决方法:
- 最常见的方法是使用“墓碑”。不删除条目,而是将其替换为一个“墓碑”条目,提示未来的查找继续扫描。
- 在删除条目后移动相邻的数据以填充现在的空槽(但要保证后续线性探测操作能正常找到)。对相邻键重新进行哈希直到找到第一个空槽, 将该键移动到该空槽。由于在键很多的情况下这样做非常昂贵,实际中很少这样实现
处理非唯一键
在同一个键可能与多个不同值或Tuple关联的情况下,有两种实现方式:
- 链表:不将值与键一起存储,而是存储一个指向包含所有值的链表的单独存储区的指针,该链表可能溢出到多个页面
- 冗余键:更常见的方法是在表中简单地多次存储相同的键。不会影响线性探测的所有操作
优化技巧
实现中有如下优化技巧(参考ClickHouse):
- 基于键的数据类型或大小的选用专门的哈希表实现,以优化存储数据、执行拆分等方面。例如,对于字符串键,我们可以将较小的字符串存储在原始哈希表中,而对于较大的字符串仅存储指针或哈希值。
- 存储额外的元数据:例如将空槽/墓碑信息打包成位图存储到页面头部,或者存储到另外的哈希表中,这将帮助避免查找已删除的键。
- 为 Table 和 Slot 维护版本元数据:由于为哈希表分配内存是昂贵的,我们可能希望复用内存。但为了清除旧表中的条目,我们可以增加Table的版本计数器。如果槽的版本与表的版本不匹配,可以将该槽视为空。而无需逐项标记每个槽为删除/空
Google 的 absl::flat_hash_map 是线性探测哈希的优秀实现。
布谷鸟哈希
使用多个哈希函数(或种子值)来计算记录的槽位。
名字源于布谷鸟在别的鸟巢中下蛋,并将别的鸟蛋挤出的行为。
在插入时,我们使用不同的哈希函数(或种子值)来寻找空槽。如果所有槽位都满,我们选择(通常是随机的)并驱逐旧条目。然后,我们将旧条目重新哈希到不同槽位的中。在罕见的情况下,我们可能会陷入循环。如果发生这种情况,我们可以使用新的哈希函数(或种子值)重建哈希表(较少见)或者使用更大的表重建哈希表(更常见)。 布谷鸟哈希保证 O(1) 的查找和删除,但插入可能更昂贵。
可以参考libcuckoo的实现
动态哈希方案
静态哈希方案要求DBMS预设要存储的元素数量。否则,如果需要调整大小,就必须重新构建表。 动态哈希方案能够根据需要调整哈希表的大小,而无需重新构建整个表。
链式哈希
这是最常见的动态哈希方案。DBMS为哈希表中的每个槽维护一个桶的链表。哈希到相同槽的键被简单地插入到该槽的链表中。 要查找一个元素,我们哈希到其桶,然后扫描查找。通过在桶指针列表中额外存储布隆过滤器,可以对此进行优化,布隆过滤器告诉我们键是否不存在于链表中,并帮助我们在这种情况下避免查找。
可扩展哈希
链式哈希的改进版本,它在链表无限增长之前对桶进行了分割。 重新平衡:增加哈希掩码位数,并拆分移动哈希掩码后变动了的桶条目,其他桶保持不变。
- DBMS维护掩码位数
- 当桶内已满时,DBMS会将槽数组的大小加倍以容纳新桶,并递增全局掩码位数,DBMS拆分桶并重新排列其元素。
线性哈希
与在溢出时立即扩容拆分桶不同(需对Table Latch),这个方案维护一个分裂指针,用于跟踪下一个要拆分的桶。
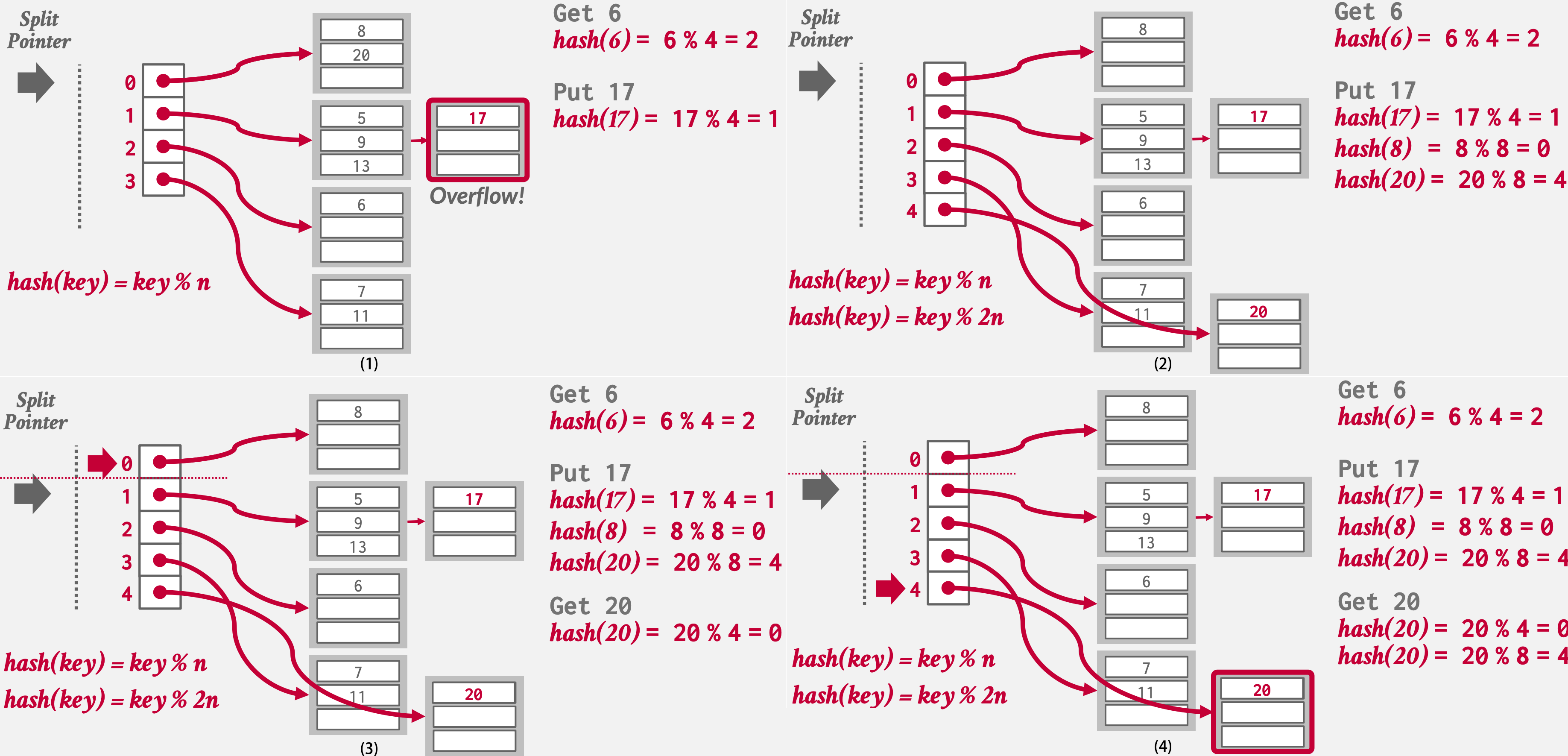
- 任何桶溢出时,在拆分指针所指向的桶(无论该指针是否指向了溢出的桶)。添加一个新的槽存放新桶指针,和一个新的哈希函数,并使用此函数对拆分桶中的键进行重新哈希
- 然后分裂指针移向下一个槽,因此分裂指针之前的槽是被分裂过的
- 插入值时,如果使用原始哈希函数将映射到曾被分裂的槽,需要应用新的哈希函数来确定键的实际位置
- 当指针到达最后一个槽时,删除上轮原始哈希函数并将指针移回到开头
- 如果拆分指针前一个桶为空,我们还可以执行反向操作回收空间:移除该桶并将拆分指针朝相反方向移动。但是这可能会导致反复的分裂和回收(震荡)`
表索引
对于涉及范围扫描查询的表索引,散列表可能不是最佳选项,因为它是无序的。
表索引是表的一部分属性的副本,经过组织和/或排序以便使用其中一部分属性进行高效访问
- DBMS可以通过在表索引上进行查找来更快地找到特定的Tuple,避免执行顺序扫描
- DBMS确保表和索引的内容始终在逻辑上同步
找出执行查询时使用的最佳索引是DBMS的工作(查询优化),数据库中创建索引的数量之间存在权衡:
- 尽管创建更多的索引可以加快查询速度,但索引也会使用存储空间并需要维护
- 需维护索引同步, 会涉及相关并发问题
B+树
B+树是一种自平衡树数据结构,用于保持数据排序,并允许在O(log(n))时间内进行搜索、顺序访问、插入和删除。
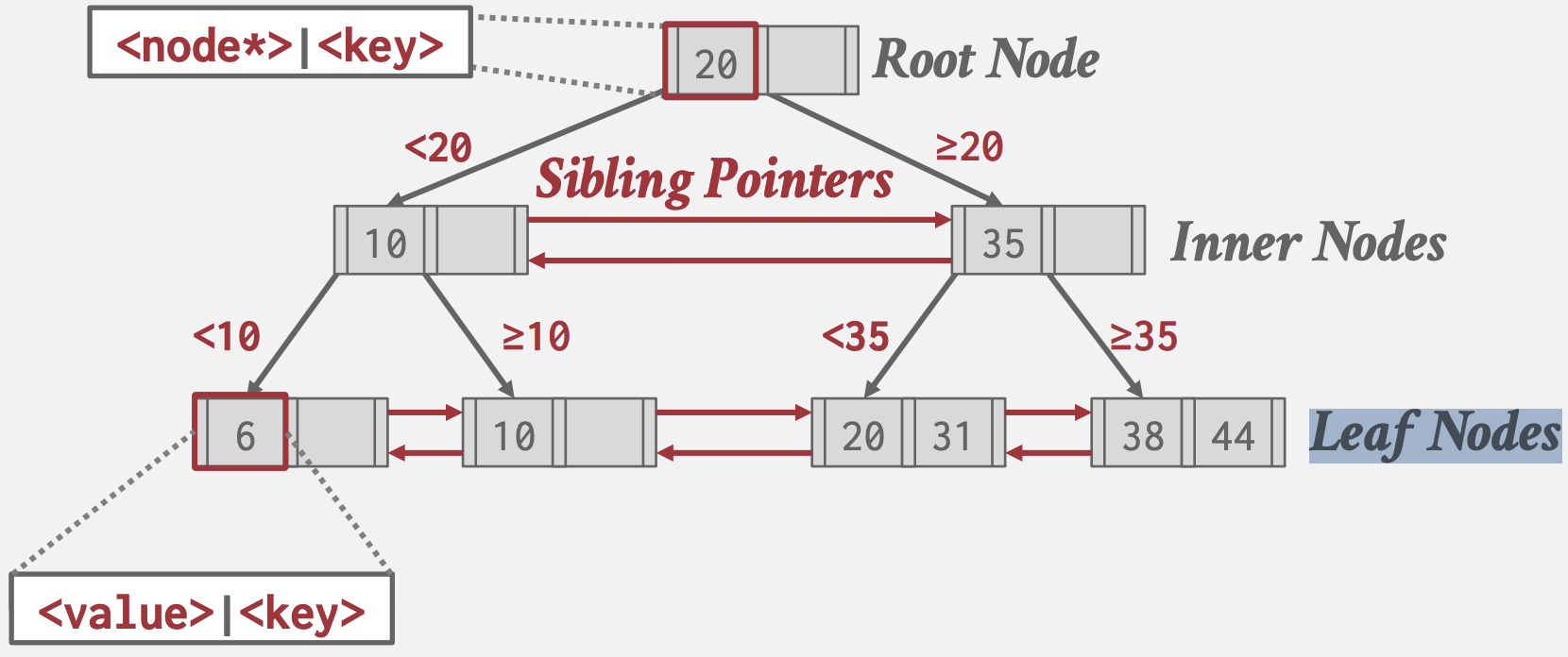
它针对读/写大块数据的面向磁盘的DBMS进行了优化:
- 原始B树在所有节点中存储键和值,而B+树仅在叶子节点中存储值,从而增加每Page存储的节点数
- 现代B+树实现结合了Blink-Tree中使用的兄弟指针(Sibling Pointers),以支持在叶子结点间顺序遍历
- B树的每个key只在树中出现一次,空间更小;但在多线程更新时代价比B+树高,因为B+树更新时如过未破坏平衡则无需上下传播更新其它内部节点
B+树是一棵M路搜索树,具有以下特性:
- 完美平衡(即每个叶子节点都在相同的深度)。
- 除根之外的每个内部节点半满(M/2 − 1 <= 键的数量 <= M − 1)。
- 每个具有k个键的内部节点具有k+1个非空子节点。
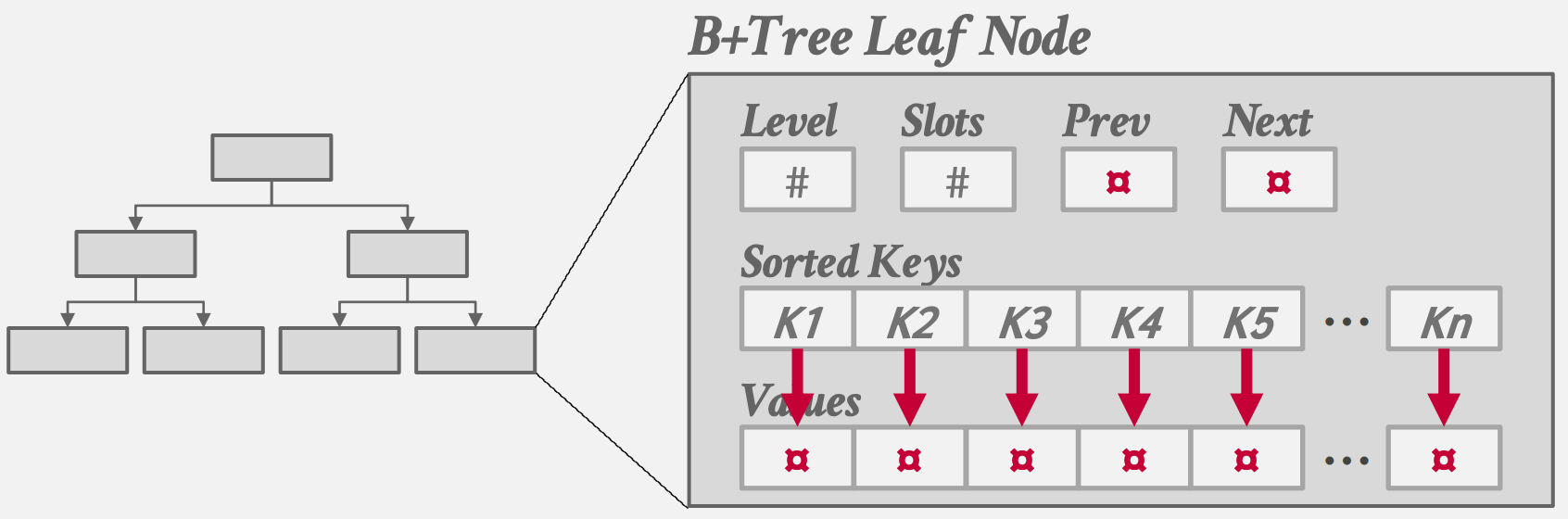
B+树中的每个节点都包含一个键/值对的数组:
- 对于叶子节点,键来自索引所基于的属性。尽管根据B+树的定义,每个节点上的数组并不一定需要按键排序,但实际上,几乎总是按键排序的。叶子节点值的两种方法是记录ID和Tuple数据。记录ID指向Tuple的位置,通常是主键。具有Tuple数据的叶子节点在每个节点中存储Tuple的实际内容。
- 对于内部节点,值包含指向其他节点的指针,键可以看作是导航标志。它们指导树的遍历,但不代表叶子节点上的键(因此也不代表它们的值)。这意味着你可能在内部节点中有一个在叶子节点上找不到的键(导航标志),尽管传统上内部节点仅包含在叶子节点中存在的键。
- 实现中通常拆分建和值的数组,以提高空间局部性和缓存命中率
- 根据索引类型(NULL首位还是NULL末位),空键将聚集在第一个叶子节点或最后一个叶子节点。
插入
可视化演示: https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
- 找到正确的叶子节点L。
- 按顺序在L中添加新条目:
- 如果L有足够的空间,则操作完成。
- 否则将L分裂为两个节点L和新节点L2。均匀地重新分配条目并将中间键复制到上层。在L的父节点中插入一个指向L2的条目。
- 要分裂内部节点,均匀地重新分配条目,并将中间键向上传播。
删除
- 找到正确的叶子节点L。
- 删除条目:
- 如果L至少半满,则操作完成。
- 否则,可以尝试重新分配,从兄弟节点借用。
- 如果重新分配失败,则合并L和兄弟节点。
- 如果发生了合并,必须删除指向L的父节点中的条目。
选择条件
如果查询提供搜索键中的若干属性值,DBMS可以使用B+树索引加速查找。而哈希索引要求提供搜索键中的所有属性。
比如建立属性<a,b>的索引,则以下查询可以利用该索引
- 完整匹配:
(a=1 AND b=2)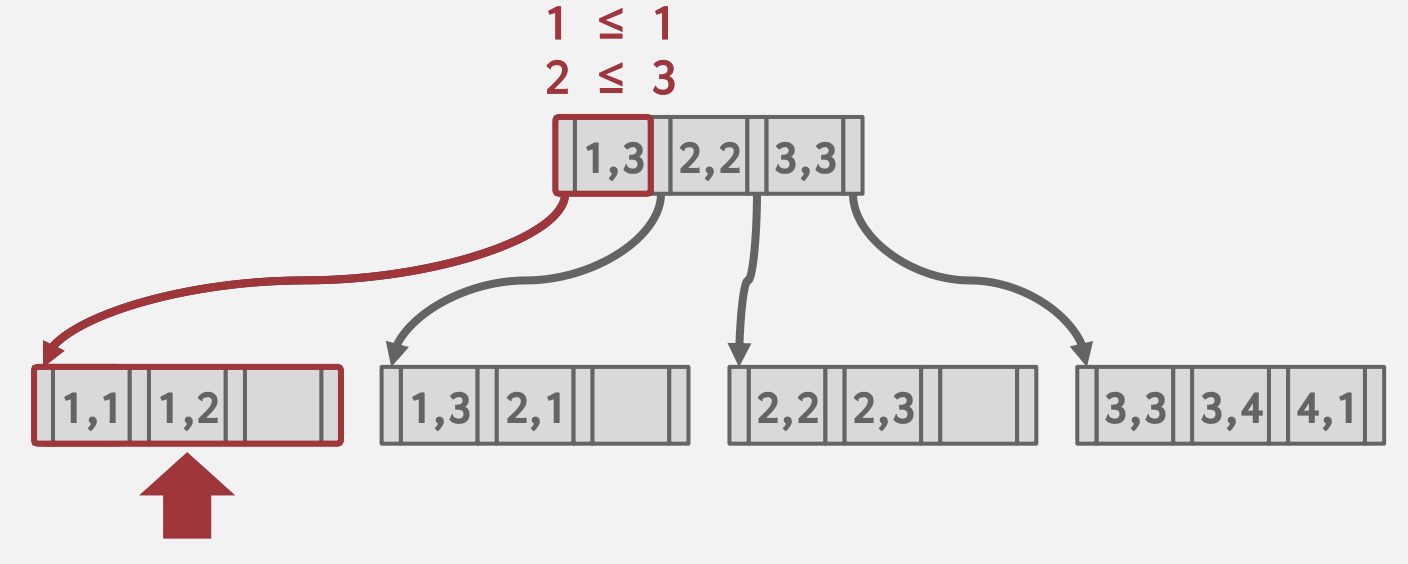
- 前缀匹配:
(a=1)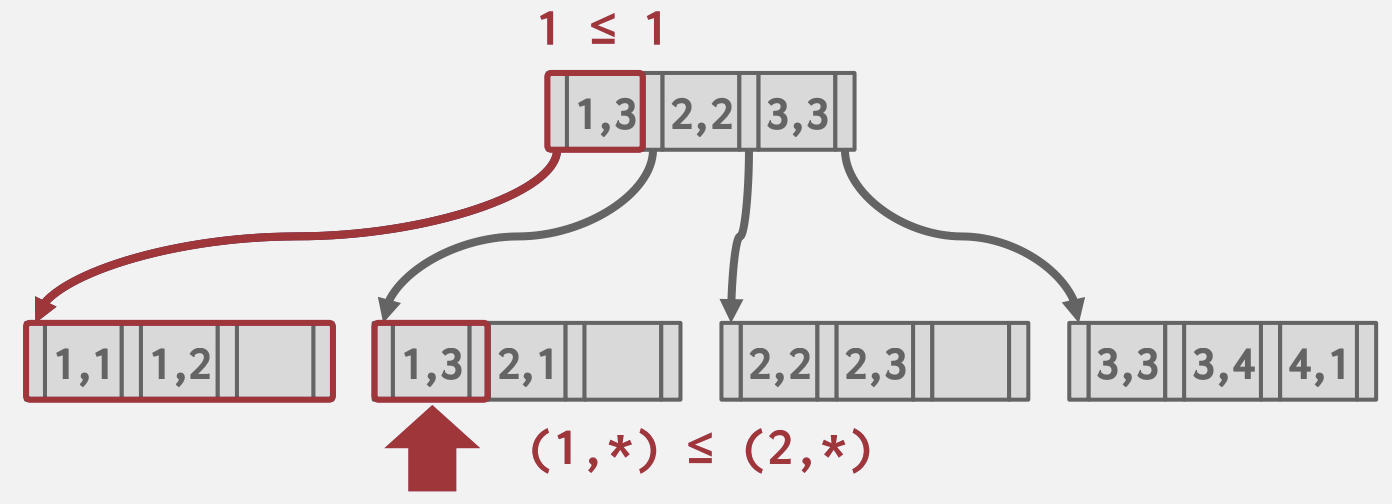
- Skip Scan:
(b=1)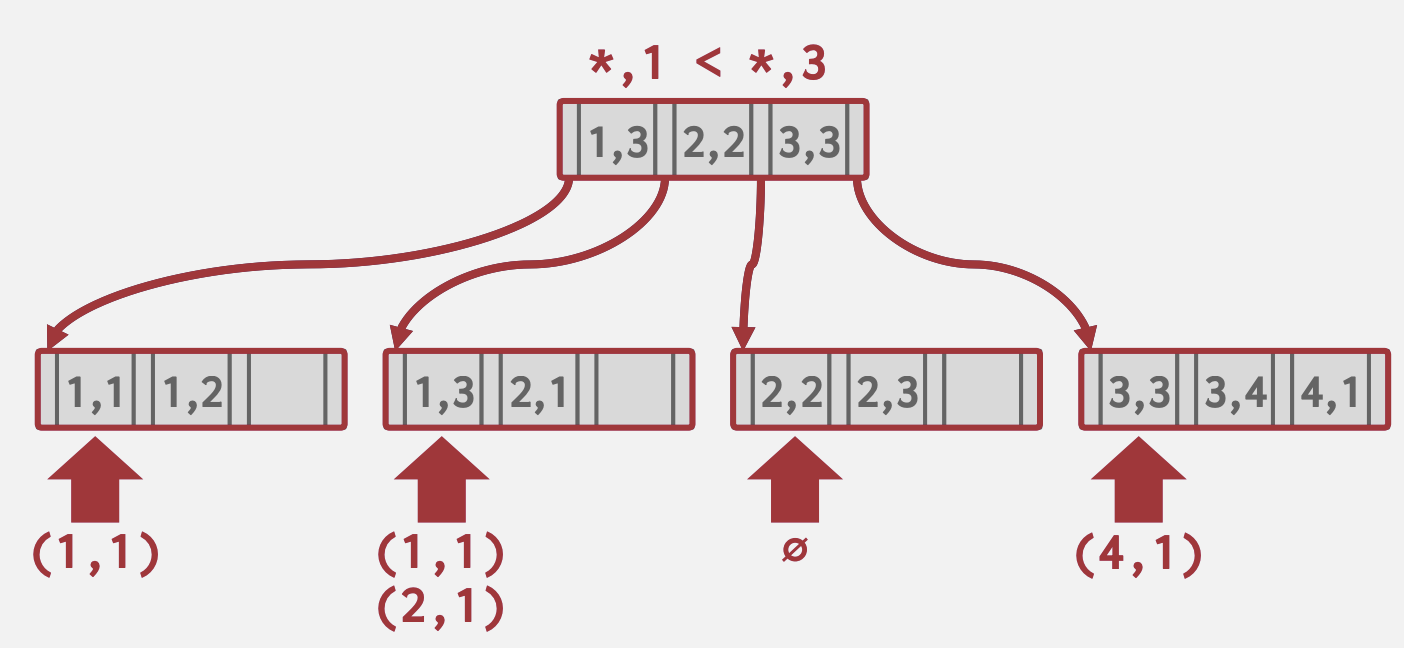 在内部节点评估需要扫描的部分(a=1,b=1;a=2,b=1;a=3,b=1…),然后多线程分散扫描,然后将结果组合到一起,如Oracle和MySQL
在内部节点评估需要扫描的部分(a=1,b=1;a=2,b=1;a=3,b=1…),然后多线程分散扫描,然后将结果组合到一起,如Oracle和MySQL
但不是所有DBMS都能完整支持。
重复键
为了支持在B+树中添加重复的key,有以下方法:
- 将Record ID附加为key的一部分。由于每个Tuple的Record ID是唯一的,这将确保所有键都不重复。
- 允许叶子节点添加溢出节点,溢出节点存放重复key。虽然没有存储冗余信息,但这种方法在维护和修改方面更为复杂。
聚簇索引
TODO 表按照主键指定的排序顺序进行存储,可以是堆存储或索引组织存储。 由于某些DBMS总是使用聚簇索引,如果表没有显式的主键,它们将自动创建一个隐藏的行ID作为主键;而另一些系统可能根本无法使用聚簇索引。
堆聚簇
TODO Tuple在堆的页面中按照由聚簇索引指定的顺序进行排序。如果使用聚簇索引的属性访问Tuple,DBMS可以直接跳转到页面。
索引扫描页面排序
TODO 由于直接从非聚簇索引中检索Tuple是低效的,DBMS可以首先找出所有需要的Tuple,然后根据它们的页面ID进行排序。这样,每个页面只需要被提取一次。
B+树设计选择
节点大小
根据存储介质的不同,会选用不同的节点大小:
- 存储在硬盘上的节点通常以兆字节为单位,以减少查找数据所需的寻址次数,并将昂贵的磁盘读取分摊到大块数据上
- 而内存数据库可能使用小至512字节的页面大小,以将整个页面适应到CPU缓存中,并减少数据碎片化。 这种选择也可能取决于工作负载的类型:
- 因为点查询更希望页面尽可能小,以减少加载不必要的额外信息的量
- 而大型顺序扫描可能更希望大页面以减少需要执行的读取数量。
合并阈值
虽然B+树有关于在删除后合并不足半满节点的规则,但实际实现违反规则可能有益,能减少调整操作次数:
- 急切地合并可能导致”抖动”,其中大量连续的删除和插入操作导致不断的拆分和合并。
- 允许批量合并,其中多个合并操作一次执行,减少树上需要进行的昂贵写锁的时间。 有一种合并策略会保留树中的小节点,并稍后重建它,使得树不平衡(如Postgres中的情况)TODO
变长键
目前我们只讨论了具有固定长度键的B+树。然而,我们可能还想支持变长键,例如,大键的小子集导致了大量浪费的空间。有几种处理这种情况的方法:
- 指针 / Record ID 不直接存储键,而是只存储指向键的指针。由于对每个键都要根据指针间接访问的效率较低,实际生产中只有嵌入式设备使用这种方法以节省空间。
- 变长节点 将节点设计为支持变长大小。由于处理变长节点的内存管理开销很大,这通常是不可行的。
- 填充 将每个键的大小设置为最大键的大小,并填充所有较短的键。这是对内存的巨大浪费,故没有人使用这种方法。
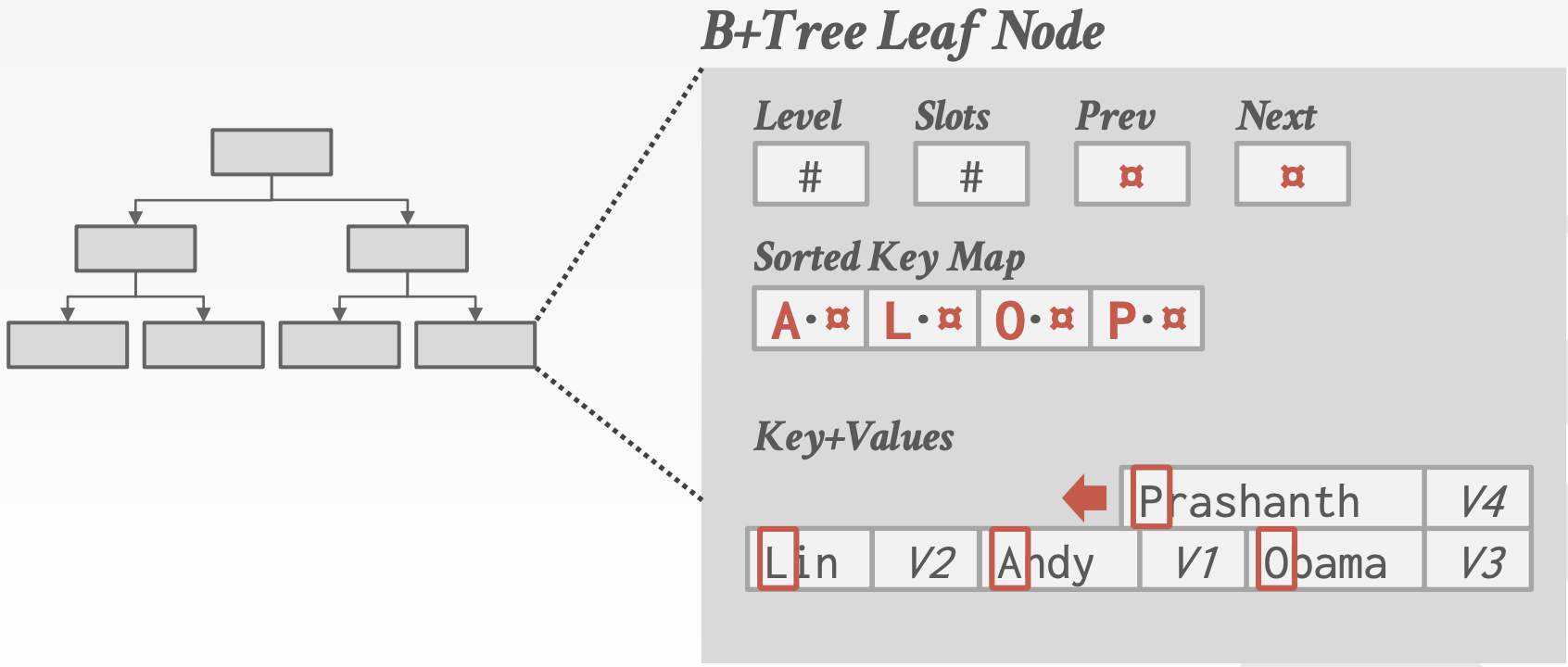
- 键映射 / 间接映射
节点内维护映射字典,内容为原键的前缀 + 指向键值数据的指针。这是最常用的方法,节省空间,并且可能快捷地执行点查询(因为索引指向的键-值对与叶子节点指向的完全相同)。还允许某些索引搜索和叶子扫描甚至无需追踪指针(如果前缀与搜索键已经不匹配)。
节点内搜索
找到一个节点后,还需要在节点内搜索(无论是从内部节点找到下一个节点,还是在叶子节点中找到我们的键值)。这需要考虑一些权衡:
- 线性: 最简单的解决方案是扫描节点中的每个键,直到找到我们的键。
- +无无需对键进行排序,从而使插入和删除更加迅速。
- -相对低效,每次搜索O(n)的复杂度。可以使用 SIMD(或等效)指令对其进行矢量化。
 使用SMID指令进行矢量化线型查找: _mm_cmpeq_epi32_mask
使用SMID指令进行矢量化线型查找: _mm_cmpeq_epi32_mask
- 二分:
用于搜索的更有效解决方案是保持每个节点排序,并使用二分搜索找到键。
- +搜索效率更高,每次搜索O(ln(n))的复杂度。
- -必须维护每个节点的排序,插入变得更加昂贵。
- 插值: 在某些情况下,我们可能能够利用插值来找到键。这种方法需将节点键的分布信息存储为元数据(例如最大元素,最小元素,平均值等),并使用它估计键的近似位置。
例如,如果我们正在查找一个节点中的8,并且我们知道10是最大键,10 - (n + 1)是最小键(其中n是每个节点中的键数),那么我们知道可以从最大键前第2个插槽开始向前搜索,因为在这种情况下,离最大键一个插槽的键必须是9。
- +最快的方法
- -由于其对具有某些属性的键(如整数)和复杂性的适用性有限,这种方法仅在学术数据库中可见。TODO
优化
指针交换
因为B+Tree的每个节点都存储在Buffer Pool的Page中,每次加载新Page时,我们需要从Buffer Pool中获取它,这需要latching和查找。 为了跳过这一步,我们可以用原始指针代替Page ID(称为”swizzling”)。可以趁着正常遍历索引时,从Page查找结果获取原始指针并替换Page ID。 请注意,我们必须持续跟踪哪些指针已经进行了”swizzle”和”deswizzle”,并在它们指向的Page被unpinned和淘汰时将它们反向转换回Page ID。 这对于靠近root的结点很有用。
批量插入
当首次构建B+Tree时,使用通常的方式插入每个键将导致不断的分割操作。由于我们已经给予叶子节点兄弟指针,因此如果我们构建一个叶子节点的排序链表,然后使用每个叶子节点的第一个键轻松地从下向上构建索引,那么初始插入数据的效率将更高。请注意,根据我们的上下文,我们可能希望尽可能紧密地打包叶子节点以节省空间,或者在每个叶子节点中留出空间,以允许在需要分割之前插入更多数据。
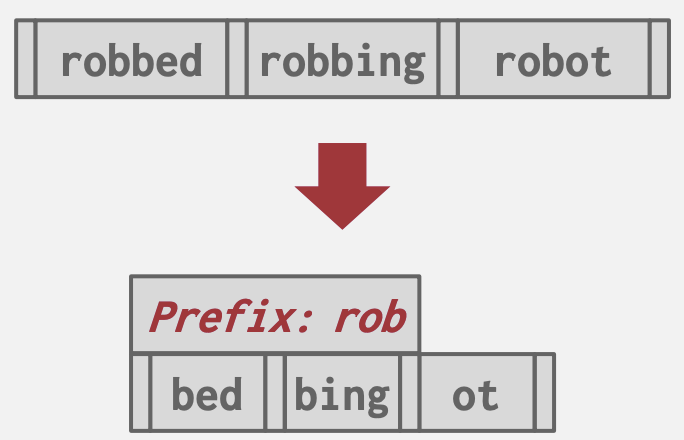
前缀压缩
当在同一节点中具有相同前缀的键时,通常会存在某些键的部分重叠(因为相似的键在B+Tree中排序后会相邻排列)。我们可以通过将前缀存储到节点开头,然后只在每个插槽中包含每个键的唯一部分来避免多次存储相同前缀。
重复消除
在允许非唯一键的索引的情况下,我们可能会发现叶子节点反复包含相同的键,但附有不同的值。对此的一个优化可能是只写入键一次,然后跟随其所有关联的值。
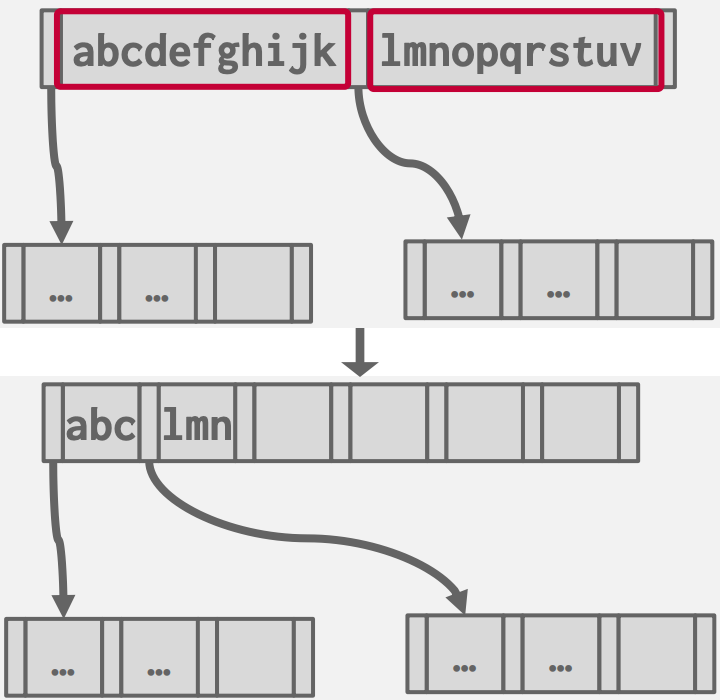
后缀截断
在大多数情况下,内部节点中的键仅用作导航标志,而非其实际数据键值(即使键存在于索引中,我们仍然必须搜索至叶子结点以确保它没有被删除)。因此在内部节点无需存储完整键,只存储足够正确路由到正确叶子节点所需的最小前缀。
优化写入的B+树
分割/合并节点操作很昂贵。因此,一些B-Tree的变体,例如Bϵ-Tree,在内部节点中记录更改,并延迟将更新传播到叶节点。
索引并发控制
索引并发控制
到目前为止,我们假设我们讨论的数据结构是单线程的。然而,大多数DBMS需要允许多个线程安全地访问数据结构,以利用额外的CPU核心并隐藏磁盘I/O延迟。
有些系统使用单线程模型。将单线程数据结构转换为多线程的一种简单方法是使用read-write lock,但这并不高效。
并发控制协议是DBMS用来确保对共享对象的并发操作得到“正确”结果的方法。
协议的正确性标准可能有所不同:
- 逻辑正确性:这意味着线程能够读取它应该期望读取的值,例如,线程应该能够读取它之前写入的值。
- 物理正确性:这意味着对象的内部表示是健全的,例如,数据结构中没有指针会导致线程读取无效的内存位置。
本讲只关心强制执行物理正确性。我们将在后续讨论逻辑正确性。
Locks vs Latches
在讨论DBMS如何保护其内部元素时,Locks和Latches之间有一个重要的区别。
Locks
Locks是一种高级的逻辑原语,它保护数据库内容(例如,元组、表、数据库)免受其他事务的干扰。事务在其整个持续时间内都会持有Locks。数据库系统可以向用户展示正在运行的查询所持有的Locks。应该有一些高级机制来检测死锁并回滚更改。
Latches
Latches是用于保护DBMS内部数据结构(例如,数据结构、内存区域)的低级保护原语。Latches在数据库系统中用于简单操作(如: page latch)时仅持有很短的时间。Latches有两种模式:
- 读:允许多个线程同时读取同一个项目。即使另一个线程已经以读模式获取了Latches,线程也可以获取读模式的Latches。
- 写:只允许一个线程访问项目。如果另一个线程以任何模式持有Latches,线程无法获取写Latches。持有写Latches的线程也会阻止其他线程获取读Latches。
Latches的实现
Latches的实现应该具有较小的内存占用,并且在没有竞争时可能有快速路径来获取Latches。 用于实现Latches的基本原语是通过现代CPU提供的原子指令。通过这些指令,线程可以检查内存位置的内容,以确定它是否具有某个值。
在DBMS中有几种实现Latches的方法。每种方法在工程复杂性和运行时性能方面都有不同的权衡。这些测试和设置步骤是原子执行的(即,在测试和设置步骤之间,没有其他线程可以更新值)。
Test-and-Set Spin Latch(TAS)
Spin Latch是操作系统mutex的更有效替代方案,因为它由DBMS控制。Spin Latch本质上是线程尝试更新的内存位置(例如,将布尔值设置为true)。线程执行CAS操作,尝试更新内存位置。DBMS可以控制无法获取Latches时的行为。它可以选择再次尝试(例如,使用while循环),或允许操作系统将其取消调度。因此,这种方法比操作系统mutex给了DBMS更多的控制,因为在无法获取Latches时,后者的控制权交给了操作系统。
- 示例:std::atomic
- 优点:latch/unlatch操作效率高(在x86上只需单指令)。
- 缺点:不可扩展且对缓存不友好,因为多个线程会在不同线程中多次执行CAS指令。这些浪费的指令会在高竞争环境中累积;线程在操作系统看来很忙,尽管它们没有进行有用的工作。这会导致缓存一致性问题,因为线程在其他CPU上轮询缓存行。
Blocking OS Mutex
Latches的一种可能实现是操作系统内置的mutex基础设施。Linux提供了futex(fast user-space mutex),它由(1)用户空间的Spin Latch和(2)操作系统级别的mutex组成。如果DBMS能够获取用户空间latch,那么latch就会被设置。即使它包含两个内部latches,对DBMS来说它看起来像是一个单一的latch。如果DBMS无法获取用户空间latch,那么它会进入内核并尝试获取更昂贵的mutex。如果DBMS无法获取这个第二个mutex,那么线程会通知操作系统它被阻塞在mutex上,然后它会被取消调度。
操作系统mutex通常在DBMS内部不是个好主意,因为它由操作系统管理,并且开销很大。
- 示例:std::mutex
- 优点:使用简单,不需要在DBMS中进行额外编码。
- 缺点:昂贵且不可扩展(每次latch/unlatch调用大约25纳秒),因为操作系统调度。
Reader-Writer Latches
Mutex和Spin Latch不区分读/写(即,它们不支持不同模式)。DBMS需要一种方法来允许并发读取,这样在应用程序读取量很大时,性能会更好,因为读操作可以共享资源,而不是等待。
Reader-Writer Latches允许Latches以读或写模式持有。它跟踪每种模式下持有Latches的线程数量以及等待获取每种模式Latches的线程数量。不同的DBMS可以有不同的策略来处理队列。
值得注意的是,不同的实现有不同的等待策略。有读操作优先、写操作优先和公平的Reader-Writer Latches。在不同的操作系统和pthread实现中,行为有所不同。
- 示例:std::shared_mutex
- 优点:允许并发读取。
- 缺点:DBMS必须管理读写队列以避免饥饿。由于额外的元数据,存储开销比Spin Latch大。
Hash Table Latching
由于线程访问数据结构的方式有限,因此在静态哈希表中支持并发访问是容易的。例如,当从一个Slot移动到下一个Slot时,所有线程都以相同的方向移动(即自顶向下)。线程也一次只访问一个Page/Slot。因此,在这种情况下不可能发生死锁,因为不可能有两个线程竞争对方持有的Latches。当我们需要调整表大小时,我们只需对整个表获取一个全局Latches来进行操作。
在动态哈希方案(如可扩展哈希)中,Latches的实现更为复杂,因为有更多共享状态需要更新,但总体方法相同。
支持哈希表Latches的两种方法在粒度上分为:
-
Page Latches: 每个Page都有自己的读写Latches,保护其全部内容。线程在访问Page之前获取读或写Latches。这降低了并行性,因为可能一次只有一个线程可以访问Page,但对于单个线程来说,访问Page中的多个Slot将非常快速,因为它只需要获取一个Latches。
-
Slot Latches: 每个Slot都有自己的Latches。这增加了并行性,因为两个线程可以在同一Page上访问不同的Slot。但它增加了存储和计算开销,因为线程必须为它们访问的每个Slot获取Latches,每个Slot都必须存储Latches数据。DBMS可以使用单模式Latches(即,Spin Latch)来减少元数据和计算开销,代价是牺牲一些并行性。
还可以直接使用CAS指令创建一个无Latches的线性探测哈希表。通过尝试将特殊“空”值与我们希望插入的元组进行比较和交换,可以在Slot中插入。如果失败,我们可以探测下一个Slot,直到成功。
B+树Latches
B+树Latches存的挑战在于防止以下两个问题:
- 线程同时尝试修改节点的内容。
- 一个线程在遍历树的同时,另一个线程正在分裂/合并节点。
Latch crabbing/coupling协议允许多个线程同时访问/修改B+树。基本思想如下:
- 获取父节点的Latches。
- 获取子节点的Latches。
- 如果子节点被认为是“安全的”,则释放父节点的Latches。所谓“安全”的节点是指在更新时不会发生分裂、合并或重新分配的节点。换句话说,节点是“安全”的,如果
- 对于插入:它不是满的。
- 对于删除:它的填充度超过一半。
请注意,读Latches不需要担心“安全”条件。
Basic Latch Crabbing Protocol
- 搜索:从根节点开始向下,重复获取子节点的Latches,然后释放父节点的Latches。
- 插入/删除:从根节点开始向下,根据需要获取X Latches。一旦子节点被latched,检查它是否安全。如果子节点安全,释放所有祖先节点的Latches。
从正确性的角度来看,释放Latches的顺序并不重要。然而,从性能的角度来看,最好释放树中较高位置的Latches,因为它们会阻塞对更多叶子节点的访问。
Improved Latch Crabbing Protocol
Basic Latch Crabbing Protocol的问题在于,事务总是在每次插入/删除操作时获取根节点的独占Latches。这限制了并行性。相反,我们可以假设需要调整大小(即,分裂/合并节点)的情况很少,因此事务可以获取到叶子节点的共享Latches。并使用读Latches和抓取来到达它并进行每个事务都会假设到达目标叶子节点的路径是安全的,验证。如果叶子节点不安全,那么我们就中止并使用Basic Latch Crabbing Protocol重新开始事务。
- 搜索:与之前相同的算法。
- 插入/删除:像搜索一样设置读Latches,到达叶子节点,并在叶子节点上设置写Latches。如果叶子节点不安全,释放所有先前的Latches,并使用Basic Latch Crabbing Protocol重新开始事务。
叶子节点扫描
上述协议中的线程以“自顶向下”的方式获取Latches。这意味着线程只能从当前节点下方的节点获取Latches。如果所需的Latches不可用,线程必须等待直到它变得可用。鉴于此,永远不可能发生死锁。
然而,叶子节点扫描容易受到死锁的影响,因为现在我们有线程同时尝试以两个不同方向获取Latch且其中有独占Latch(例如,线程1尝试删除,线程2进行叶子节点扫描)。索引Latches不支持死锁检测或避免。
因此,程序员处理这个问题的唯一方法是通过编码规范。叶子节点兄弟Latches获取协议必须支持“no-wait”模式。也就是说,B+树代码必须能够处理失败的Latches获取。由于Latches旨在被(相对)短暂持有,如果线程尝试获取叶子节点的Latches,但该Latches不可用,那么它应该快速中止其操作(释放它持有的任何Latches),并重新启动操作。
排序与聚合算法
查询计划
数据库系统将SQL编译成查询计划: 操作符组成的树结构.
- 数据从这棵树的叶子流向根节点,根节点的输出是查询的结果
- 操作符通常是二元的(1-2个子节点)
- 同一个查询计划可以以多种方式执行
SELECT R.id, S.cdate FROM R JOIN S ON R.id = S.id WHERE S.value > 100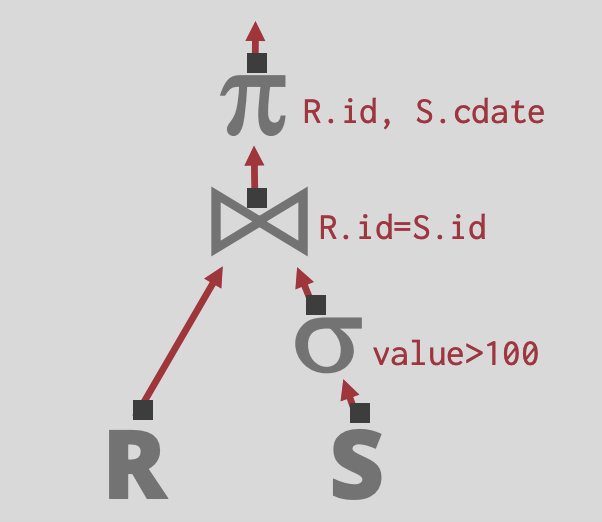
对于面向磁盘的数据库系统,查询结果不一定能完全放在内存中。
- 我们将使用buffer pool来实现需要溢写(spill)到磁盘的算法。
- 我们希望最小化算法的I/O操作, 最大化顺序I/O.
排序
- 在关系模型下,表中的元组无顺序
- 排序可能用于:ORDER BY、GROUP BY(详见聚合)、DISTINCT(消除重复)和JOIN操作符(详见Sort-Merge Join)
- 如果需要排序的数据能够完全装入内存,那么DBMS可以使用标准的排序算法(例如,快速排序)
- 如果数据太大而无法装入内存,那么DBMS需要使用能够按需溢写到磁盘的外部排序,并且优先考虑顺序I/O而不是随机I/O(故快速排序不太合适)
Top-N Heap Sort
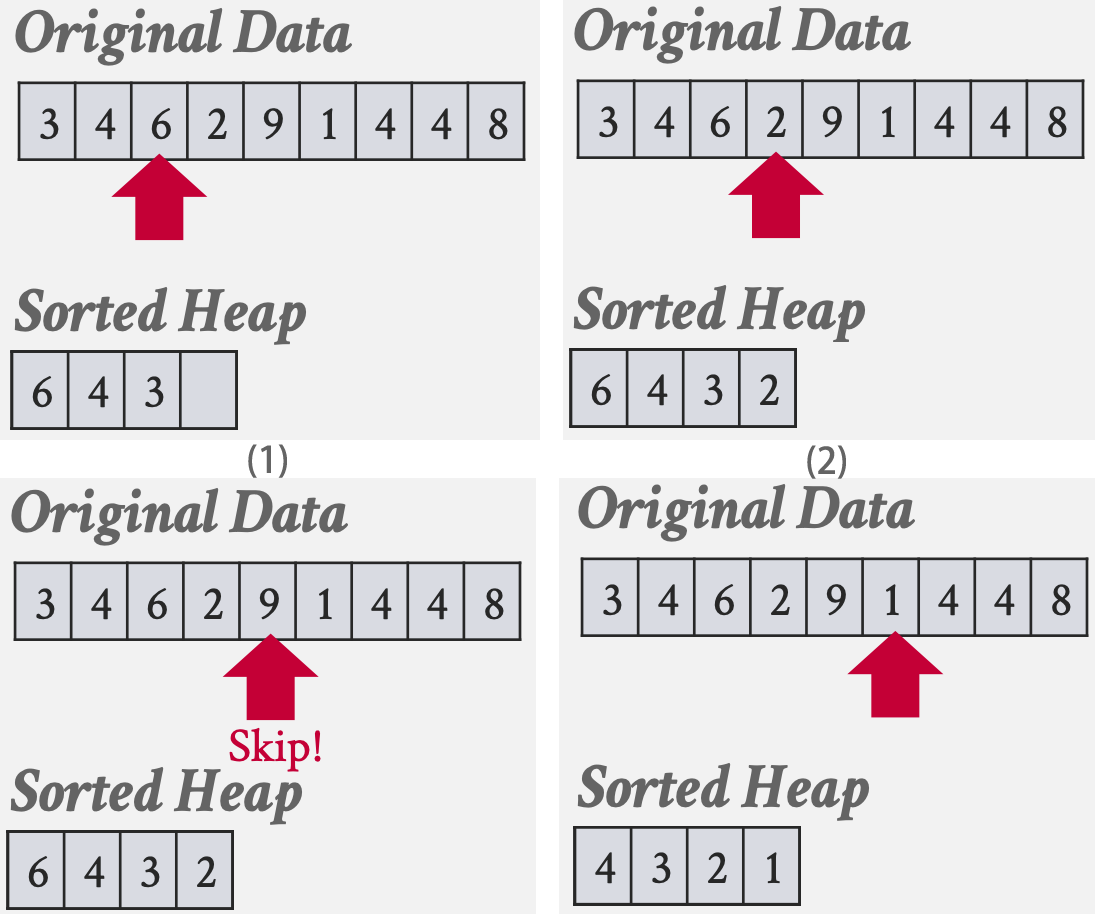
如果查询包含带有LIMIT的ORDER BY,那么DBMS使用堆排序,只需要扫描一次数据就能找到前N个元素。 堆排序的理想情况是当前N个元素都能够装入内存时,这样DBMS只需要在扫描数据时维护一个内存中的排序优先队列(最大/小堆)。
SELECT * FROM enrolled
ORDER BY sid
LIMIT 4
External Merge Sort
对于无法完全装入内存的数据的标准排序算法是外部归并排序。它是一种分治排序算法,将数据集分割成多个独立的归并段(run),然后分别对它们进行排序。它可以按需将归并段(run)溢写(spill)到磁盘,之后逐个将它们读回。该算法由两个阶段组成:
- 阶段#1 – 排序:首先,算法对能够装入主内存的小块数据进行排序,然后将排序后的page写回磁盘。
- 阶段#2 – 合并:然后,算法将排序后的子文件合并成一个更大的单一文件。
对于每个归并段的values, 有两个选择:
- 提前物化(early-materialized),将整个tuple存储到page中
- 延迟物化(late-materialized),我们只在排序归并段中存储记录ID,稍后再读取
Two-way Merge Sort
算法的最基本版本是两路归并排序。
- 排序阶段: 读取每个page(从磁盘或或拷贝已在内存page),对其进行排序,然后将排序后的版本写回磁盘
- 合并阶段: 需使用三个buffer pool page。它从磁盘读取两个排序page,并将它们合并到第三个page中。每当第三个page填满时,它就会被写回磁盘,并用一个空page替换。DBMS通常提供配置page大小选项(排序内存/工作内存)
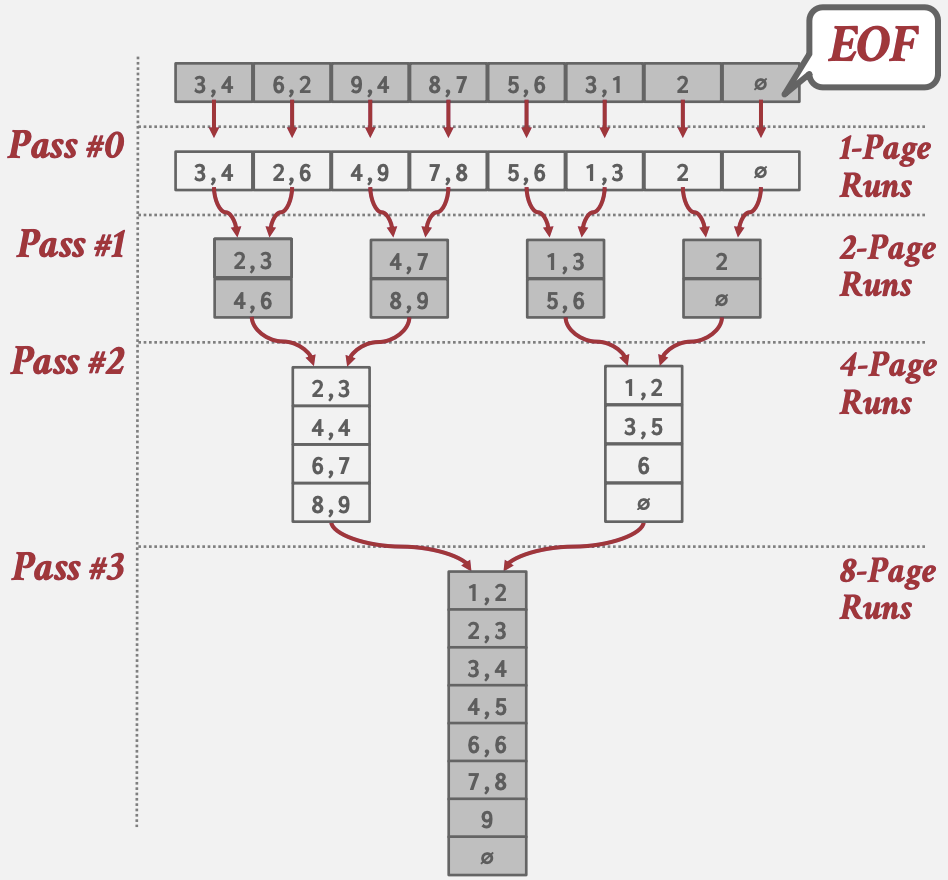 如果N是数据page的总数,该算法总共进行$1 + ⌈\log_2 N⌉$次数据遍历(第一次用于排序阶段,然后是$⌈\log_2 N⌉$次用于递归合并阶段)。
总的I/O成本是2N × (遍历次数),因为每次遍历都需要对每个page进行一次I/O读取和一次I/O写回。
如果N是数据page的总数,该算法总共进行$1 + ⌈\log_2 N⌉$次数据遍历(第一次用于排序阶段,然后是$⌈\log_2 N⌉$次用于递归合并阶段)。
总的I/O成本是2N × (遍历次数),因为每次遍历都需要对每个page进行一次I/O读取和一次I/O写回。
General (K-way) Merge Sort
算法的泛化版本允许DBMS利用多于三个buffer pool page。 设B是可用的page总数,在排序阶段,算法可以一次读取B个page,并将⌈N/B⌉个排序归并段写回磁盘。合并阶段也可以每次合并多达B-1个归并段,同样使用一个page来合并数据,并根据需要写回磁盘。
在泛化版本中,算法执行$1 + ⌈\log_B−1 ⌈N/B⌉⌉$次遍历(一次用于排序阶段,$\log_B−1 ⌈N/B⌉$次用于合并阶段)。 总的I/O成本是2N × (遍历次数),因为它在每次遍历中都需要对每个page进行一次读取和写回。
双缓冲优化
外部归并排序的一个优化是预取下一个归并段并在后台存储到第二个缓冲区中,同时系统处理当前归并段。 这通过持续利用磁盘减少了每个步骤的I/O请求等待时间。这种优化需要使用多线程,因为预取应该在当前归并段的计算发生时进行。
比较优化
代码特化(Code Specialization)经常用于加速排序比较。区别于将比较器作为函数指针提供给排序算法,可以将比较逻辑硬编码到特定键类型的排序方法,节省指针和函数调用等开销。C++中的模板特化就是一个例子。
另一种优化(针对基于字符串的比较)是后缀截断。对于长VARCHAR键,先尝试用其二进制前缀(如Rabin–Karp算法的滚动哈希)进行相等检查,如果前缀相等,则回退到较慢的字符串比较。
使用B+树
DBMS可使用已有的B+树索引来辅助排序。
- 如果索引是聚簇索引,DBMS可以直接遍历B+树。由于索引是聚簇的,数据将以正确的顺序存储,因此I/O访问将是顺序的。这意味着它总是比外部归并排序更好,因为不需要进行计算。
- 如果索引是非聚簇的,遍历树几乎总是更糟糕的,因为每条记录可能存储在任何page上,所以几乎所有的记录访问都需要(随机)磁盘读取。
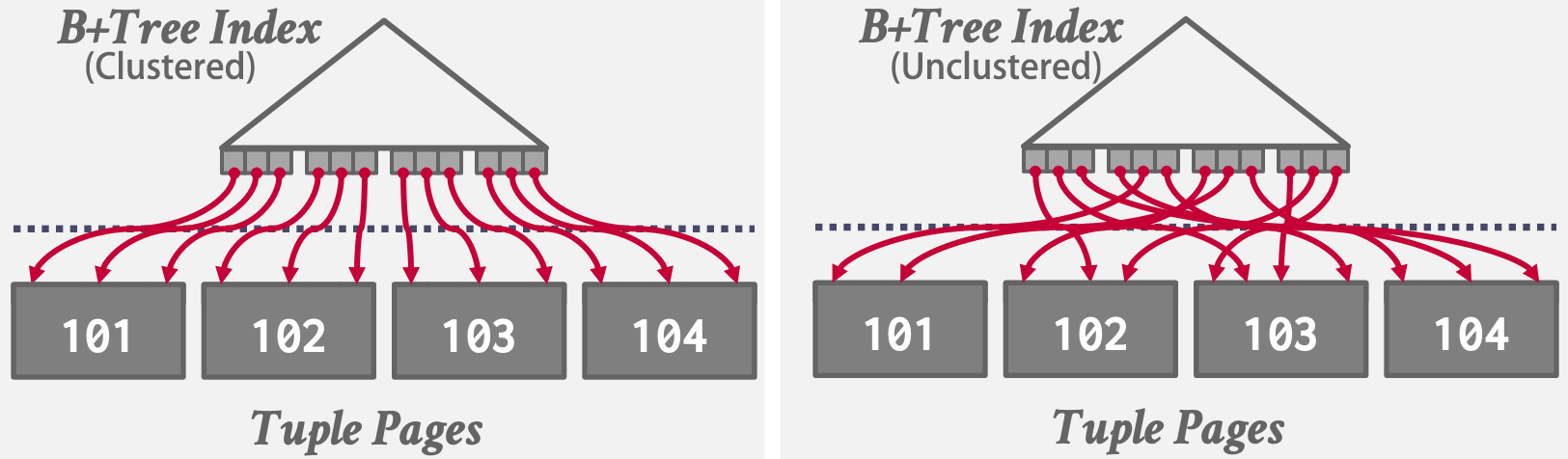 因此优化器必须评估不同查询计划的I/O,并决定是否使用索引。
因此优化器必须评估不同查询计划的I/O,并决定是否使用索引。
聚合
查询计划中的聚合操作符将一个或多个元组的值合并为单个标量值(GROUP BY, AVG,COUNT,MIN,MAX,SUM, DISTINCT)。 为了减少I/O消耗,实现聚合有两种方法:(1)排序和(2)哈希。
排序聚合
如果聚合要求有序(有ORDER BY):
- DBMS首先根据GROUP BY键对元组进行排序:如果所有数据都能装入Buffer Pool,它可以使用内存中的排序算法(例如,快速排序),或者如果数据大小超过内存,它可以使用外部归并排序算法。
- 然后DBMS对排序后的数据进行顺序扫描以计算聚合:
- DISTINCT: 丢弃重复
- GROUP BY: 执行聚合计算
SELECT DISTINCT cid
FROM enrolled
WHERE grade IN ('B','C')
ORDER BY cid
 在执行排序聚合时,重点是要合理安排查询操作以提高效率。例如,如果查询需要过滤,最好先执行过滤(谓词/过滤下推),然后对过滤后的数据进行排序,以减少需要排序的数据量。
在执行排序聚合时,重点是要合理安排查询操作以提高效率。例如,如果查询需要过滤,最好先执行过滤(谓词/过滤下推),然后对过滤后的数据进行排序,以减少需要排序的数据量。
哈希聚合
如果聚合无需有序,哈希计算聚合通常比排序计算量更低: DBMS在扫描表时填充一个临时哈希表。对于每条记录,检查哈希表中是否已经有条目,并进行适当的修改:
- DISTINCT: 丢弃重复
- GROUP BY: 执行聚合计算
如果哈希表的大小太大而无法装入内存,那么DBMS必须将其溢写到磁盘。完成这一过程有两个阶段:
- 阶段#1 – 分区:使用哈希函数h1根据目标哈希键将元组分区到磁盘上。这将把所有匹配的元组放入同一个分区。假设总共有B个缓冲区,我们将有B-1个输出缓冲区用于分区,1个缓冲区用于输入数据。如果任何分区已满,DBMS将将其溢写到磁盘。
- 阶段#2 – 重哈希(到内存):对于磁盘上的每个分区,将其读入内存,并基于第二个哈希函数h2(其中h1 ≠ h2)构建内存中的哈希表(这假设每个分区都能装入内存)。然后遍历这个哈希表的每个桶,将匹配的元组集中起来以计算聚合。由于经过了阶段#1的h1相同键会在统一分区,当阶段#2中的内存哈希表无法插入新条目时可以直接丢弃旧条目,因为插入新条目说明旧条目已经完成聚合计算。
SELECT DISTINCT cid
FROM enrolled
WHERE grade IN ('B','C')

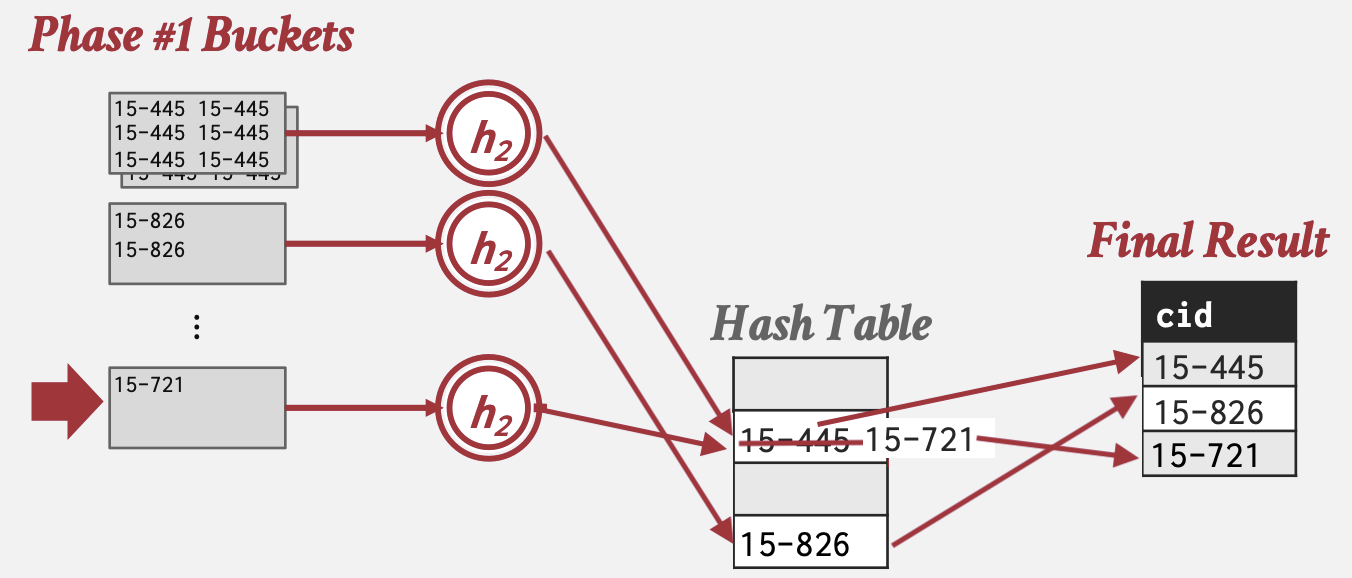 在重哈希阶段,DBMS可以存储形式为(GroupByKey→RunningValue)的对来计算聚合。RunningValue的内容取决于聚合函数,如AVG()应为COUNT和SUM.
在重哈希阶段,DBMS可以存储形式为(GroupByKey→RunningValue)的对来计算聚合。RunningValue的内容取决于聚合函数,如AVG()应为COUNT和SUM.
SELECT cid, AVG(s.gpa)
FROM student AS s, enrolled AS e
WHERE s.sid = e.sid
GROUP BY cid
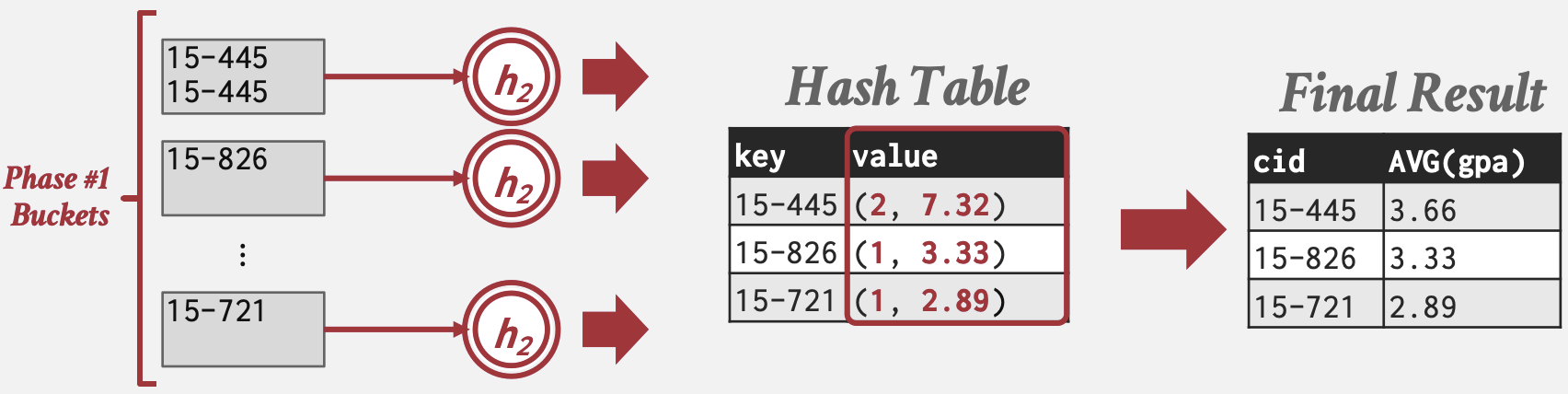 将新元组插入哈希表的方式:
将新元组插入哈希表的方式:
- 如果找到匹配的GroupByKey,则相应地更新RunningValue。
- 否则插入一个新的键值对(GroupByKey→RunningValue)。
连接算法
连接
良好的数据库设计目标是最小化信息重复。这就是为什么表是基于规范化理论构建的。因此,需要连接操作(JOIN)来重建原始表。
下文介绍内连接(inner equijoin)算法,用于组合两个表。等值连接算法连接具有相等键的表。这些算法可以调整以支持其他类型的连接(anti joins, unequality joins, outer joins…)。
操作符输出
对于匹配连接属性的元组r ∈ R和元组s ∈ S,JOIN操作符将r和s连接成一个新的输出元组。 实际上,连接操作符生成的输出元组的内容各不相同。这取决于DBMS的查询处理模型、存储模型和查询本身。连接操作符输出的内容有多种方式:
- 数据 - 提前物化(early-materialized):这种方法将外部表和内部表中的属性值复制到元组中,并将这些元组放入仅用于该操作符的中间结果表中。这种方法的优点是,查询计划中的后续操作符永远不需要回到基础表中获取更多数据。缺点是,这需要更多的内存来物化整个元组。DBMS还可以进行额外的计算,并省略查询中后续不需要的属性,以进一步优化这种方法。
- 记录ID - 延迟物化(late-materialized):在这种方法中,DBMS只复制连接键以及匹配元组的记录ID。这种方法对于列式存储非常理想,因为DBMS不会复制查询不需要的数据。
成本分析
成本度量方式:计算连接所使用的磁盘I/O数量。这包括从磁盘读取数据以及将任何中间数据写入磁盘所产生的I/O。
注意,只考虑计算连接时产生的I/O,而不考虑输出结果时产生的I/O。这是因为输出成本取决于数据,而且任何连接算法的输出成本都是一样的,因此不同算法之间的成本不会改变。
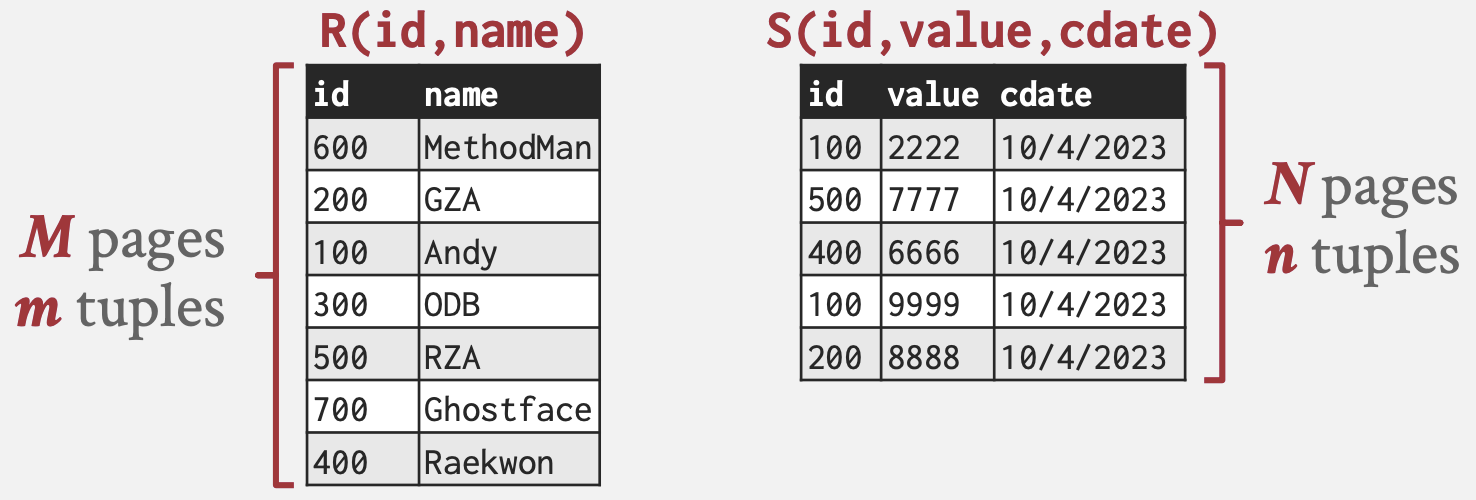 下文中使用的符号:
下文中使用的符号:
- 表R(外部表)有M个页面,m个元组
- 表S(内部表)有N个页面数,n个元组
一般来说,会有许多算法/优化可以在某些情况下减少连接成本,但没有单一的算法在所有场景下都表现良好。
Nested Loop Join
嵌套循环连接。从高层次上看,这种连接算法由两个嵌套的for循环组成,它们遍历两个表中的元组,并成对比较它们。如果元组匹配连接的谓词(predicate),则输出它们。 外部for循环中的表称为外部表(左表),内部for循环中的表称为内部表(右表)。
Simple Nested Loop Join
简单嵌套循环连接。对于外部表中的每个元组,将其与内部表中的每个元组进行比较。
foreach tuple r in R: // Outer
foreach tuple s in S: // Inner
if r and s match then emit
这是最糟糕的情况,其中DBMS必须对内部表进行完整扫描,而没有任何缓存或访问局部性。
成本:M + (m × N), 即R中的每个tuple都要扫描S的所有Page
Block Nested Loop Join
块嵌套循环连接。对于外部表中的每个块(页面),从内部表中获取每个块并比较这两个块中的所有元组。
foreach block B_R in R:
foreach block B_S in S:
foreach tuple r in B_R:
foreach tuple s in B_S:
if r and s match then emit
这种算法执行的磁盘访问次数较少,因为DBMS是逐每个外部表块扫描内部表,而不是逐每个元组。
成本:M + (M × N), 即R中的每个页面都要扫描S的所有Page
如果DBMS有B个缓冲区可用于计算连接,那么它可以使用B − 2个缓冲区来扫描外部表。它将使用一个缓冲区来扫描内部表,一个缓冲区来存储连接的输出。
成本:M + ⌈(M / (B - 2)) x N⌉
Index Nested Loop Join
索引嵌套循环连接。前文的嵌套循环连接算法性能不佳,因为DBMS必须进行顺序扫描以检查内部表中的匹配项。然而,如果数据库已经有一个表的连接键上的索引,它可以利用该索引来加速比较。DBMS可以使用已有的索引或为连接操作构建一个临时索引。
将没有索引的那个表作为外部表;具有索引的那个表作为内部表。
foreach tuple r in R:
foreach tuple s in Index(r_i = s_j):
if r and s match then emit
假设使用索引查找每个元组的成本为常数值C:
成本:M + (m × C)
小结
- DBMS总是希望使用“较小”的表作为外部表。较小可以是元组数量或页面数量方面的。
- DBMS还希望尽可能多地将外部表缓冲到内存中。
- 还可以尝试利用索引来在内部表中找到匹配项。
Sort-Merge Join
排序-合并连接。从高层次上看,排序-合并连接对两个表在其连接键上进行排序。DBMS可以使用外部归并排序算法来完成这个操作。然后,它使用游标逐步遍历每个表并emit匹配项(就像在归并排序中一样)。
sort R,S on join keys
cursor_R ← R_sorted, cursor_S ← S_sorted
while cursor_R and cursor_S:
if cursor_R > cursor_S:
increment cursor_S
if cursor_R < cursor_S:
increment cursor_R
backtrack cursor_s (if necessary)
elif cursor_R and cursor_S match:
emit
increment cursor_S
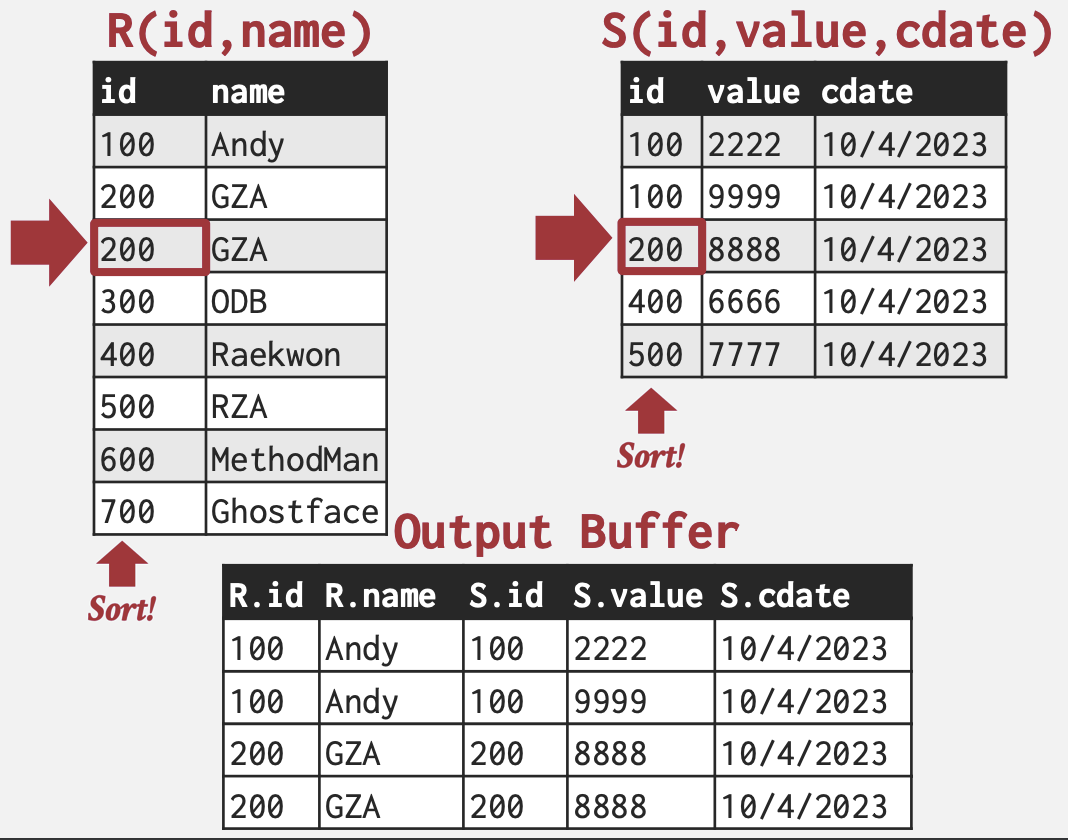
如果一个或两个表已经在连接属性上排序(如聚簇索引),或者输出需要在连接键上排序,这种算法就非常有用。
这种算法的最糟糕情况是,如果两个表中所有元组的连接属性都包含相同的值,这在真实数据库中非常不可能发生。在这种情况下,合并的成本将是M · N。然而,大多数情况下,键大多是唯一的,所以合并成本大约是M + N。
假设DBMS有B个缓冲区用于算法:
- 表R的排序成本:$2M × (1 + ⌈\log_{B−1} ⌈M/B⌉⌉$
- 表S的排序成本:$2N × (1 + ⌈\log_{B−1} ⌈N/B⌉⌉$
- 合并成本:(M + N) 总成本:排序 + 合并
Hash Join
哈希连接算法的高层次思想是使用哈希表根据它们的连接属性将元组分成更小的块。这减少了DBMS在计算连接时每个元组需要执行的比较次数。哈希连接只能用于完整连接键的等值连接。
如果元组r ∈ R和元组s ∈ S满足连接条件,那么它们在连接属性上具有相同的值。如果该值被哈希到某个值$i$,那么R元组必须在桶$r_i$中,S元组必须在桶$s_i$中。因此,桶$r_i$中的R元组只需要与桶$s_i$中的S元组进行比较。
基础哈希连接
- 阶段#1 - 构建:首先,扫描外部表并使用连接属性上的哈希函数h1填充哈希表。哈希表的键是连接属性。值取决于实现(可以是完整的元组值或元组ID)。
- 阶段#2 - 探测:扫描内部表,并使用连接属性上的哈希函数h1跳转到哈希表中的相应位置并找到匹配的元组。由于哈希表中可能存在冲突,DBMS需要检查连接属性的原始值以确定元组是否真正匹配。
build hash table HT_R for R
foreach tuple s in S
output, if h1(s) in HT_R
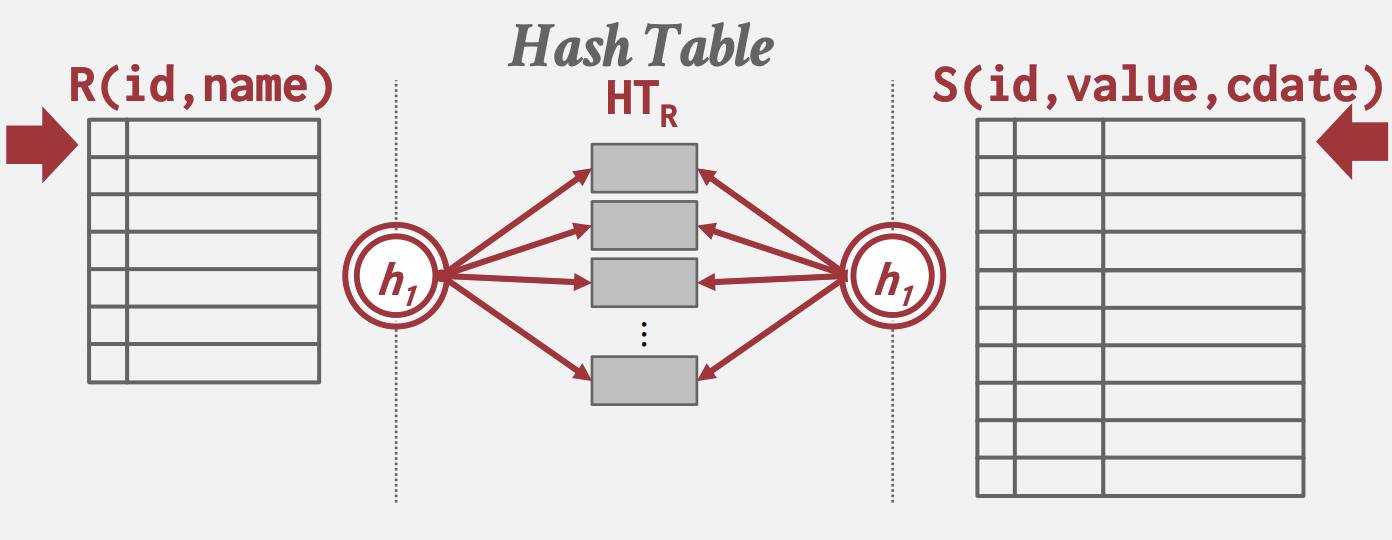
如果DBMS知道外部表的大小,连接可以使用静态哈希表。如果它不知道大小,那么连接必须使用动态哈希表或允许溢出页面。
一个拥有N个页面的表需要大约√N个缓冲区。上述方法在第一阶段创建了B − 1个大小不超过B块的分区,因此假设哈希函数均匀分布记录,可以使用这种方法哈希的最大表大小是B · (B − 1)个缓冲区。如果哈希函数不均匀,可以引入一个大于1的修正因子f,因此最大表大小是B · √(f · N)。
探测阶段的一个优化是使用布隆过滤器(Bloom Filter)。这是一种可以利用CPU缓存的概率性数据结构,可以回答“键x在哈希表中吗?”这个问题,能得出 肯定无 或 可能有。如果是后者情况,再去哈希表中检查。
Partitioned Hash Join / Grace Hash Join
当哈希表不能装入主内存时,DBMS得几乎是随机地在内存中置换表,这导致性能不佳。Partitioned Hash Join是基础哈希连接的扩展,它还将内部表哈希成分区,这些分区被写入磁盘。
- 阶段#1 - 构建:首先,扫描外部和内部表,并使用连接属性上的哈希函数h1填充哈希表。哈希表的桶根据需要写入磁盘。如果单个桶无法装入内存,DBMS可以使用不同的哈希函数h2(其中h1 ≠ h2)进行递归分区,以进一步划分桶。这可以递归继续,直到桶能装入内存。
- 阶段#2 - 探测:对于每个桶级别,检索外部表和内部表对应的页面。然后在这两个页面上的元组上执行嵌套循环连接。这些页面将装入内存,因此这个连接操作将会很快。
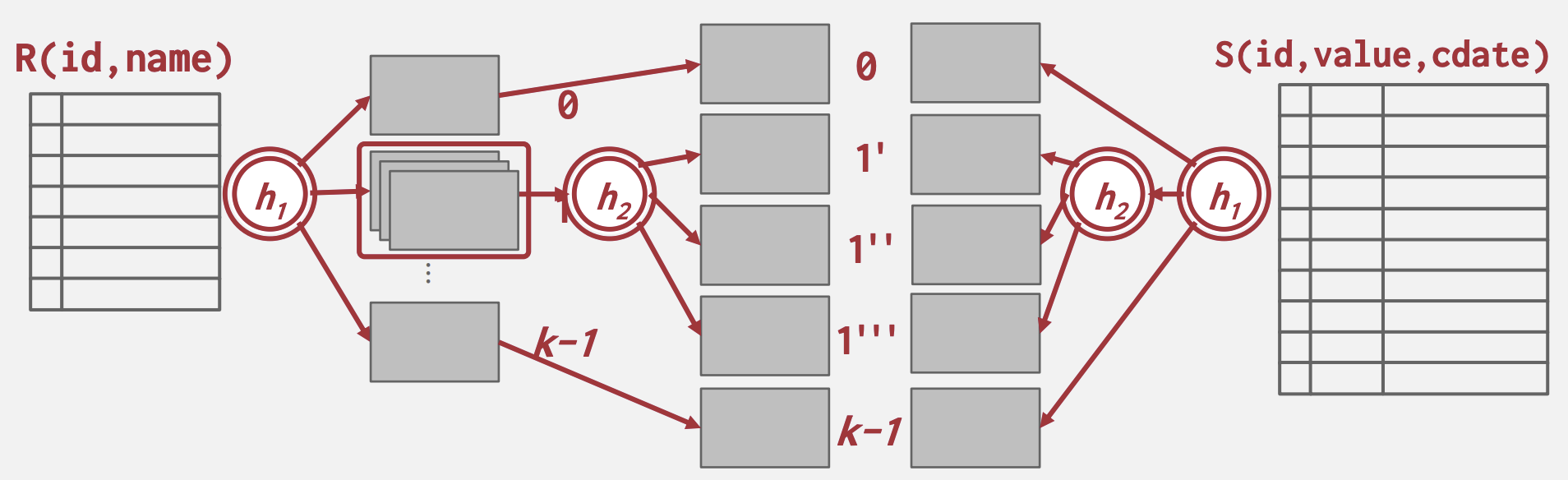
- 分区阶段成本:2 × (M + N), 即读和写两张表
- 探测阶段成本:(M + N), 即总共读两张表, 每次读取一个分区
- 总成本:3 × (M + N)
混合哈希连接优化:在 基础哈希连接 和 Partitioned Hash Join 之间自适应;如果键是偏斜的,就保持热分区在内存中,并立即执行比较,而不是将其溢写到磁盘。但正确实现很困难。
总结
连接是与关系数据库交互的重要组成部分,因此确保DBMS具有高效的算法来执行连接至关重要。
| 算法 | I/O成本 | 例子 |
|---|---|---|
| Simple Nested Loop Join | M + (m · N) | 1.4 hours |
| Block Nested Loop Join | M + (M · N) | 50 seconds |
| Index Nested Loop Join | M + (m · C) | 不定 |
| Sort-Merge Join | M + N + (排序成本) | 0.75 seconds |
| Hash Join | 3 · (M + N) | 0.45 seconds |
上表假设以下条件:
- M = 1000, m = 100000, N = 500, n = 40000, B = 100 且每次 I/O 0.1 ms.
- 排序成本为 R + S = 4000 + 2000 IOs, 其中:
- $R = 2 · M · (1 + ⌈\log_{B−1} ⌈M/B⌉⌉) = 2000 ·(1 + ⌈\log_{99} ⌈1000/100⌉) = 4000$
- $S = 2 · N · (1 + ⌈\log_{B−1} ⌈N/B⌉⌉) = 1000 · (1 + ⌈\log_{99} ⌈500/100⌉) = 200$
查询处理
处理模型
DBMS 处理模型定义了系统如何执行查询计划。
- 它指定了查询计划的计算方向以及操作符之间传递的数据类型。
- 不同的处理模型适用于不同的工作负载
- 这些模型也可以实现自上而下或自下而上地调用操作符。尽管自上而下的方法更为常见,但自下而上的方法可以更紧密地控制管道中的缓存/寄存器。
迭代器模型
迭代器模型(Iterator Model),也称为火山(Volcano)或管道(Pipeline)模型,是最常见的处理模型,几乎所有(基于行的)DBMS都使用它。
- 迭代器模型通过为数据库中的每个操作符实现一个 Next 函数来工作。
- 查询计划中的每个节点调用其子节点的 Next,直到达到叶子节点,这些节点开始向上emit元组以便父节点处理。
- 每个元组在处理尽可能远之后,再检索下一个元组。这对于基于磁盘的系统非常有用,因为它允许我们在访问下一个元组或页面之前充分利用内存中的每个元组。
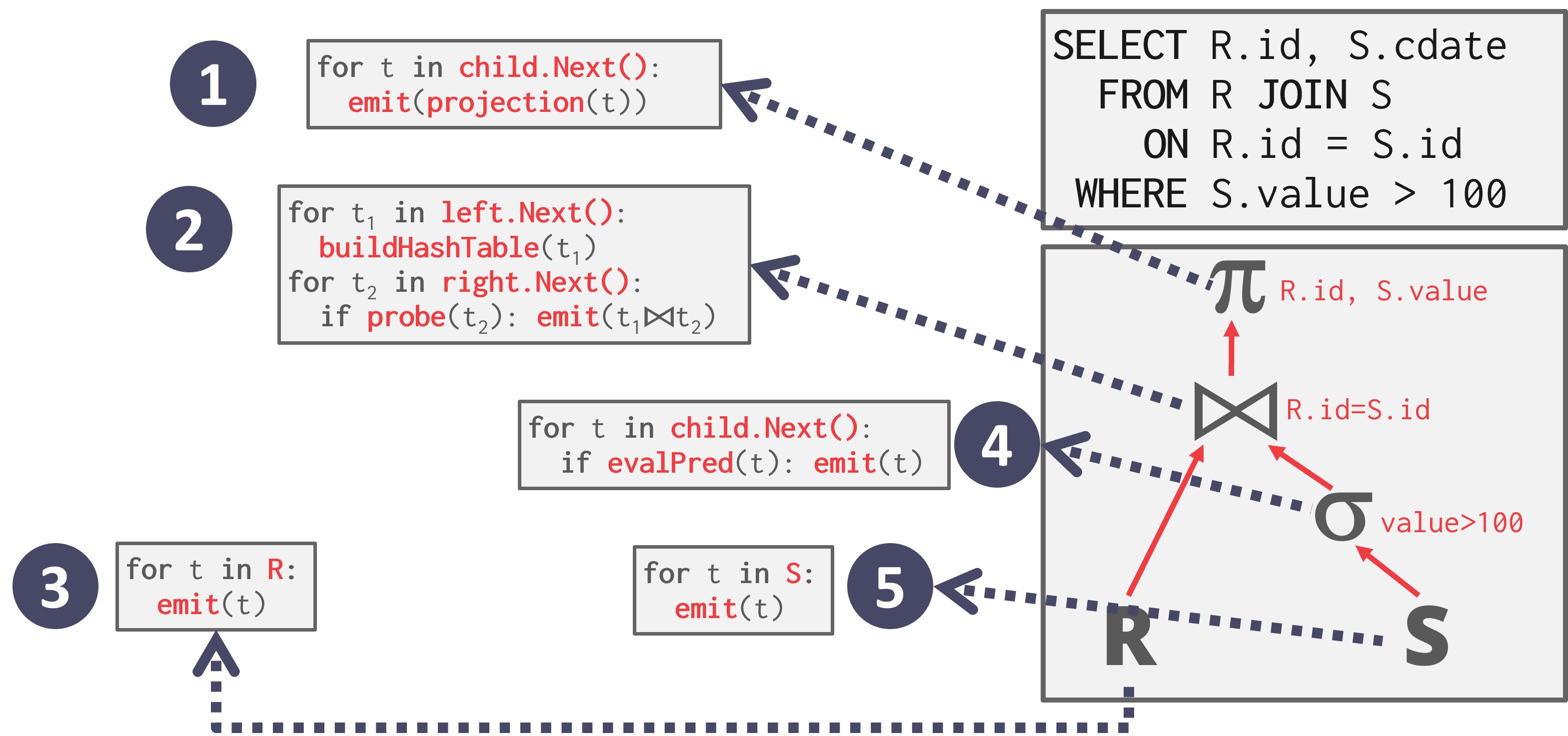
如图, 每个操作符的不同 Next 函数的伪代码。Next 函数主要部分是循环,它们遍历其子操作符的输出。例如,根节点调用其子节点的 Next,即join操作符,这是一个访问方法,它遍历关系 R 并emit一个元组,然后对其进行操作。处理完所有元组后,发送一个空指针,让父节点继续前进。
查询计划中的迭代器模型操作符高度可组合且易于理解,因为每个操作符可以独立于其父或子操作符进行实现,只要它实现了如下的 Next 函数:
- 每次调用 Next 时,操作符返回一个单一元组或空标记(如果没有更多元组要emit)。
-
操作符实现了一个循环,该循环调用其子节点的 Next 函数以检索它们的元组,然后对这些元组进行处理。通过这种方式,调用父节点的 Next 函数会调用其子节点的 Next 函数。作为响应,子节点将返回父节点必须处理的下一个元组。
- 迭代器模型允许流水线(pipeline)处理,即 DBMS 可以在必须检索下一个元组之前,尽可能地通过多个操作符处理一个元组。在查询计划中为给定元组执行的一系列任务被称为流水线。
- 有些操作符会阻塞,直到其子节点emit出所有元组。这类操作符的例子包括连接(joins)、子查询和排序(ORDER BY)。这类操作符被称为pipeline breakers。
- 输出控制(LIMIT)与这种方法很容易配合使用,因为一旦操作符获得了它所需的所有元组,它就可以停止调用其子操作符(们)的 Next 函数。
物化模型
物化模型(Materialization Model)是迭代器模型的特化,其中每个操作符一次性处理其输入,然后一次性emit其输出。
- 与迭代器模型返回单个元组的 Next 函数不同,每个操作符每次被调用时返回所有元组。
- 为了避免扫描过多的元组,DBMS 可以向下传递关于需要多少元组的信息(例如 LIMIT)。
- 操作符将其输出“物化”为结果。输出可以是整个元组(NSM)或列的子集(DSM)。
每个查询计划操作符都实现了一个 Output 函数:
- 操作符一次性处理其所有子节点的元组。
- 这个函数的返回结果是该操作符将emit的所有元组。当操作符执行完成后,DBMS 再也不需要返回它以检索更多数据。
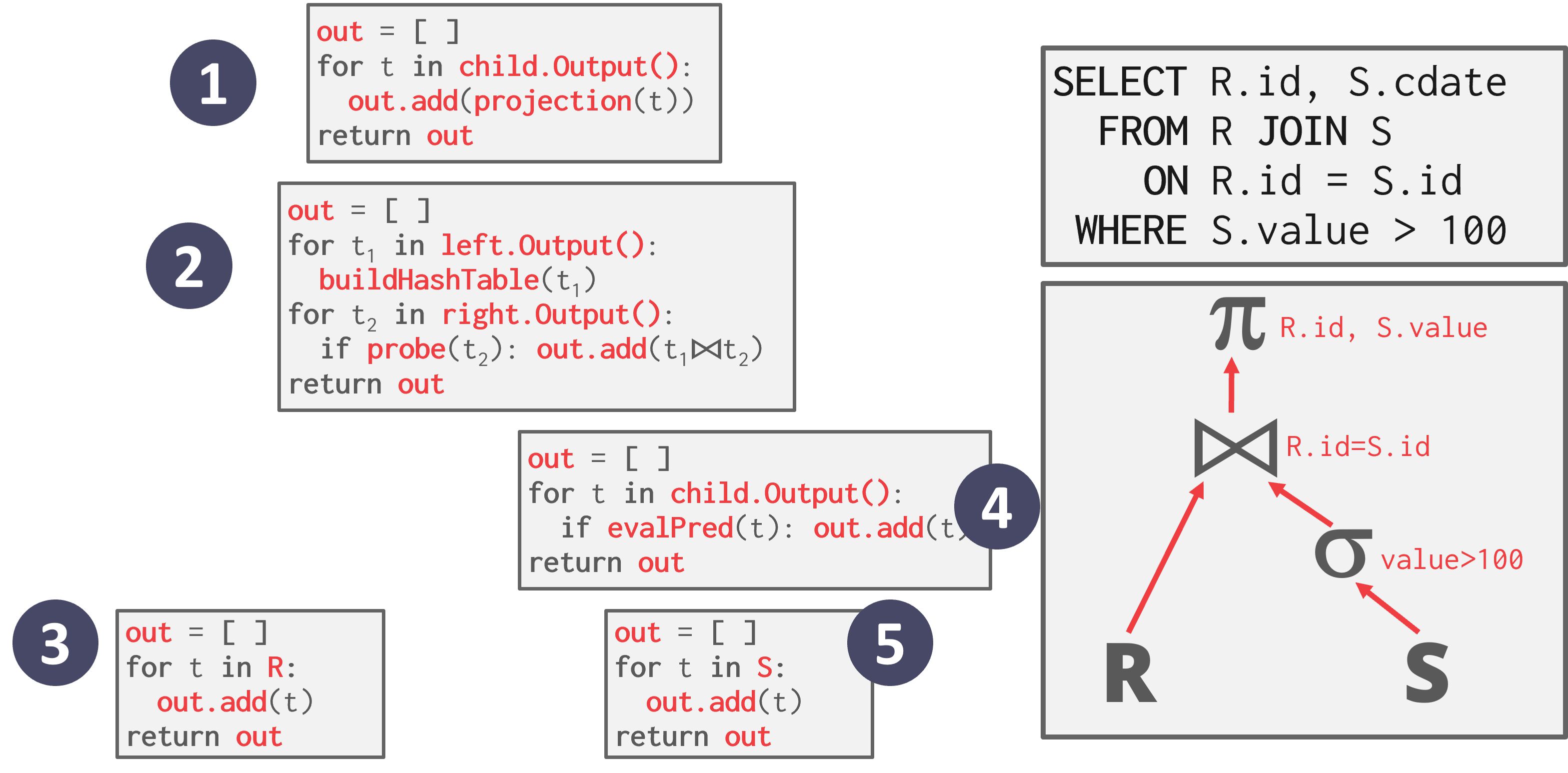
如图,从根节点开始,调用子节点的 Output() 函数,该函数调用下面的操作符,然后返回所有元组。
- +这种方法更适合 OLTP 工作负载,因为查询通常一次只访问少量元组。因此,检索元组的函数调用次数较少。
- -物化模型不适合具有大型中间结果的 OLAP 查询,因为 DBMS 可能需要在操作符之间将这些结果溢写到磁盘。
矢量化模型
与迭代器模型类似,矢量化模型(Vectorization Model)中的每个操作符实现了一个 Next 函数。然而,每个操作符emit的是一批数据(即矢量)而不是单个元组。
- 操作符的内部循环实现可以针对处理一批数据行优化
- 批次的大小可以根据硬件或查询属性变化
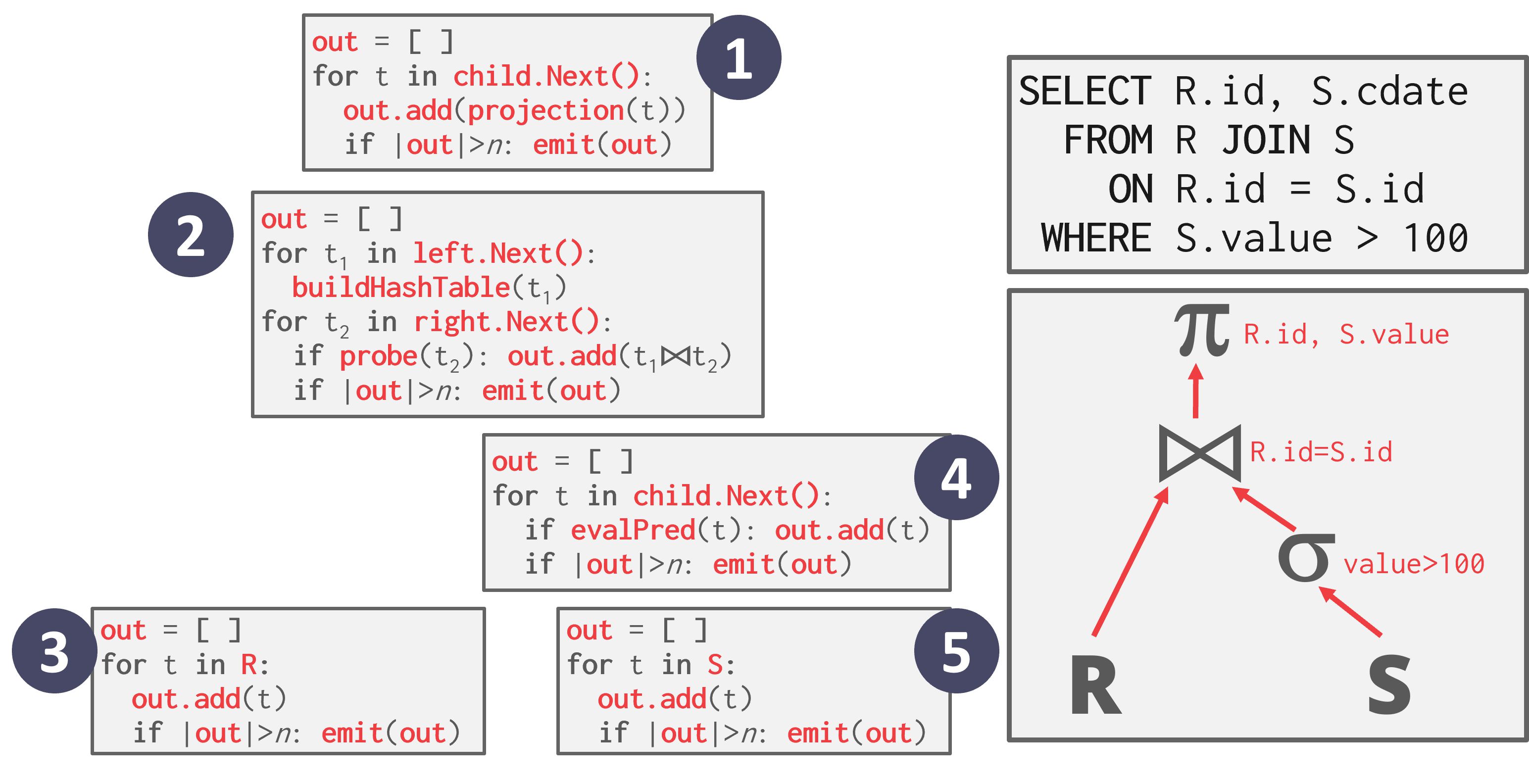
如图,在每个操作符处,都会将输出缓冲区与期望的emit大小进行比较。如果缓冲区较大,则发送一个元组批次。
- 矢量化模型适用于需要扫描大量元组的 OLAP 查询,因为 Next 函数的调用次数较少
- 矢量化模型允许操作符更容易地使用矢量化(SIMD)指令处理一批元组。
处理方向
- 方法 #1: 自上而下
- 从根节点开始,“拉取”数据从子节点到父节点
- 元组总是通过函数调用传递
- 方法 #2: 自下而上
- 从叶子节点开始,从子节点到父节点“推送”数据
- 允许更紧密地控制操作符管道中的缓存/寄存器
访问方法
访问方法(Access Methods)即 DBMS 访问表中存储数据的方式:
顺序扫描
顺序扫描操作符迭代表中的每个页面,并从Buffer Pool中检索它。
- 当扫描遍历每个页面上的所有元组时,它计算谓词(predicate)以决定是否将元组emit到下一个操作符。
- DBMS 维护一个内部游标,跟踪它最近检索的Page/Slot。
顺序表扫描几乎是 DBMS 执行查询最低效的方法。有许多优化可用以帮助加快顺序扫描:
- 预取(Prefetching):提前获取下几个页面,以便 DBMS 在访问每个页面时不必阻塞在存储 I/O 上。
- Buffer Pool Bypass::扫描操作符将其从磁盘获取的页面存储在其局部内存中,而不是全局Buffer Pool中,以避免顺序泛洪(Sequential flooding)问题。
- 并行化(Parallelization):使用多个线程/进程并行执行扫描。
- 延迟物化(Late Materialization):DSM DBMS 可以延迟将元组拼接在一起,直到查询计划的上部。这允许每个操作符只传递所需的最小信息到下一个操作符(例如记录 ID,列中的记录偏移量)。这仅在列存储系统中有用。
- 堆聚簇(Heap Clustering):使用聚簇索引指定的顺序在堆页面中存储元组。
- 近似查询(Approximate Queries, 有损数据跳过):在允许产生近似结果的场景中,对整个表的样本子集执行查询以产生近似结果。这通常用于计算聚合,且允许产生误差。例子:
- 区域图(Zone Map, 无损数据跳过):预先计算每个页面中每个元组属性的聚合。然后 DBMS 可以先检查其区域图,再决定是否需要访问页面。每个页面的区域图存储在单独的页面中,每个区域图页面通常有多个条目。因此,可以减少顺序扫描中检查的总页面数。区域图在云数据库系统中特别有价值,因为通过网络传输数据会产生更大的成本。例子:
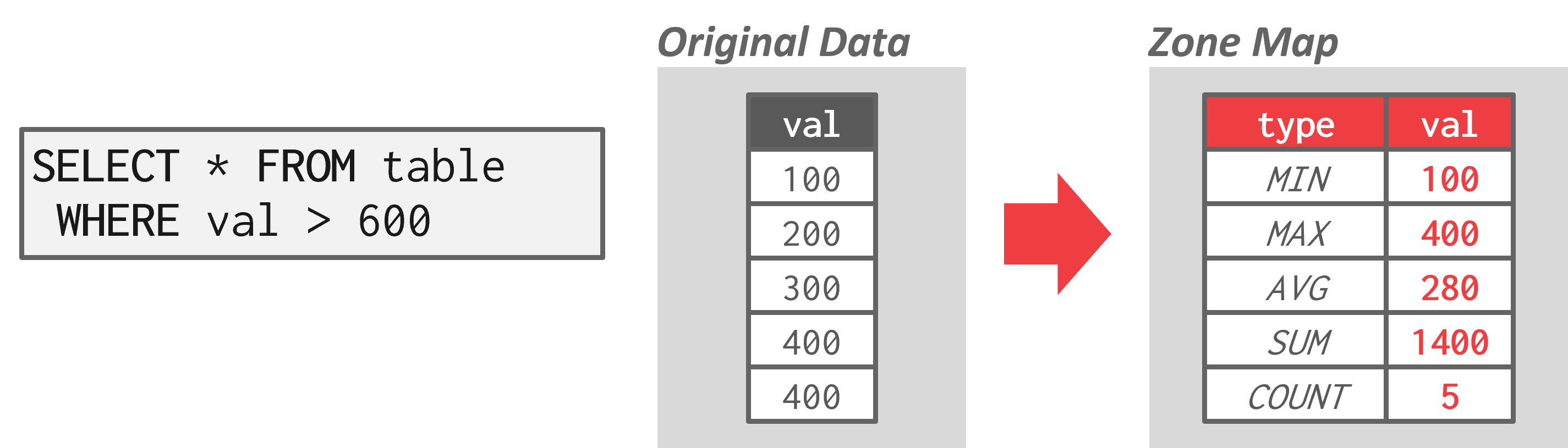
如图:区域图存储了页面中值的预先计算聚合。在上面的例子中,选择查询从区域图中得知原始数据中的最大值仅为400。然后,查询可以完全避免访问该页面,因为没有任何值会大于600。
顺序扫描的局限性:
- 函数调用开销
- 缺乏并行化(例如,无法利用矢量操作的优点)
索引扫描
在索引扫描(Index Scan)中,DBMS 选择一个索引来查找查询所需的元组。
SELECT * FROM students
WHERE age < 30
AND dept = 'CS'
AND country = 'US'
假设包含100个元组和两个索引(age和dept)的单个表
- 情况1: 99人满足age < 30, 但只有2人满足dept = ‘CS’. 使用dept索引进行扫描更好,因为它只有2个元组需要匹配。选择age索引并不会比简单的顺序扫描好很多
- 情况2: 99人满足dept = ‘CS’, 但只有2人满足age < 30. 此时age索引可以消除更多不必要的扫描,是最佳选择。
有许多因素涉及 DBMS 的索引选择过程,包括:
- 索引包含的属性
- 查询引用的属性
- 属性的值域
- 谓词(Predicate)组合
- 索引是否具有唯一或非唯一键
多索引扫描
高级的 DBMS 支持多索引扫描,查询可以使用多个索引时:
- 使用每个匹配的索引计算记录 ID 的集合
- 根据查询的谓词组合这些集合(union或intersect, 位图、哈希表或布隆过滤器)
- 检索记录并应用剩余的谓词。
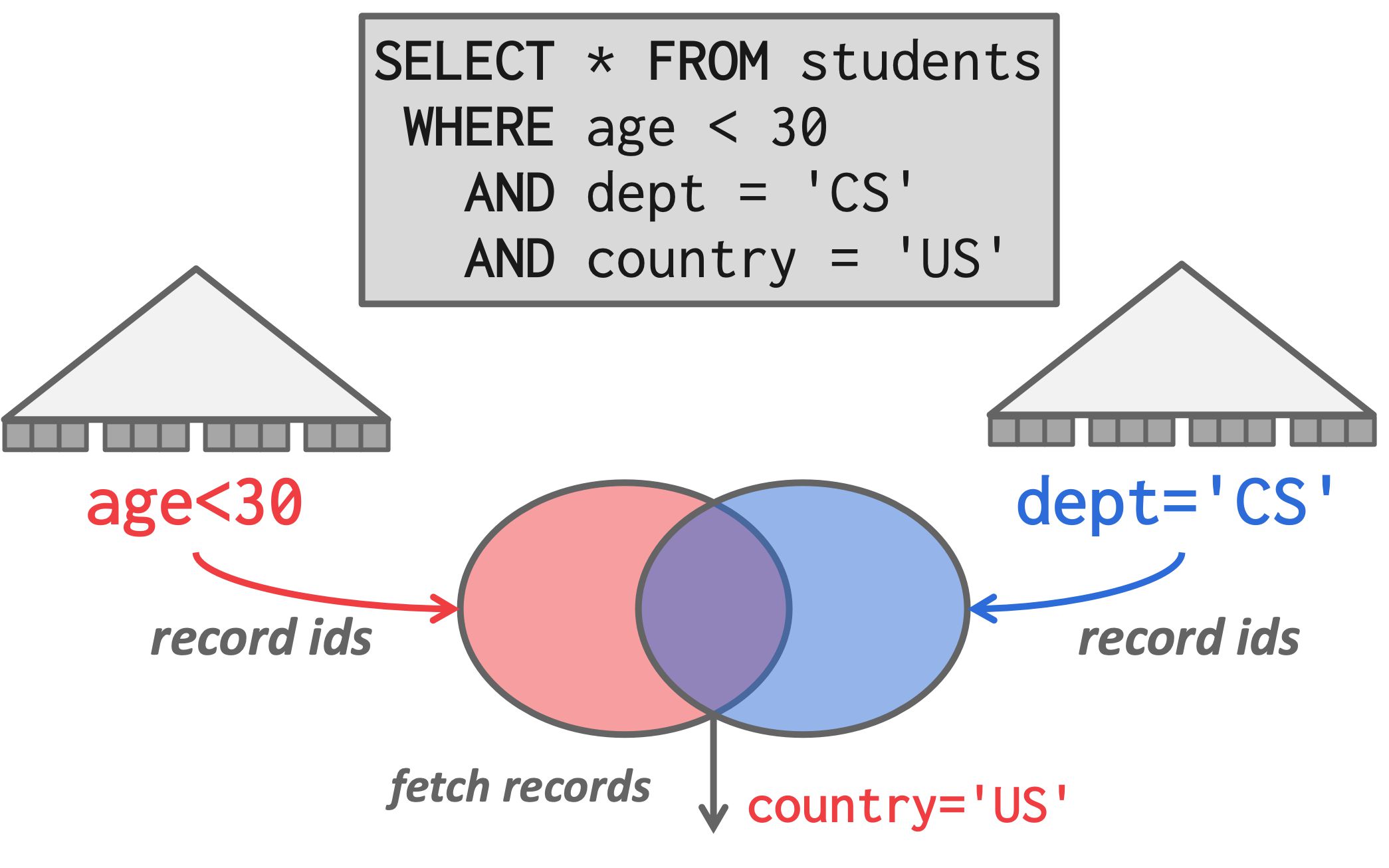
如图,有了多索引扫描支持:
- 首先分别使用相应的索引计算满足age和dept谓词的记录 ID 集合
- 然后计算这两个集合的交集(因为谓词的AND),检索相应的记录
- 并应用剩余的谓词 country=’US’
例子:
修改查询
修改数据库的操作符(INSERT, UPDATE, DELETE)负责检查约束,修改目标table并更新索引。
UPDATE/DELETE 操作符:
- 子操作符传递目标元组的记录 ID
- 跟踪之前看过的元组,防止重复修改
INSERT 操作符有两种实现:
- 在操作符内部物化元组。
- 元组由子操作符传递,INSERT 操作符指负责将其插入。可组合性高。
Halloween Problem
更新操作改变了元组的物理位置,导致扫描操作符多次访问到同一个元组。这可能发生在聚簇表或索引扫描上。

解决方法: 跟踪每个查询修改过的记录 ID。
表达式计算
表达式树
DBMS 将 WHERE 子句表示为表达式树(在查询计划的每个操作符中)。树中的节点代表不同的表达式类型。
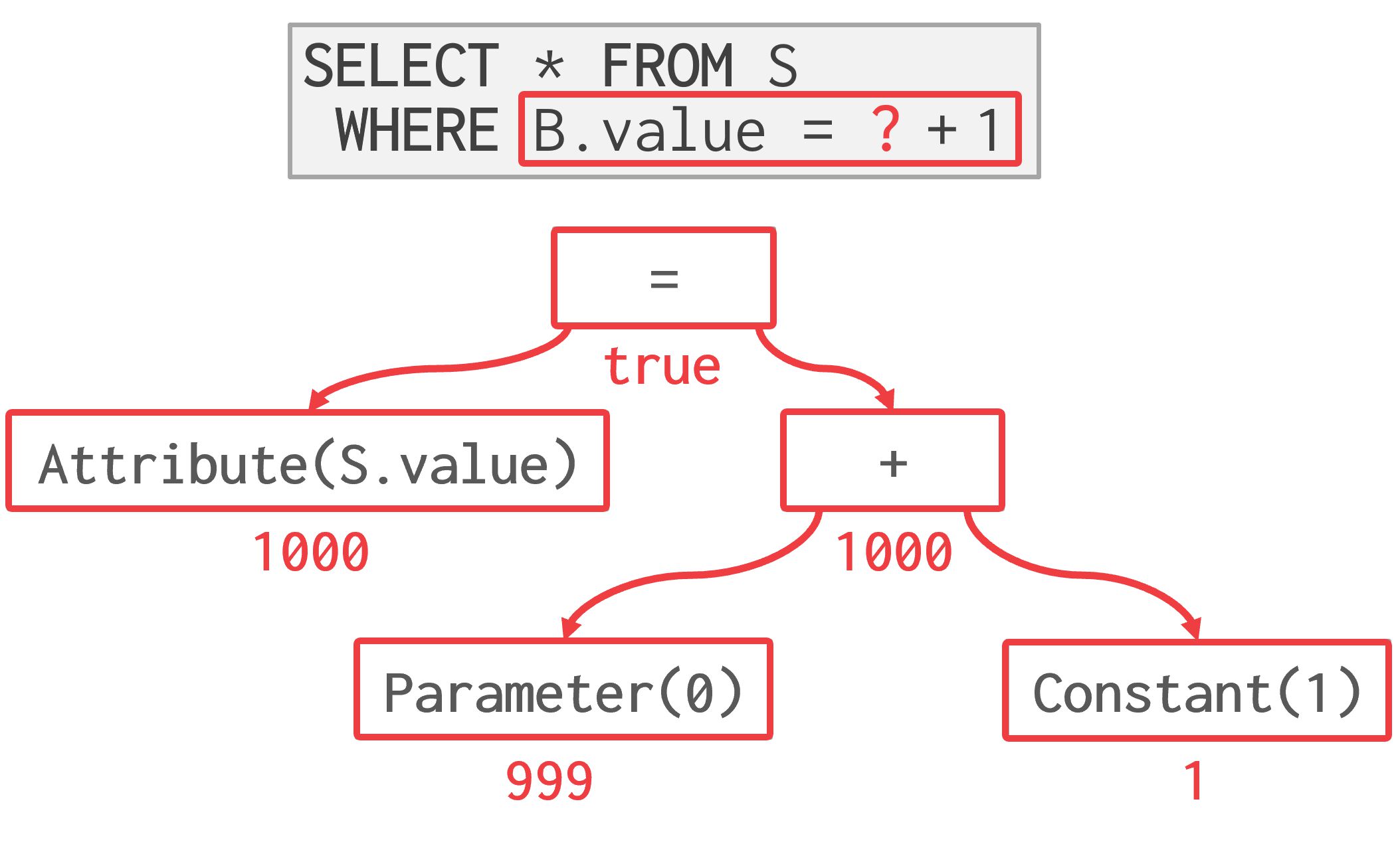
存储在树节点中的表达式类型包括:
- 比较(=, <, >, !=)
- 连接词(AND),析取词(OR)
- 算术运算符(+, -, *, /, %)
- 常量和参数值
- 元组属性引用
为了在运行时计算表达式树,DBMS 维护一个上下文句柄,其中包含执行的元数据:
- 当前元组
- 参数
- 表模式(schema)
然后 DBMS 遍历树以计算其操作符并产生结果。
JIT编译加速
以表达式树计算谓词很慢,因为 DBMS 必须遍历整棵树并确定每个操作符的正确操作,不能利用现代CPU的分支预测。
更好的方法是通过代码生成直接计算表达式的代码(JIT 编译)。DBMS 根据成本模型, 决定是否采用代码生成来加速查询(代码生成+编译代价 vs 扫描的元组数)。
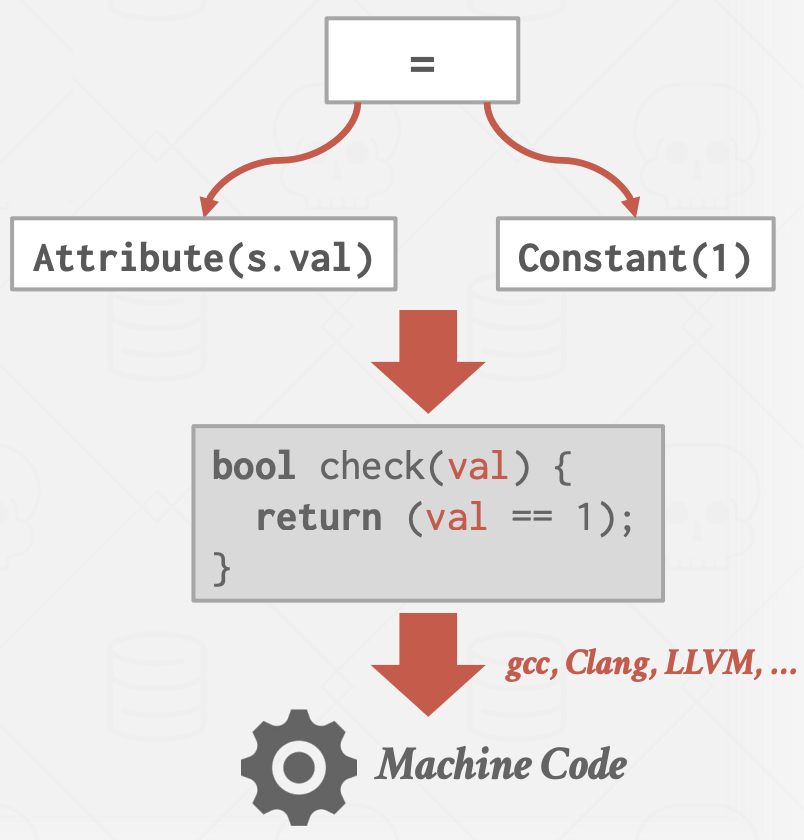
并行执行
之前关于查询执行的讨论假设查询是使用单个Worker(即线程)执行的。然而,在实践中,查询通常是并行执行的,涉及多个Worker。
优势:
- 提高吞吐量(每秒更多查询)和延迟(每个查询时间更短)的性能。
- 从客户端的角度提高响应性和可用性。
- 降低总体拥有成本(TCO):包括硬件采购、软件许可、劳动力开销、运行机器所需的能源。
并行与分布式数据库
共性:将数据库分布在多个“资源”上以提高并行性:
- 计算资源(例如,CPU核心、CPU插槽、GPU、额外的机器)
- 存储资源(例如,磁盘、内存)
区别:
- 并行DBMS:
- 资源或节点彼此物理上很接近
- 节点通过高速互连通信
- 假设资源之间的通信不仅快速,而且成本低且可靠。
- 分布式DBMS:
- 资源可能彼此相隔很远, 数据库可能跨越机架或数据中心
- 资源使用较慢的互连(通常是公共网络)进行通信
- 节点之间的通信成本更高,不能忽视故障(即,节点可能会崩溃,数据包可能会丢失)。
尽管数据库可能在多个资源上物理上被分割,但它仍然对应用程序表现为单一逻辑实例。因此,针对单节点DBMS执行的SQL查询应该在并行或分布式DBMS上产生相同的结果。
进程模型
即系统如何实现以支持来自多用户应用程序/环境的并发请求。
Worker: 负责代表客户端执行任务并返回结果。 DBMS由一个或多个Worker组成,应用程序可能同时发送一个大请求或多个请求,这些请求会分配给不同的Worker。
进程模型类型:
- 每个Worker一个进程
- 每个Worker一个线程
- 由应用调度嵌入式数据库
每个Worker一个进程
最基本的方法是每个Worker运行在一个单独的操作系统进程中。
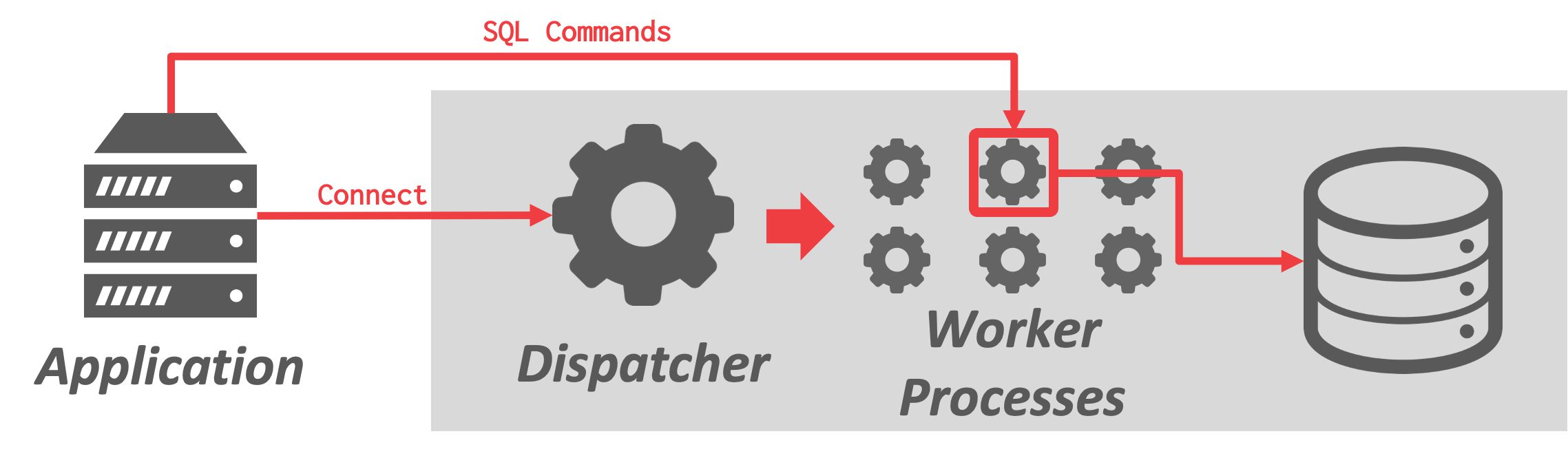
- 应用程序发送请求并打开到数据库系统的连接
- 由dispatchers接收请求并选择其中一个worker进程来管理连接
- 然后应用程序直接与负责执行查询请求的Worker通信
多个Worker在单独的进程中,维护相同页面的多个副本。为了最大化内存使用,使用共享内存来存储全局数据结构,以便不同进程的Worker共享。
- +进程崩溃不会影响整个系统,因为每个Worker在自己的操作系统进程上下文中运行
- -由于依赖操作系统进行调度,DBMS对执行的控制有限
- -依赖共享内存来维护全局数据结构/依赖于消息传递,开销较大
例子:IBM DB2、Postgres和Oracle。 这些DBMS被开发时,pthreads还没有成为标准的线程模型,故线程的语义因操作系统而异。
每个Worker一个线程
每个数据库系统只有一个进程,带有多个Worker线程。
- DBMS完全控制任务和线程,它可以管理自己的调度
- 可选使用/不使用dispatcher线程
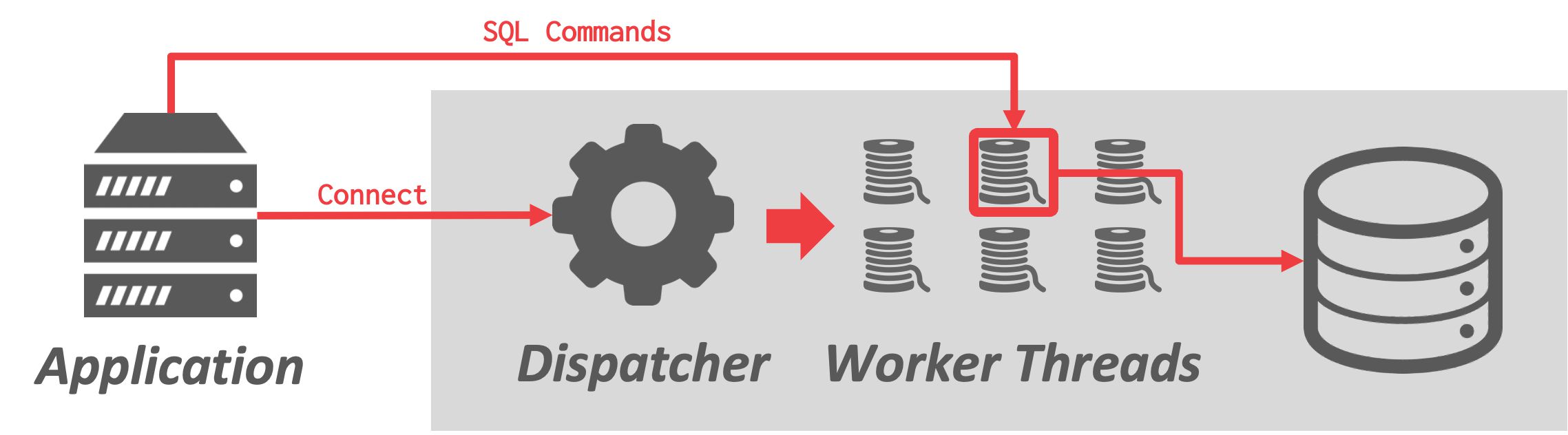
- +上下文切换的开销较小
- +不需要维护共享内存
- -线程崩溃可能会杀死整个数据库进程
使用该模型并不一定意味着DBMS支持查询内并行(如MySQL使用多线程模型但查询仍然以单线程执行)
例子: 几乎所有现代的DBMS都使用这种模型,包括Microsoft SQL Server和MySQL。 IBM DB2和Oracle也通过更新提供对这种模型的支持。 Postgres和Postgres衍生的数据库大多仍然使用基于进程的方法。
调度
对于每个查询计划,DBMS决定在哪里、何时以及如何执行。相关的问题包括:
- 应该使用多少任务?
- 应该使用多少CPU核心?
- 任务应该在哪些CPU核心上执行?
- 任务应该在哪里存储其输出?
DBMS总是比操作系统知道得更多上下文,因此在对查询计划进行决策时,应该优先考虑。
例子,SQL Server的SQL OS: 运行在数据库内部,提供用户层和操作系统层之间的中间层,管理硬件资源,提高数据库操作的性能和可靠性,提供更好的并发控制和资源管理:
- 确定哪些任务被调度到哪些线程上
- 管理 I/O 调度
- 管理更高层次的概念如逻辑数据库锁
- 实现非抢占式线程调度,保证线程被分配给某个任务后将运行直到完成,不会被其他线程抢占,有助于减少上下文切换的开销
嵌入式DBMS
数据库与应用程序在相同的地址空间中运行,如作为代码库被应用程序引用。
- 应用程序设置线程和任务来运行数据库系统
- 由应用程序负责调度
例子:SQLite、DuckDB、RocksDB
查询间并行
DBMS同时执行不同的查询。 由于多个Worker同时运行请求,整体性能得到提高。这增加了吞吐量并减少了延迟。
如果查询是只读的,那么查询之间几乎不需要协调。但如果多个查询同时更新数据库,就会出现冲突。这些问题将在后续讨论。
查询内并行
在查询内并行中,DBMS并行执行单个查询的操作。
- 这减少了长时间查询的延迟
- 组织形式: 生产者/消费者模式。每个操作符既是数据的生产者,也是其下方运行的某个操作符的数据消费者
每个关系操作符都有并行算法。 调度方式:
- 让多个线程访问集中式数据结构
- 或者让分区来分配工作
类型:
- 操作符内并行
- 操作符间并行
- Bushy Parallelism
这些方法并不互斥。DBMS的职责是根据特定工作负载,通过结合这些技术来优化性能。
操作符内并行(水平)
将查询计划的操作符分解成独立片段,对不同的(不相交)数据子集执行相同的函数。
DBMS在查询计划中插入一个Exchange操作符,以合并来自子操作符的结果。Exchange操作符防止DBMS在收到所有子操作符的数据之前,执行计划中的上层操作符。
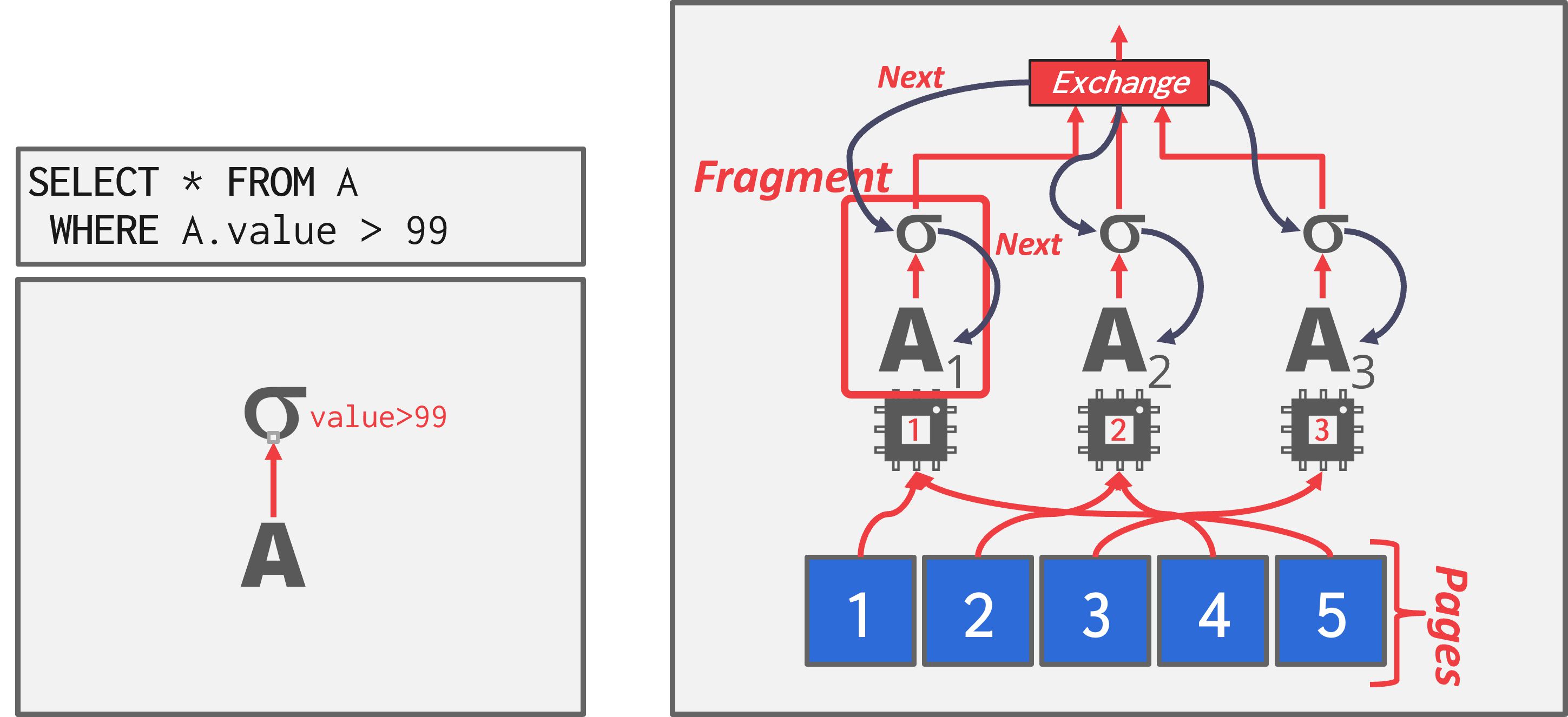
如图,这个SELECT的查询计划是对A的顺序扫描,然后输入到一个过滤操作符。为了并行运行这个查询计划,查询计划被划分成不相交的片段。给定的计划片段由不同的Worker操作。Exchange操作符同时在所有片段上调用Next,然后从它们各自的页面检索数据。
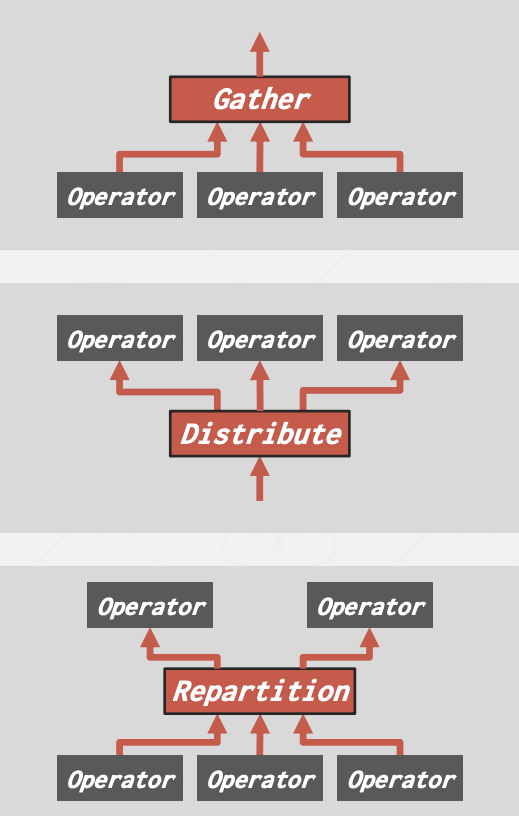
Exchange操作符类型:
- Gather:将多个Worker的结果合并为单一输出流。这是并行DBMS中最常用的类型。
- Distribute:将一个输入流分割成多个输出流。
- Repartition:将多个输入流,重新组织为多个输出流。这允许DBMS以一种方式接收分区的输入,然后以另一种方式重新分发它们。
操作符间并行(垂直)
- 将操作符重叠,将数据从一个阶段流向下一阶段,也被称为流水线并行
- Workers同时分别执行查询计划不同部分的多个操作符,无需等待前阶段Worker处理完所有数据,后阶段Worker同时处理前阶段emit的数据
- 在流处理系统中广泛使用,即在输入元组流上执行持续查询的系统
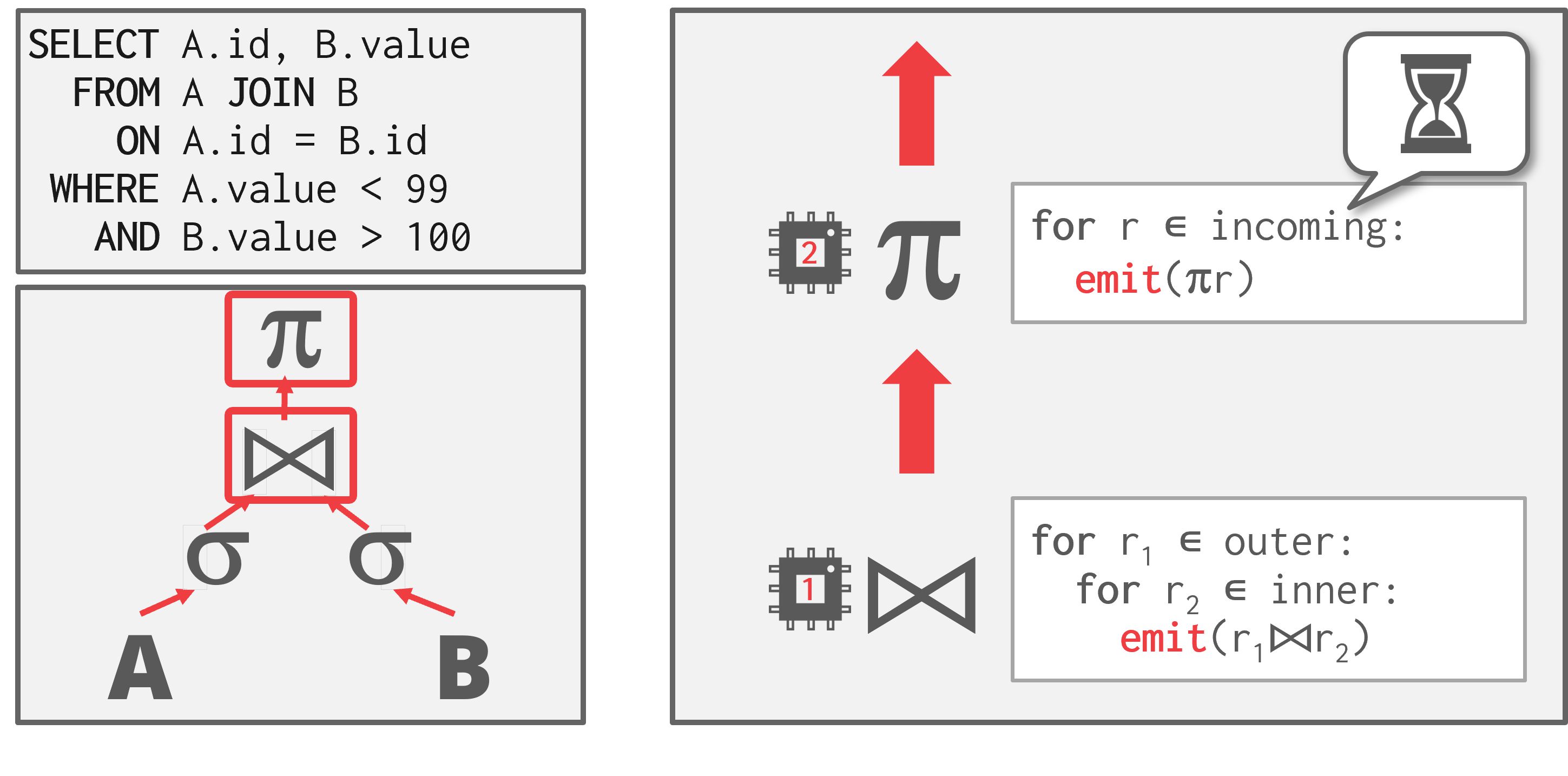
如图, 左侧的JOIN语句中,一个Worker执行JOIN,每执行一次循环(无需完成所有数据的join)就可以将将结果emit到下一个Worker执行投影。
例子:Kafka, Flink, Apache Storm, Apache Spark, Pulsar, Heron.
Bushy Parallelism
Bushy Parallelism混合了操作符内并行和操作符间并行。- Workers同时分别执行查询计划不同部分的多个操作符
- 仍然使用Exchange操作符来合并这些部分的中间结果
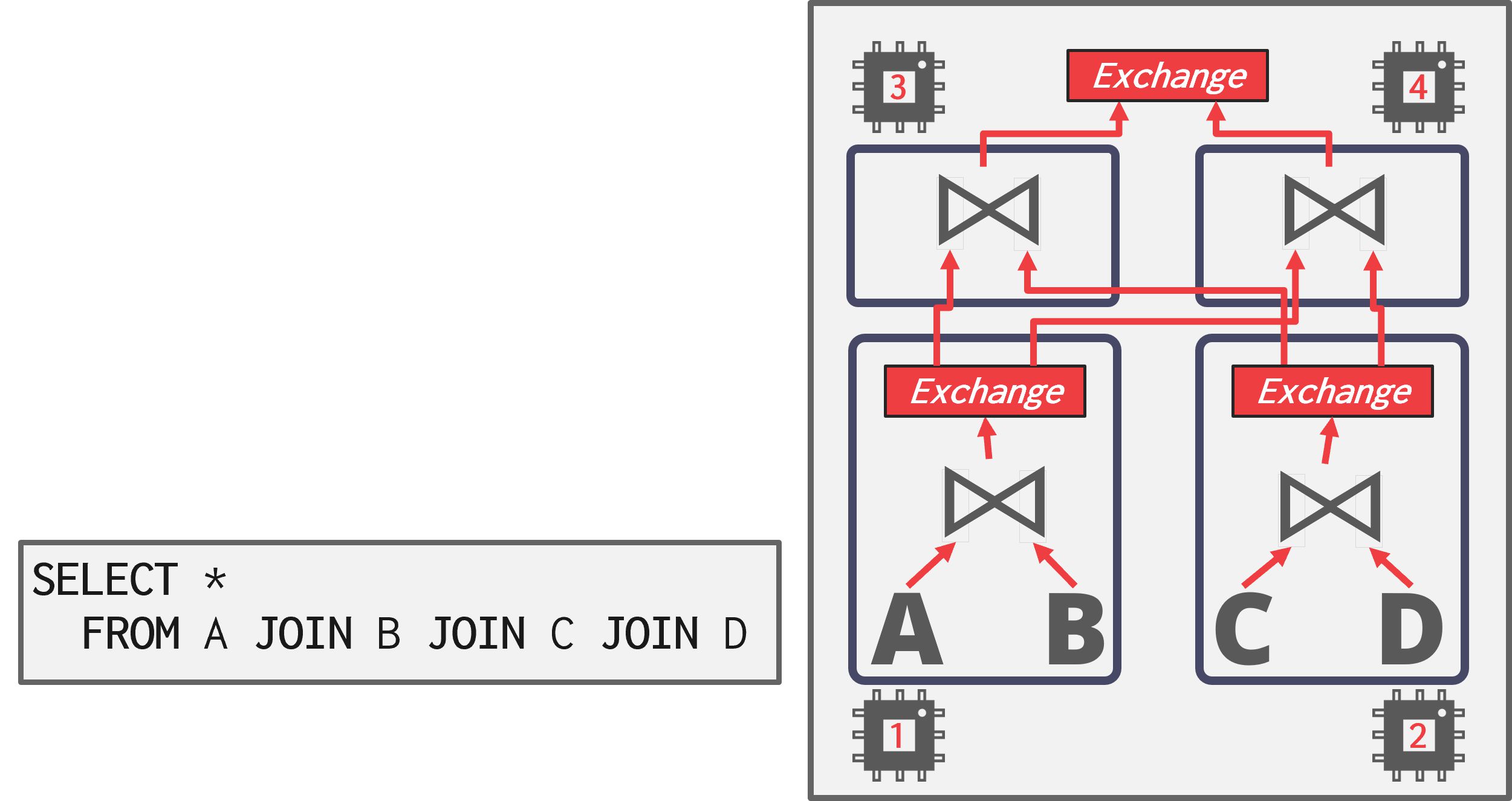
如图,为了在三个表上执行4-way JOIN,查询计划被划分成四个片段。查询计划的不同部分同时运行,类似于操作符间并行。
I/O 并行
如果磁盘始终是主要瓶颈,使用进程/线程并行执行查询将不会提高性能。 DBMS使用I/O并行将数据分布在多个设备上,以优化磁盘带宽/延迟。
多磁盘并行
通过配置操作系统/硬件,将DBMS的文件存储在多个存储设备上:
- 每个数据库多个磁盘
- 一个数据库一个磁盘
- 一个Relation一个磁盘
- 拆分Relation到多个磁盘
有些系统原生支持该功能,DBMS知晓内部文件的分布。
而对于非原生支持的DBMS,可以通过存储设备或RAID配置来实现,但由于存储设置对DBMS来说是透明的,故无法显式地将Worker分配到指定的设备上。
数据库分区
将数据库分割成不相交的子集,分配给不同的磁盘。
- 一些DBMS允许指定每个数据库的磁盘位置。
- 在文件系统级别上很容易实现将不同数据库存储在不同的目录中。
- 变更的日志文件通常是共享的,如果事务需要支持跨数据库更新
逻辑分区:将单个逻辑表(水平/垂直)分割成不相交的物理片段,分别存储/管理。 这种分区理想情况下对应用程序是透明的,无需关注物理存储方式直接访问逻辑表。
我们将在后续介绍分布式数据库时详细介绍。
查询规划与优化
概述
SQL 是声明式的: 查询只告诉DBMS要计算什么,而不是如何计算。因此,DBMS 需要将 SQL 语句翻译成一个可执行的查询计划。 但是,执行查询计划中每个操作符的方法不同(例如,连接算法),这些计划在性能上会有所不同。DBMS 优化器的任务是为给定的查询选择一个最优的计划。
从高层次说,查询优化有两个策略:
- 使用静态规则(或启发式方法) 将查询与已知模式匹配,通过重写查询以消除低效的部分。这些规则无需检查数据本身,但可能需要查阅catalog以理解数据的结构。
- 使用基于成本的搜索来读取数据并估计等效计划的成本。成本模型选择成本最低的计划。
一些系统尝试应用机器学习来提高优化器的准确性和效率,但目前还没实际应用。
逻辑计划与物理计划
逻辑计划: 相当于查询中的关系代数表达式。
物理计划: 定义了一个具体的执行策略,即在查询计划中访问不同操作符的具体路径。
- 物理计划可能取决于处理的数据的物理格式(如排序、压缩)
- 逻辑计划与物理计划之间不总是1:1的映射
优化器负责将逻辑计划转化为优化后的物理计划。 对所有计划进行枚举代价太高,优化器必须限制他们的搜索空间以便高效工作。
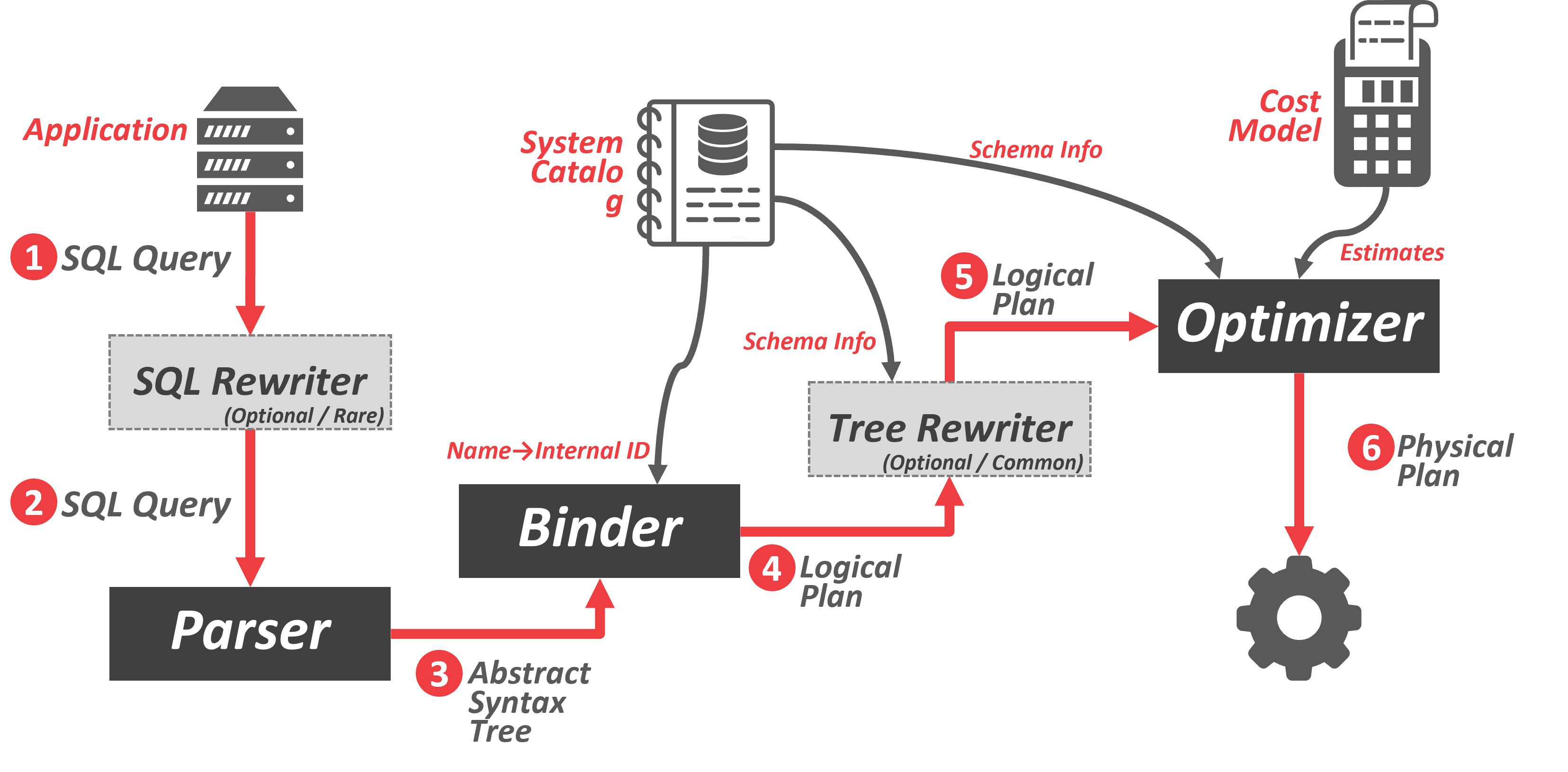 查询执行过程如图:
查询执行过程如图:
- 应用程序连接到数据库系统并发送 SQL 查询, 该查询可能会被重写为不同的格式(如重写别名)
- SQL 字符串被解析成tokens来构建抽象语法树
- Binder通过查询System Catalog,将语法树中的命名对象转换为内部标识符(如表名转化成表内部ID),输出一个逻辑计划(树)
- 然后可以通过树重写器以获取额外的Schema信息(主键, 外键, 类型信息…)
- 逻辑计划被交给优化器,优化器选择最高效的物理计划
- 将物理计划交给引擎执行
逻辑查询优化
原理: 关系代数等价规则
选择操作优化
谓词下推
尽可能早地执行过滤:
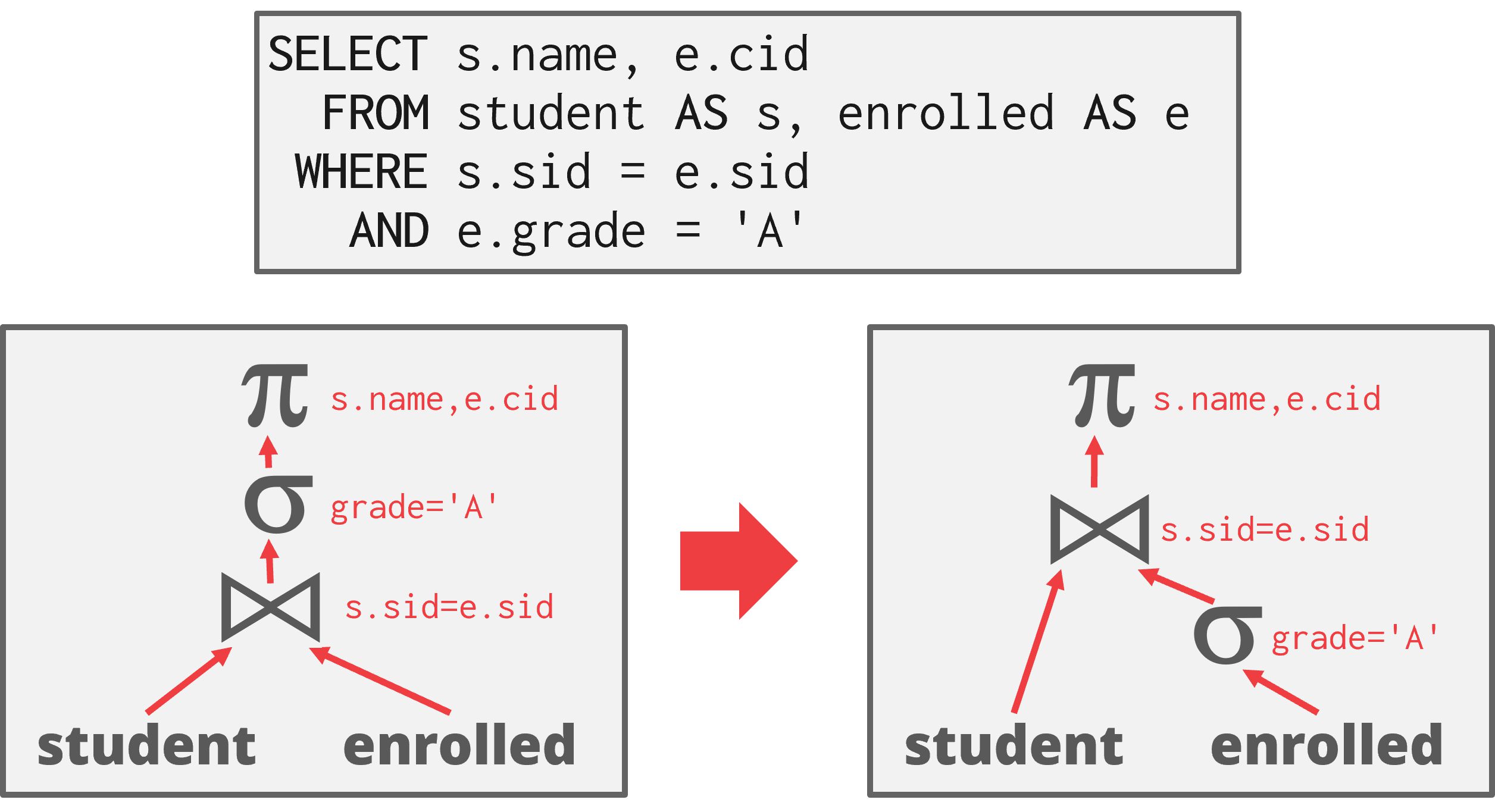 如图,原始查询计划在连接(join)之后执行过滤(filter),通过优化更早地应用过滤,以过滤和传递更少的元组。
如图,原始查询计划在连接(join)之后执行过滤(filter),通过优化更早地应用过滤,以过滤和传递更少的元组。
谓词重排序
- 首先应用最具选择性的谓词
- 选择性(Selectivity, 记为sel),指符合条件元组的比例
分割连接谓词
分解复杂谓词并向下推
投影操作优化
投影下推
尽早执行投影以减小元组, 减小中间结果,减少pipeline breakers进行物化的成本。
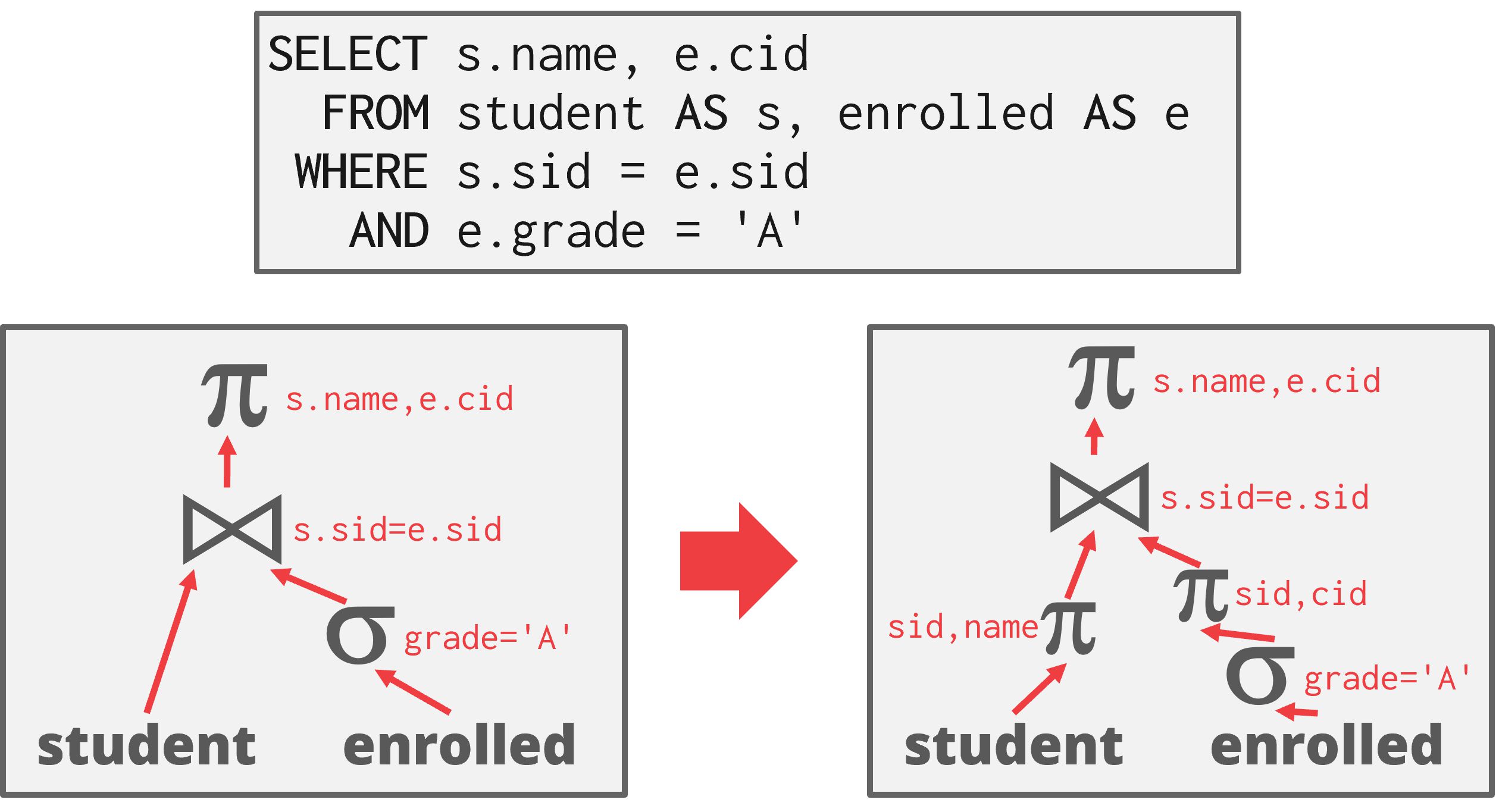 如图,由于查询只请求学生姓名和 ID,DBMS可以在应用连接(join)之前移除除了这两个字段之外的所有列。
如图,由于查询只请求学生姓名和 ID,DBMS可以在应用连接(join)之前移除除了这两个字段之外的所有列。
只投影出需要的属性
排不需要的属性
查询重写优化
移除不必要的谓词
省略在每个元组上都不变的谓词,减少计算成本。
SELECT * FROM A WHERE 1 = 0;
SELECT * FROM A WHERE NOW() IS NULL;
SELECT * FROM A WHERE RANDOM() IS NULL;
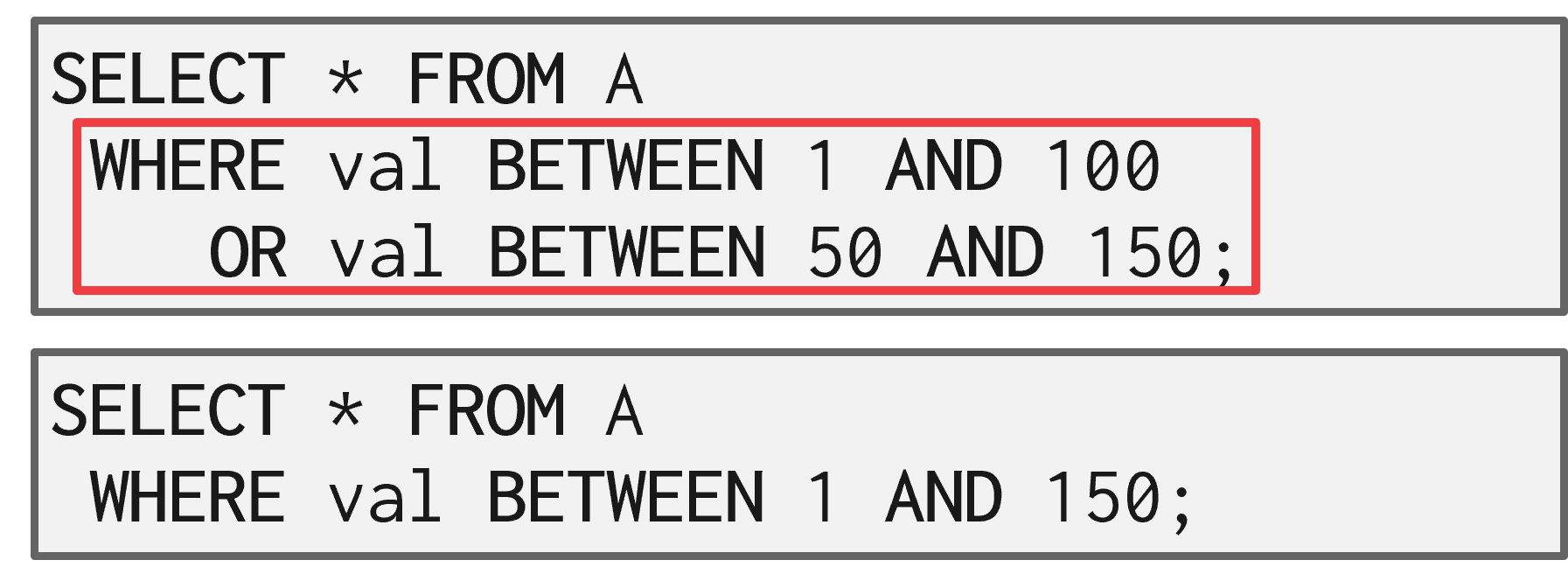
合并谓词
嵌套子查询优化
Flat嵌套子查询
 如图,通过将子查询重写为 JOIN,将嵌套层子查询展平。
如图,通过将子查询重写为 JOIN,将嵌套层子查询展平。
分解嵌套子查询
对于包含子查询的复杂查询,优化器可能会将原始查询分解成多个块,并逐个优化每个块,然后将这些块的结果存储到临时表中供外部查询使用。
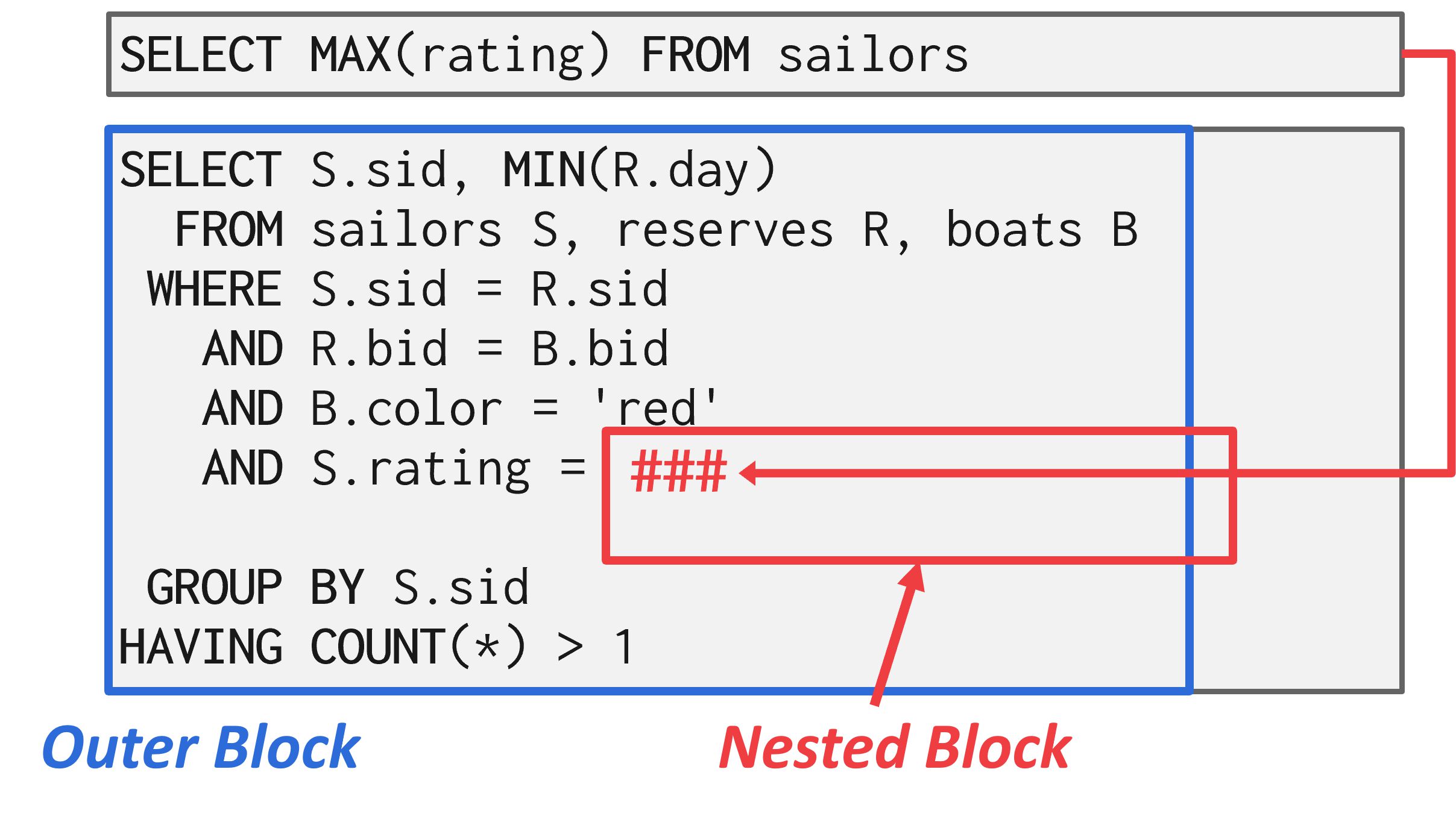 图 6:子查询优化 - 分解 在这个例子中,优化器通过将嵌套查询提取出来形成自己的查询,然后使用这个结果来实现原始查询的逻辑。
图 6:子查询优化 - 分解 在这个例子中,优化器通过将嵌套查询提取出来形成自己的查询,然后使用这个结果来实现原始查询的逻辑。
将带条件的笛卡尔积替换为inner join
笛卡尔积复杂度太高,通过重写为inner join来提高效率。
连接消除
 如图,查询的连接是不必要的,可以重写消除。
如图,查询的连接是不必要的,可以重写消除。
成本估计
DBMS 使用成本模型来估计执行计划的成本,以帮助 DBMS 选择最优的执行计划。
物理成本:
- CPU周期:成本小,但难以估计
- 磁盘I/O(主要):块传输的数量
- 内存:使用的 DRAM 量
- 网络:发送的消息数量
逻辑成本:
- 每个操作符的输出结果集大小
- 每个操作符的算法复杂度
PostgreSQL的成本模型 结合CPU和I/O成本,使用magic number常量来作为权重。 默认设置的权重假设:
- 在内存中处理一个元组的速度比从磁盘读取一个元组快 400 倍
- 顺序I/O 的速度比随机I/O 快 4 倍
MySQL的成本模型
- 结合CPU和I/O成本: COST = PAGE FETCH + W * (RSI CALLS)
- 权重常量及设置也类似。
通过前文介绍的对不同算法的代价估计(见排序与聚合算法、连接算法),以及下文将介绍的利用统计信息估算结果集,我们可以对给定的执行计划进行代价估计。
统计信息
为了估算查询结果集的大小,DBMS 在他们的内部Catalog中维护有关表、属性和索引的内部统计信息(空闲时在后台更新):
- $N_R$:关系 R 中的元组数量
- V(A, R):属性 A 的不重复值的数量
- 选择基数(selection cardinality) = $ N_R/V(A, R) $
- 属性A的最大/最小值
- 包含关系R中元组的磁盘块数
- 关系R中每个元组的字节数。
- 关系R的块因子: 一个磁盘块能容纳关系R中元组的个数
- B+树索引的高度和索引中叶节点的页数
选择运算结果大小的估计
为了方便计算,假设前提: 关系中值是均匀分布的:每个值以同样的概率出现。 则有:
等值谓词
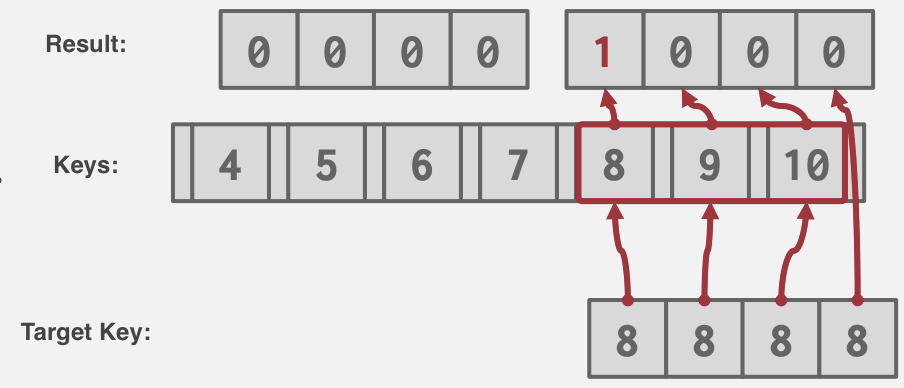
对于谓词WHERE A = a估计选择结果的元组数:
$ N_R/V(A, R) $,即选择基数
范围谓词
已知关系R的属性A的最小值min(A, R)、量大值max(A, R),
则对于谓词WHERE A < v估计选择结果的元组数:
- 若 v < min(A, R): 0
- 若v ≥ max(A, R): $N_R$
- 否则: $ N_R * \frac{v - min(A, R)}{max(A, R) - min(A, R)} $
为了方便计算,还需假设前提: 独立谓词:查询中的各个谓词是概率独立的,则有:
合取谓词
则对于谓词WHERE S1 AND S2 AND ... AND S_n估计选择结果的元组数:
$N_R * \frac{s_1 * s_2 * … * s_n}{N_R^2}$
析取谓词
则对于谓词WHERE S1 OR S2 OR ... OR S_n估计选择结果的元组数:
$N_R * [1 - (1-s_1/N_R)(1-s_2/N_R)…*(1-s_n/N_R)]$
取反谓词
则对于谓词WHERE A != a估计选择结果的元组数:
$N_R * [1 - N_R/V(A, R)]$
选择性 上文公式中$N_R$后跟着的式子也被叫做谓词 P 的选择性(Selectivity, 记为sel),指符合条件元组的比例。
数据分布统计信息
但是,上文提到的假设通常不被真实数据满足。例如,相关属性(如”制造商”与”型号”强相关)打破了谓词独立的假设。 真实数据通常是偏斜的,一些数据库维护了更准确且紧凑的数据结构了解数据分布,帮助成本估计:
直方图
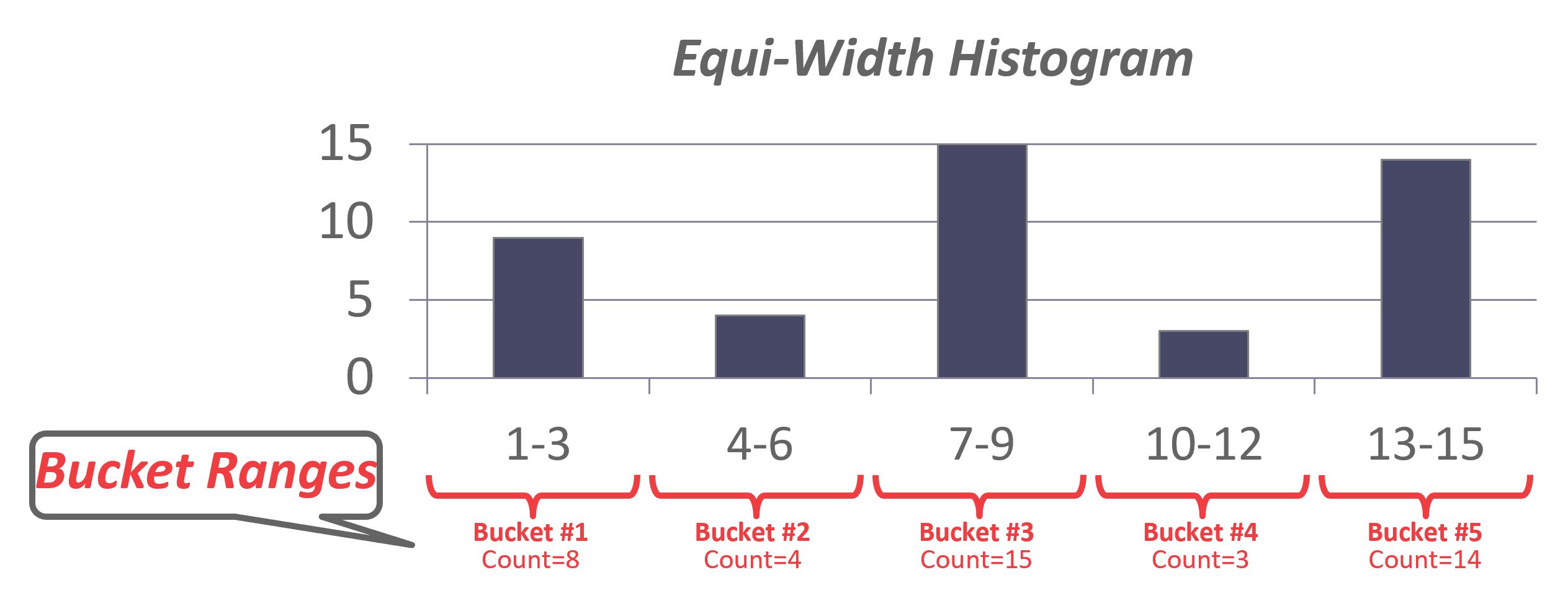
等宽直方图
统计了整个数据集的频次分布。通过将相邻键的计数合并在一起,以减少存储开销。
等深直方图
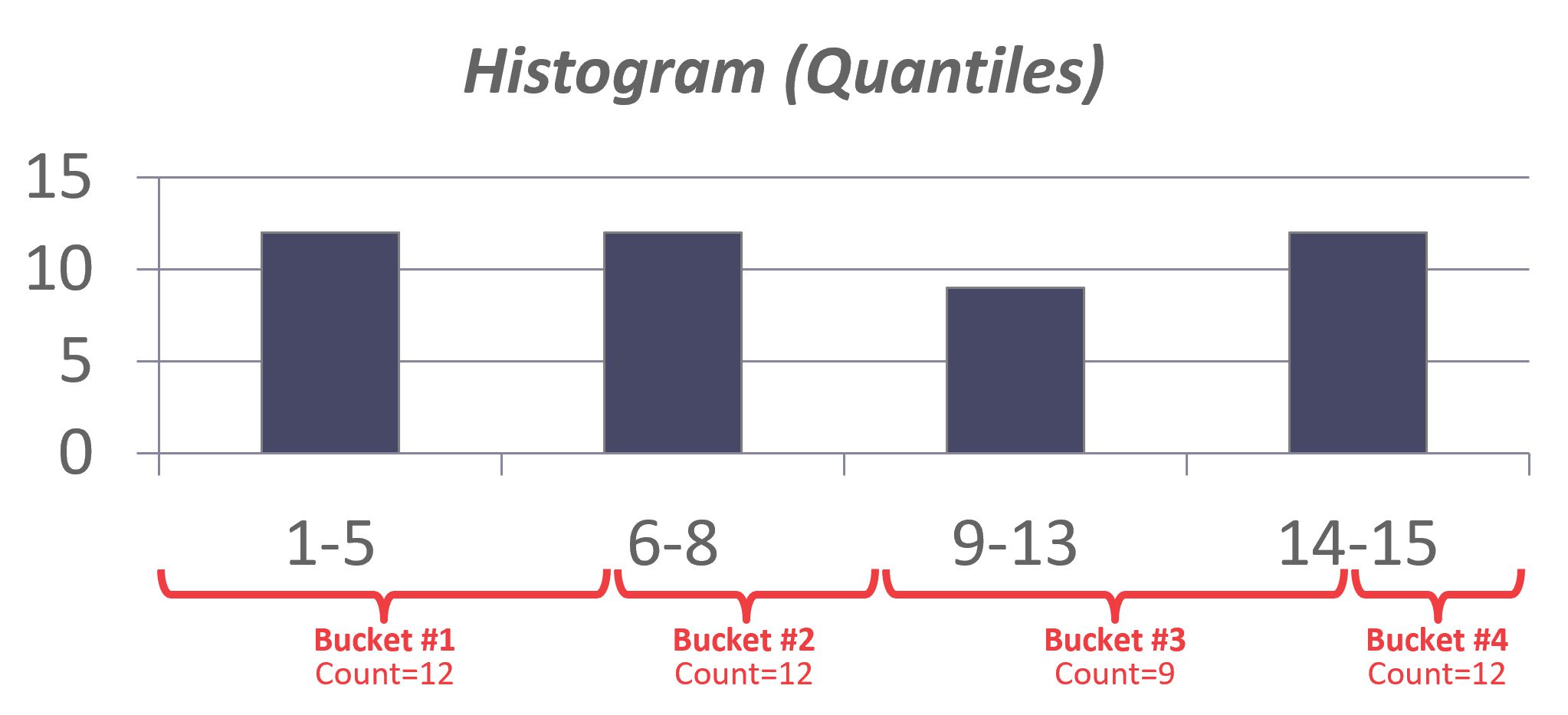 另一种方法是使用等深直方图,它改变桶的范围,使得每个桶的总出现次数大致相同。
另一种方法是使用等深直方图,它改变桶的范围,使得每个桶的总出现次数大致相同。
抽样
将谓词应用于具有类似分布的表的较小副本。当底层表的变更量超过某个阈值(例如,元组的 10%)时,DBMS 会更新样本。
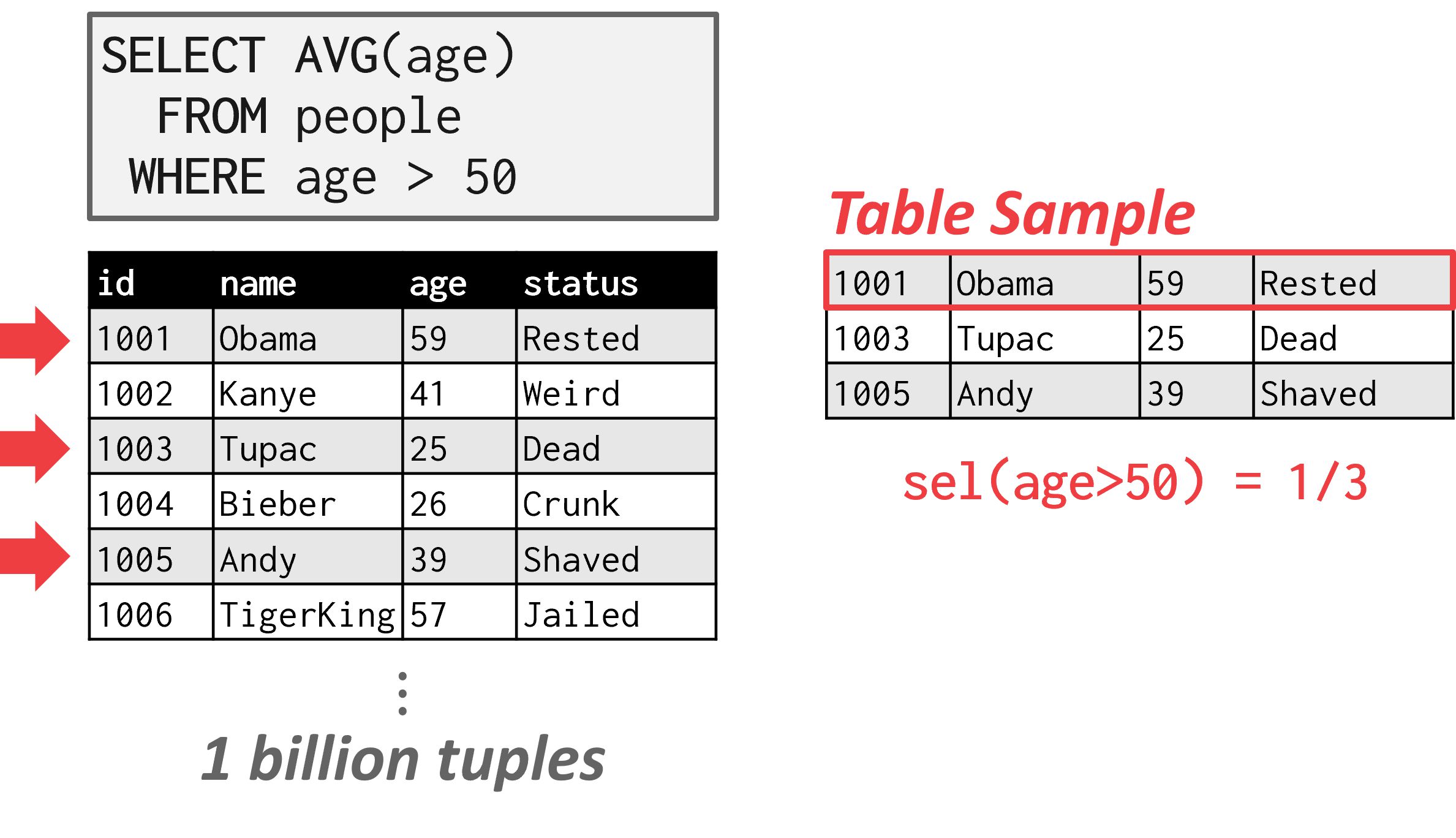 如图,DBMS 可以使用表的一个子集来推导谓词的选择性,帮助成本估计。
如图,DBMS 可以使用表的一个子集来推导谓词的选择性,帮助成本估计。
计划枚举
在执行基于规则的重写之后,DBMS 将枚举查询的不同计划并估计它们的成本。然后在枚举完所有计划或某个超时后,选择查询的最佳计划。
- 步骤1:为每个表选择最佳的访问方法。 表A:顺序扫描,表B:索引扫描等
- 步骤2:枚举所有可能的表连接顺序。 A join B join C,A join C join B等
- 步骤3:确定成本最低的连接顺序。
单关系查询计划
对于单关系查询计划,关键是选择最佳访问方法:
- 顺序扫描
- 二分搜索
- 索引扫描等
大多数新的数据库系统只使用启发式方法来选择访问方法。
对于 OLTP 查询,这尤其简单,因为它们是可搜索的(sargable: Search Argument Able),即存在一个最佳索引可以为查询选择,这也可以通过简单的启发式方法实现。
示例:MySQL
MySQL的访问方法:
Table Scan
- 全表扫描,逐行读取所有记录
- 评估WHERE条件是否满足
SELECT * FROM a
WHERE a.bid < 6
Cost = Page(Table A) + 0.2 * ROW(Table A) 其中:
- 获取 Page(Table A) 统计数据的源码:s->table->file->scan_time(), 含义为:全表扫描页数
- 获取 ROW(Table A) 统计数据的源码: s->table->file->stats.records, 含义为: 表总记录数
- 0.2为 Evaluate query condition 的默认权重
Index Scan
- 全索引扫描,并返回对应的rowid
- 根据rowid读取每一个记录
SELECT * FROM a ORDER BY numCost = Page(INDEX IND_NUM) + ROW(Table A) 其中:
- Page(INDEX IND_NUM) 统计数据的源码: handler::index_only_read_time,通过stats.block_size(块大小), key_length/ref_length(索引信息), records 计算得来
- ROW(Table A) 统计数据的源码: s->table->file->stats.records;
Index Scan(覆盖扫描)
SELECT num FROM a --num列被索引覆盖
ORDER BY num
Cost = Page(INDEX IND_NUM) 统计数据来源同上
Range Scan
SELECT * FROM a
WHERE num > 6 and num <10
- 读取索引范围,并返回对应的rowid
- 根据rowid读取每一个记录 Cost = E_ROW(A) + E_ROW(A) * 0.1 其中:
- E_ROW(A) 统计数据源码在: records_in_range(keynr, * min_key, * max_key), 含义为: 范围中的记录数
- 0.1为 Compare keys/rows 的默认权重
Ref
SELECT * FROM a
WHERE num = 6
注: 有索引、有取值
- 读取索引范围,并返回对应的rowid
- 根据rowid读取每一个记录 Cost = E_ROW(A) + E_ROW(A) * 0.1 统计数据来源和权重同上
多关系查询计划
对于多关系查询计划,随着连接数量的增加,可选计划的数量迅速增长。因此,限制搜索空间以便在合理的时间内找到最优计划非常重要。有两种方法:
- 自底向上:从零开始,然后构建计划以获得你想要的结果。例子:IBM System R, DB2, MySQL, Postgres, 大多数开源 DBMS。
- 自顶向下:从结果开始,然后向下构建以找到最优计划。例子:MSSQL, Greenplum, CockroachDB, Volcano
自底向上优化示例 - System R
- 先使用前文的规则执行初始优化
- 迭代地构建一个“左深”树:
- 将查询分解成块,并为每个块生成逻辑操作符。
- 对于每个逻辑操作符,生成一组实现它的物理操作符。
- 然后使用动态规划来搜索最佳执行计划。
动态规划: 我们不必生成与给定表达式等价的所有查询计划: 假设我们想找到整个表达式的最佳操作符执行顺序,只要我们给查询计划的子集找到了最佳顺序,我们可以在此基础上进一步进行查更大查询计划子集的最佳顺序。
procedure FindBestPlan(S)
if (bestplan[S].cost infinite) // bestplan[S]已经计算好了
return bestplan [S]
if (S只包含一个关系)
根据访向S的最佳方式设置bestplan[S].plan和bestplan[S].cost
else
foreach S 的非空子集S1,且S1 != S:
P1 = FindBestPlan(S1)
P2 = FindBestPlan(S - S1)
A = 连接P1和P2的结果的最佳算法
cost = P1.cost + P2.cost + A的代价
If cost < bestplan[S].cost
bestplan[S].cost = cost
bestplan[S].plan = “执行P1.plan; 执行P2.plan; 利用A连接P1和P2的结果"
return bestplan [S]
自顶向下优化示例 - Volcano
从我们目标逻辑计划开始,执行分支搜索,通过将逻辑操作符转换为物理操作符来构建计划树。
- 在搜索过程中跟踪全局最佳计划
- 在规划过程中对较慢的分支进行剪枝
- 上层可以要求下层的输入保持一定的属性:如有序
并发控制理论
动机
- 丢失更新问题(并发控制):我们如何在同时更新记录时避免竞争条件?
- 持久性问题(恢复):我们如何在停电情况下确保正确的状态?
事务
- 应用程序将多个读写操作组合成一个逻辑单元的一种方式
- DBMS 中变更的基本单位
- 不允许部分事务(即事务必须是原子的)。
示例:从 Andy 的银行账户向他的导师账户转账 100 美元。
- 检查 Andy 是否有 100 美元
- 从他的账户中扣除 100 美元
- 向他的导师账户中添加 100 美元 所有步骤要么都完成,要么都不完成。
简易系统思路
- 使用单个Worker(例如一个线程)一次执行一个事务
- 执行事务时,DBMS 复制整个数据库文件,并在新文件中进行事务更改
- 如果事务成功,则新文件成为当前数据库文件
- 如果事务失败,DBMS 丢弃新文件,事务的更改均未保存
这种方法速度慢,因为它不允许并发事务,并且需要为每个事务复制整个数据库文件。
操作的交替执行可能导致:
- 临时不一致性:不可避免,但不是问题。
- 永久不一致性:不可接受,会导致数据正确性和完整性问题。
这里讨论的事务的范围仅在数据库内部,不能对外部世界回滚更改。例如,如果事务触发电子邮件发送,但最终事务ABORT,DBMS 无法撤回邮件。
定义
形式上,数据库可以表示为一组命名的数据对象(A、B、C…)。这些对象可以是属性、元组、页面、表,甚至是数据库。我们将讨论的算法适用于任何相同类型类型的对象。
事务的边界由客户端定义。 在 SQL 中,事务从 BEGIN 命令开始。 事务的结果要么是 COMMIT,要么是 ABORT。 对于 COMMIT,事务的所有修改要么全部保存到数据库中,或者 DBMS 拒绝并改为ABORT。 对于 ABORT,事务的所有更改都将被Undo,就像事务从未发生过一样。ABORT可以是自我造成的,也可以是由 DBMS 引起的。
确保数据库正确性的标准由 ACID 首字母缩写词给出。
- 原子性(Atomicity):确保事务中的所有操作要么全部发生,要么都不发生。“全部或全不”
- 一致性(Consistency):如果每个事务都是一致的,并且数据库在事务开始时是一致的,那么数据库在事务完成时保证是一致的。数据一致性意味着它满足所有验证规则,如约束、级联和触发器。“数据是正确的”
- 隔离性(Isolation):隔离性意味着当事务执行时,它应该有一种错觉,即它是系统中唯一运行的事务。隔离性确保并发事务的执行应该与事务的顺序执行产生相同的数据库状态。“由我独占”
- 持久性(Durability):如果事务提交,那么它对数据库的效果应该持久化。“我能幸免“
原子性
DBMS 保证事务是原子性的。事务要么执行其所有操作,要么不执行任何操作。有两种方法可以实现这一点:
日志
记录 DBMS 记录所有操作,以便在事务ABORT时撤销(undo)这些操作。 它在内存和磁盘上都维护Undo记录(undo records)。 出于审计和效率原因,几乎所有现代系统都使用日志记录。
Shadow Paging
DBMS 为事务修改的页面制作副本,事务对这些副本进行更改。 只有当事务提交时,页面才会变得可见。 这种方法通常在运行时比基于日志的 DBMS 慢。 然而,一个好处是,如果只是单线程操作,就不需要日志记录,因此在事务修改数据库时对磁盘的写入较少。 这也使得恢复变得简单,因为只需要删除未提交事务的所有页面。 通常更倾向于更好的运行时性能而不是更好的恢复性能,因此这种方法在实践中很少使用。
一致性
从高层次上看,一致性意味着数据库所代表的“世界”在逻辑上是正确的。应用程序关于数据的所有即查询都将返回逻辑上正确的结果。一致性有两种概念:
- 数据库一致性:数据库准确地代表了它所建模的现实世界实体,并遵循完整性约束。(例如,一个人的年龄不能是负数)。此外,未来的事务应该在数据库内看到过去已提交事务的效果。
- 事务一致性:如果数据库在事务开始前是一致的,那么它在事务完成后也将是一致的。确保事务一致性是应用程序的责任。
隔离性
DBMS 提供事务的幻觉: 它们在系统中独自运行。它们看不到并发事务的影响。相当于一个事务按串行执行的系统。但为了实现更好的性能,DBMS 必须在保持隔离幻觉的同时交替执行并发事务的操作。
并发控制
并发控制协议: DBMS 决定在运行时如何正确交替执行多个事务。 类别:
- 悲观的:DBMS 假设事务会发生冲突,所以要先获取lock。
- 乐观的:DBMS 假设事务之间的冲突很少,所以它选择在事务提交后发生冲突时处理。
DBMS 执行操作的顺序称为执行调度。我们希望交替执行事务以最大化并发性,同时确保输出是“正确的”。并发控制协议的目标是生成一个与某个串行执行等价的执行调度:
- 串行调度:不交替不同事务的操作的调度
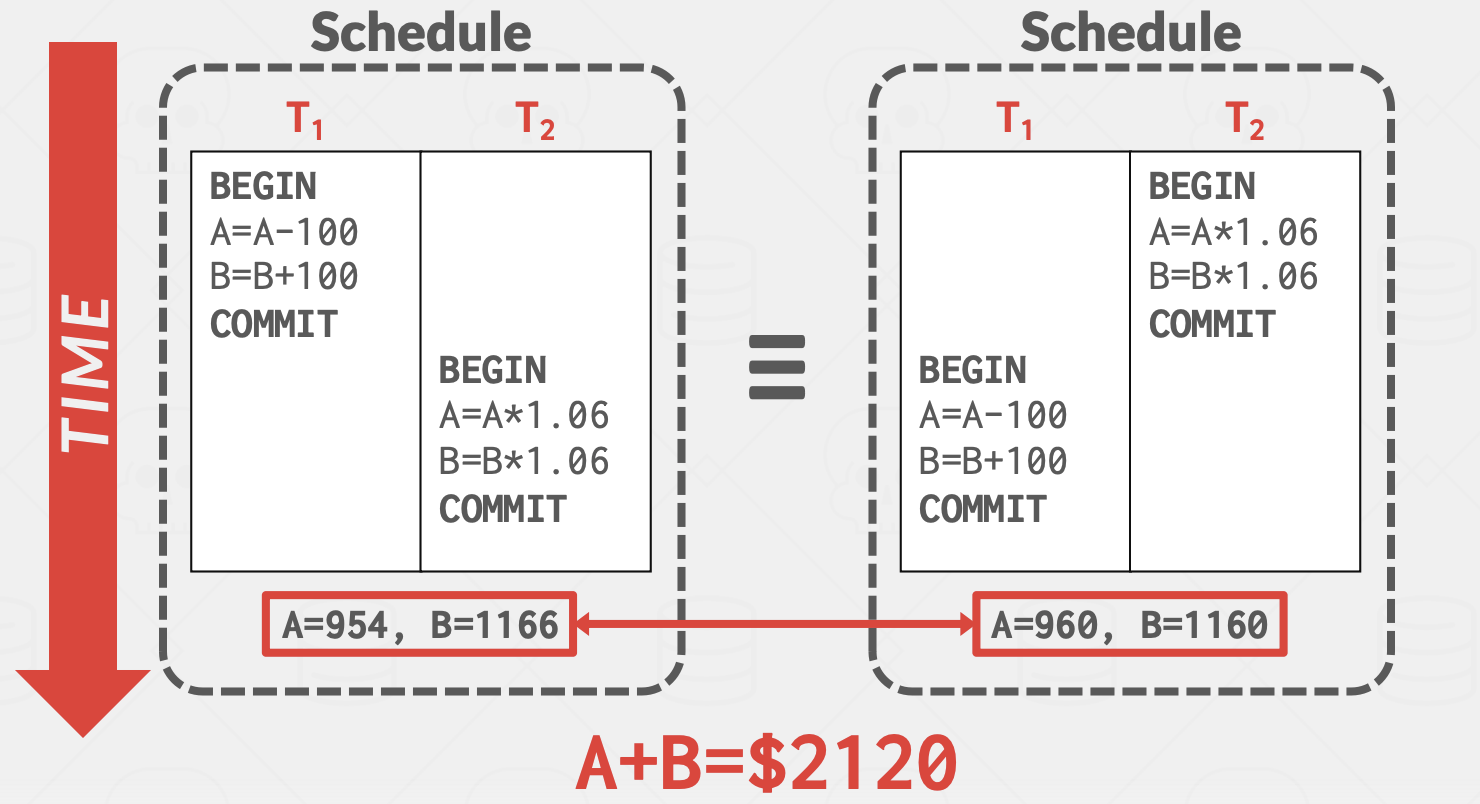
- 等价调度:对于任何数据库状态,如果执行第一个调度的效果与执行第二个调度的效果相同,则两个调度是等价的
- 可串行化调度:与某个串行执行等价的调度。不同的串行执行可能会产生不同的结果,但所有结果都被认为是“正确的”。上图结果与串行调度相同,所以也是可串行化调度。
两个操作间发生冲突的条件:
- 操作属于不同的事务
- 它们在同一对象上执行,并且至少有一个操作是写操作
冲突有三种变体:
- 读-写冲突(“不可重复读”):事务在多次读取同一对象时无法获得相同的值。
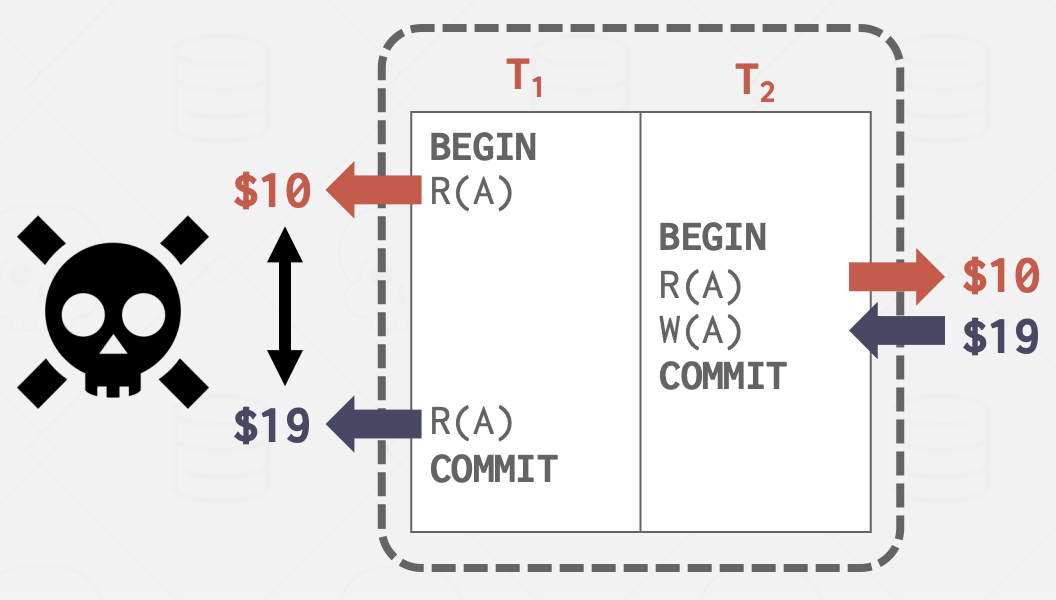
- 写-读冲突(“脏读”):事务在另一个事务提交更改之前看到了该事务的写效果。
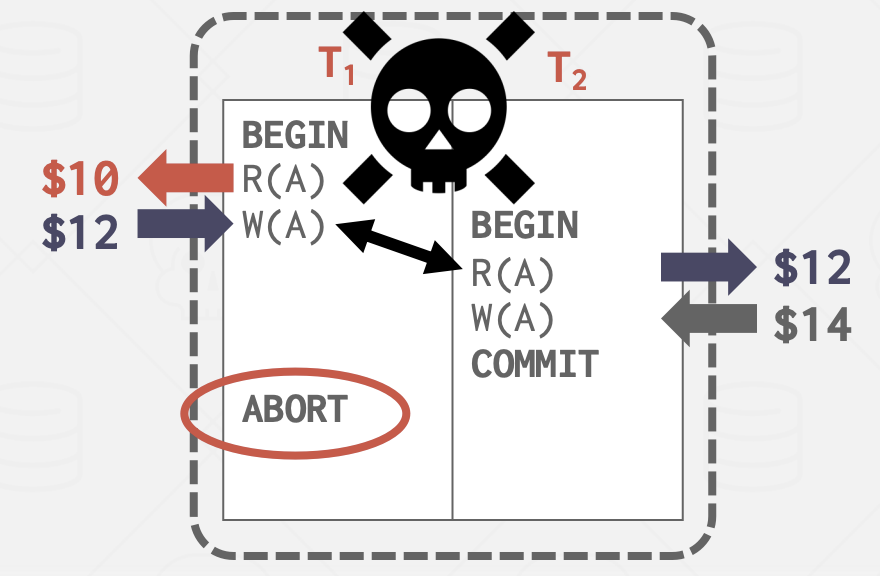
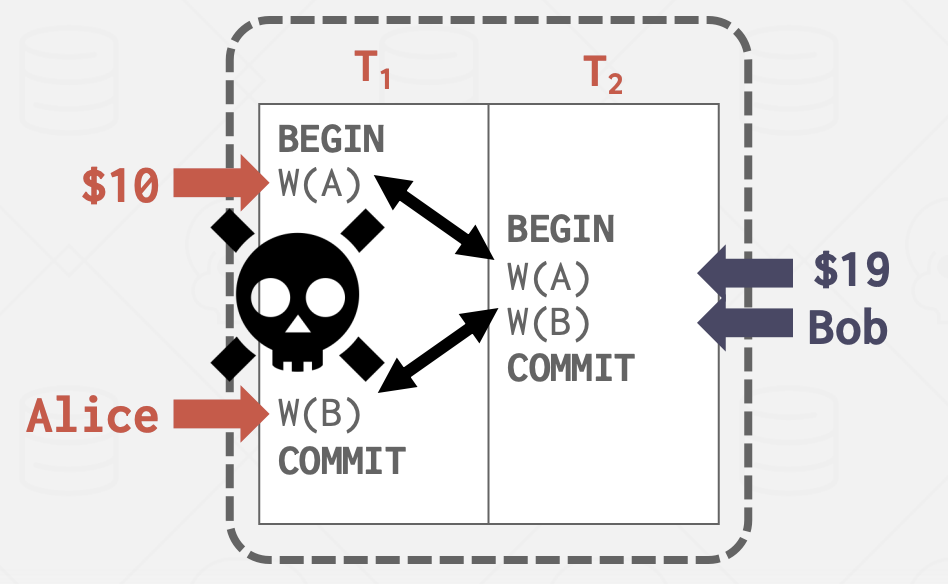
- 写-写冲突(“丢失更新”):一个事务覆盖了另一个并发事务未提交的数据。
冲突可串行化
冲突等价: 调度S可以经过一系列非冲突指令顺序交换转换成S’,则称S与S’是冲突等价的。
如果调度 S 与某个串行调度冲突等价,则称调度 S 是冲突可串行化的。
验证调度是否是冲突可串行化
依赖图(优先级图):
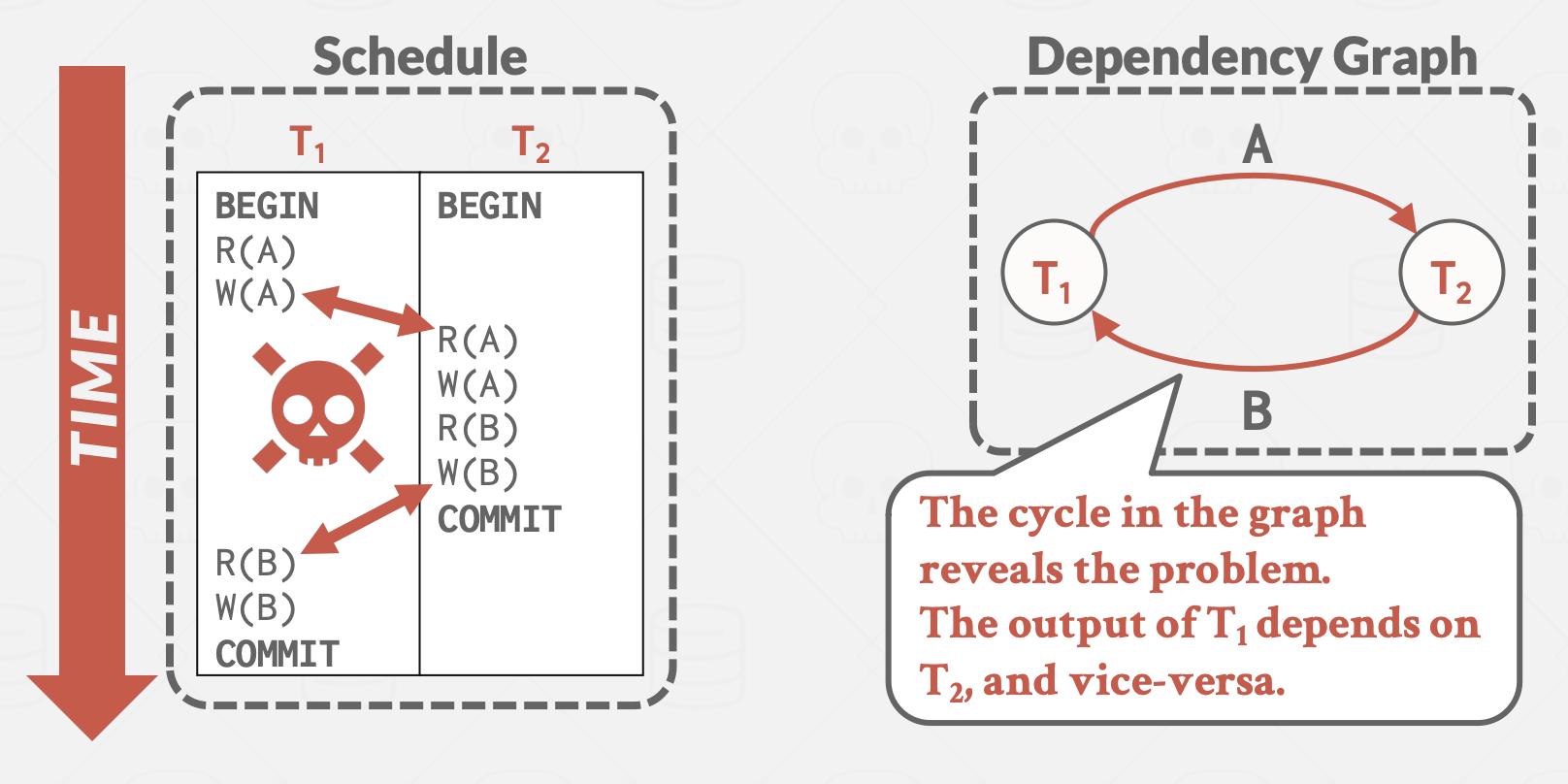
每个事务是图中的一个节点。 如果满足以下条件,则画出从节点 Ti 到 Tj 的有向边:
- 事务 Ti 的操作 Oi 与事务 Tj 的操作 Oj 发生冲突
- 并且 Oi 在调度中先于 Oj 发生
如果依赖图是无环的,则调度是冲突可串行化的。
持久性
所有已提交事务的更改必须在崩溃或重启后保持持久(即,持久化)。 DBMS 可以通过使用日志记录或影子分页来确保所有更改都是持久的。 这通常需要将已提交的事务存储在非易失性内存中。
两阶段锁
事务锁
前文的可串行化假设: 我们在构建调度时知道所有要发生的所有事务的读和写操作
但我们需要: 动态保证事务的执行调度是可串行化的。
- DBMS使用锁来动态生成事务的执行调度
- DBMS包含一个集中的锁管理器,它决定事务是否可以获取锁。
类型:
- 共享锁(S-LOCK):共享锁允许多个事务同时读取同一个对象。如果一个事务持有共享锁,那么另一个事务也可以获取相同的共享锁。
- 排他锁(X-LOCK):排他锁允许事务修改对象。这种锁阻止其他事务获取该对象的任何其他锁(S-LOCK或X-LOCK)。一次只能有一个事务持有排他锁。
锁管理器:
- 事务必须向锁管理器请求锁(或升级)。
- 锁管理器根据其他事务当前持有的锁来授予或阻止请求。
- 事务在不再需要它们时必须释放锁,以释放对象。
- 锁管理器更新其内部锁表,记录哪些事务持有哪些锁,以及哪些事务正在等待获取锁。
内部锁表不需要持久化,因为在DBMS崩溃时任何运行中的事务都会自动ABORT。
两阶段锁
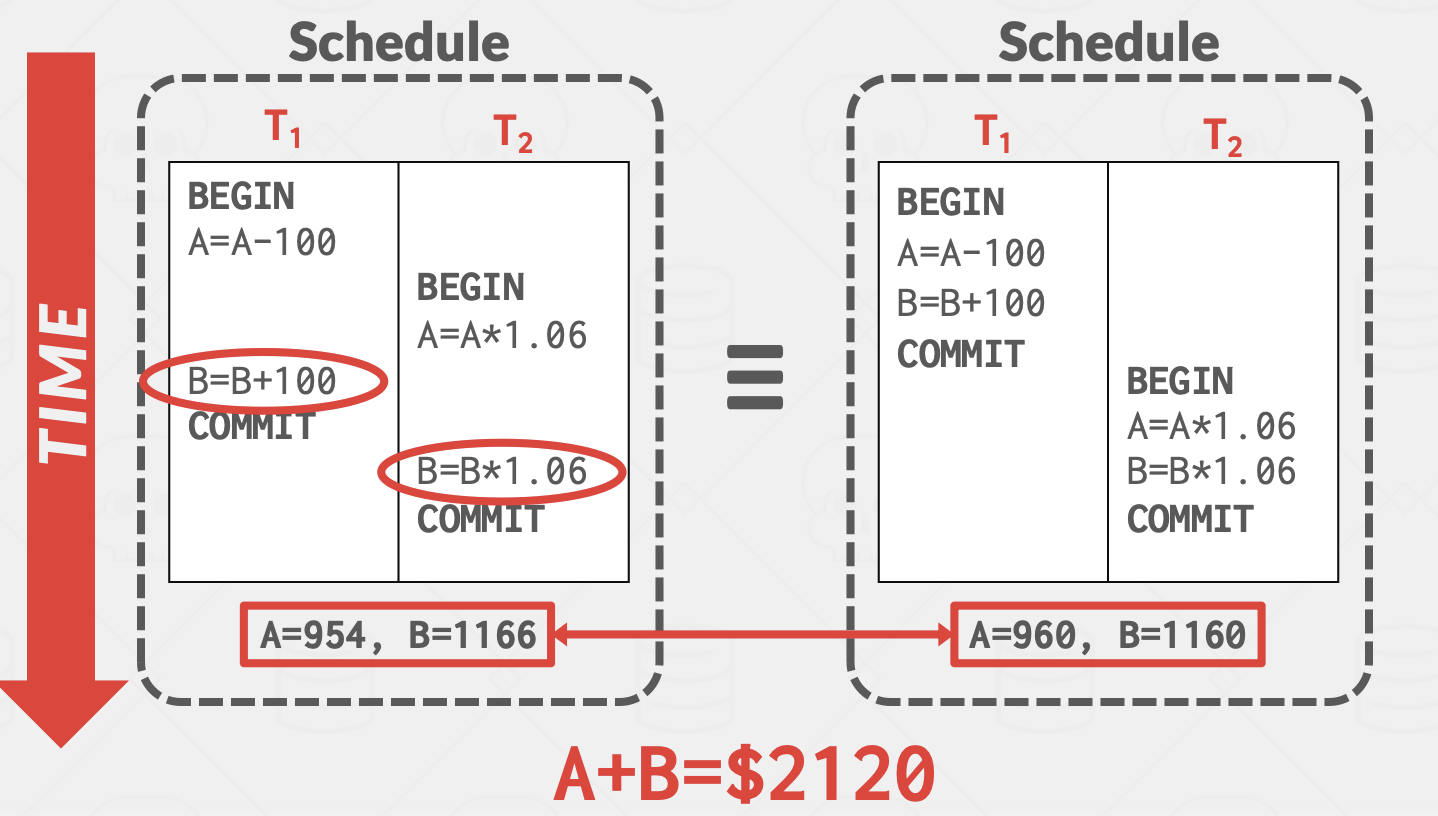
如果随意lock和unlock对象,会有问题:
 T2看到T1: A更改后的值,B更改前的值.
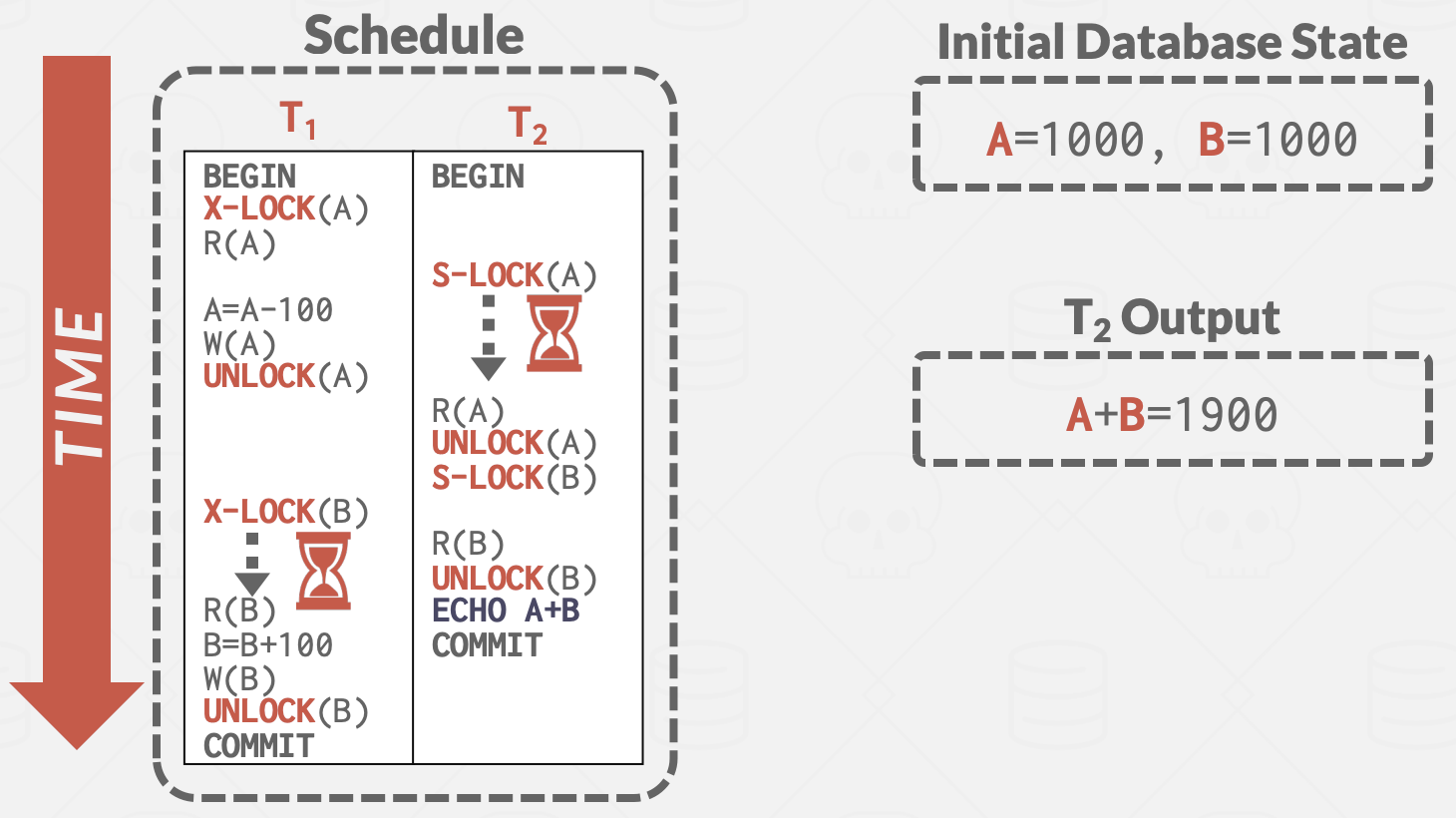
T2看到T1: A更改后的值,B更改前的值.
锁需要与一种并发控制协议相结合,以确保以满足正确性保证的方式使用锁。 两阶段锁(Two-Phase Locking, 2PL)是一种悲观的并发控制协议,它使用锁来动态确定事务是否被允许访问数据库中的对象。
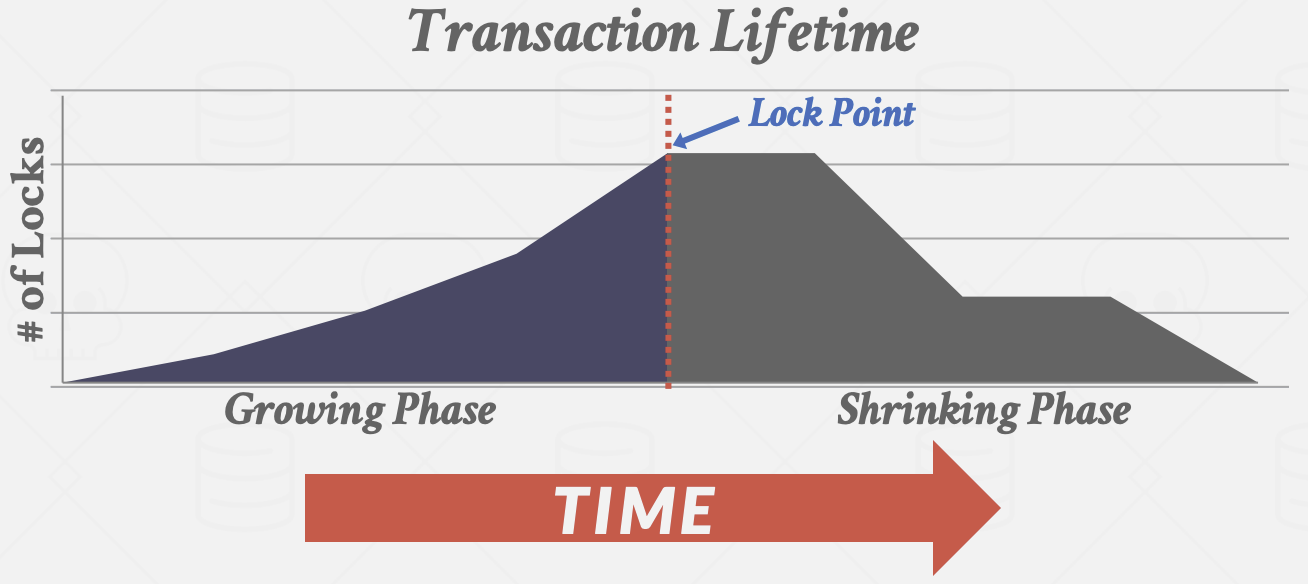
- 阶段#1 - Growing(加锁/生长阶段):在Growing阶段,每个事务从DBMS的锁管理器请求它所需的锁。锁管理器授予/拒绝这些锁请求。
- 阶段#2 - Shrinking(解锁/衰退阶段):事务从释放第一个锁开始立即进入Shrinking阶段。该阶段事务只允许释放锁,不允许获取新的锁。
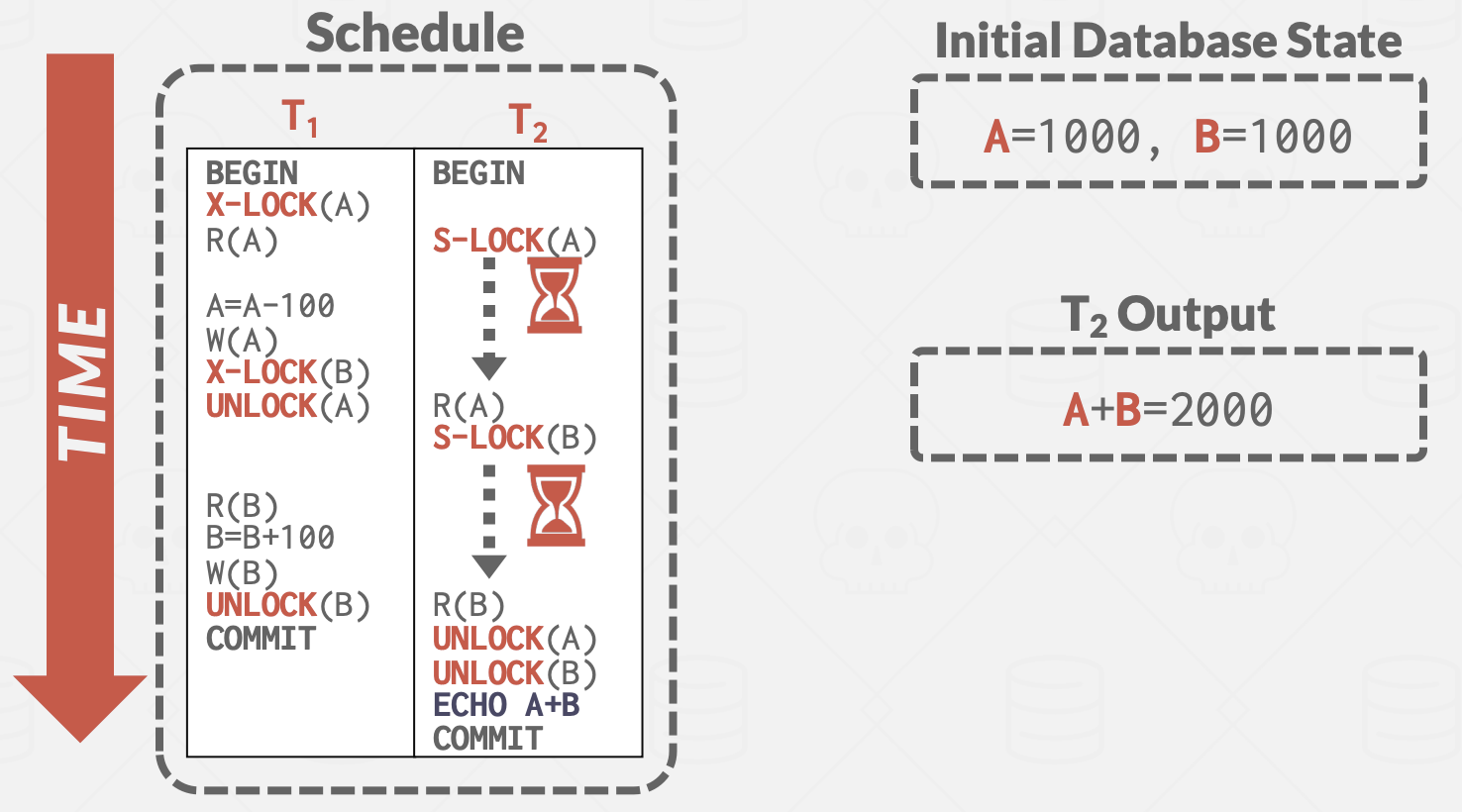
- +仅凭2PL就足以保证冲突可串行化: 多个事务根据它们的封锁点(Lock Point)进行排序,而这个顺序就是事务的一个可串行化顺序
- -仍然可能存在脏读,并且也可能导致死锁
- -可能导致不可恢复调度的级联ABORT: 一个事务ABORT后,另一个事务必须回滚,导致工作浪费。
- -可能会限制并发性: 即便还有其它可串行化的调度,但不会被2PL允许。
强严格两阶段锁 Strong Strict 2PL,也称为Rigorous 2PL。是2PL的一个变体,其中事务只在提交时释放所有锁。
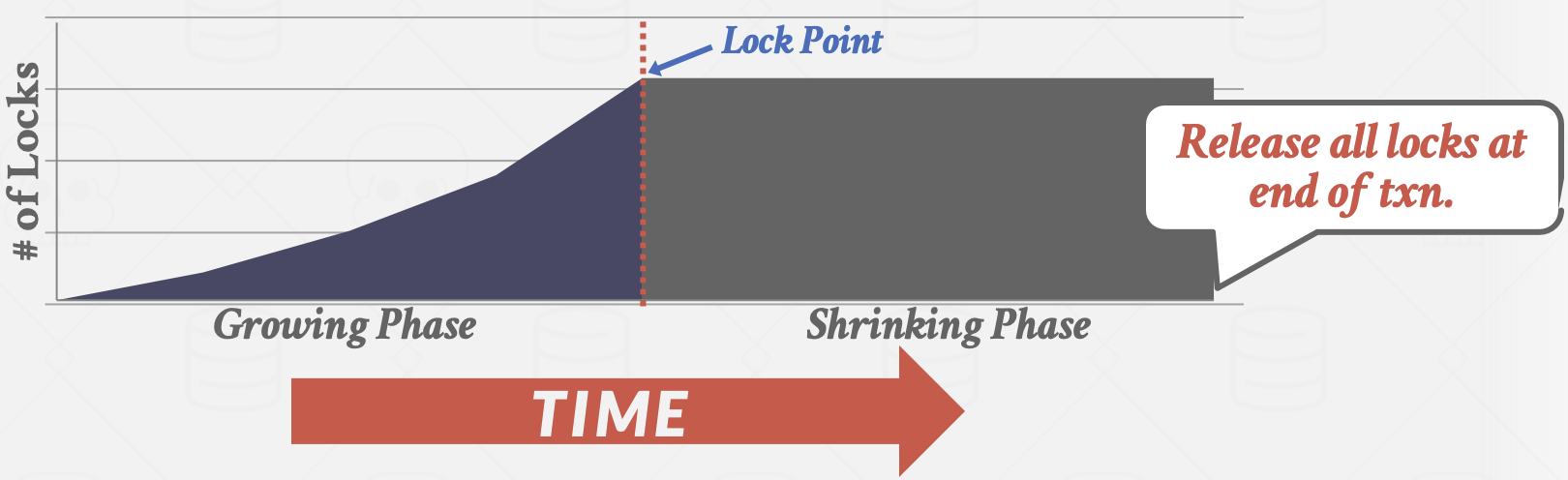
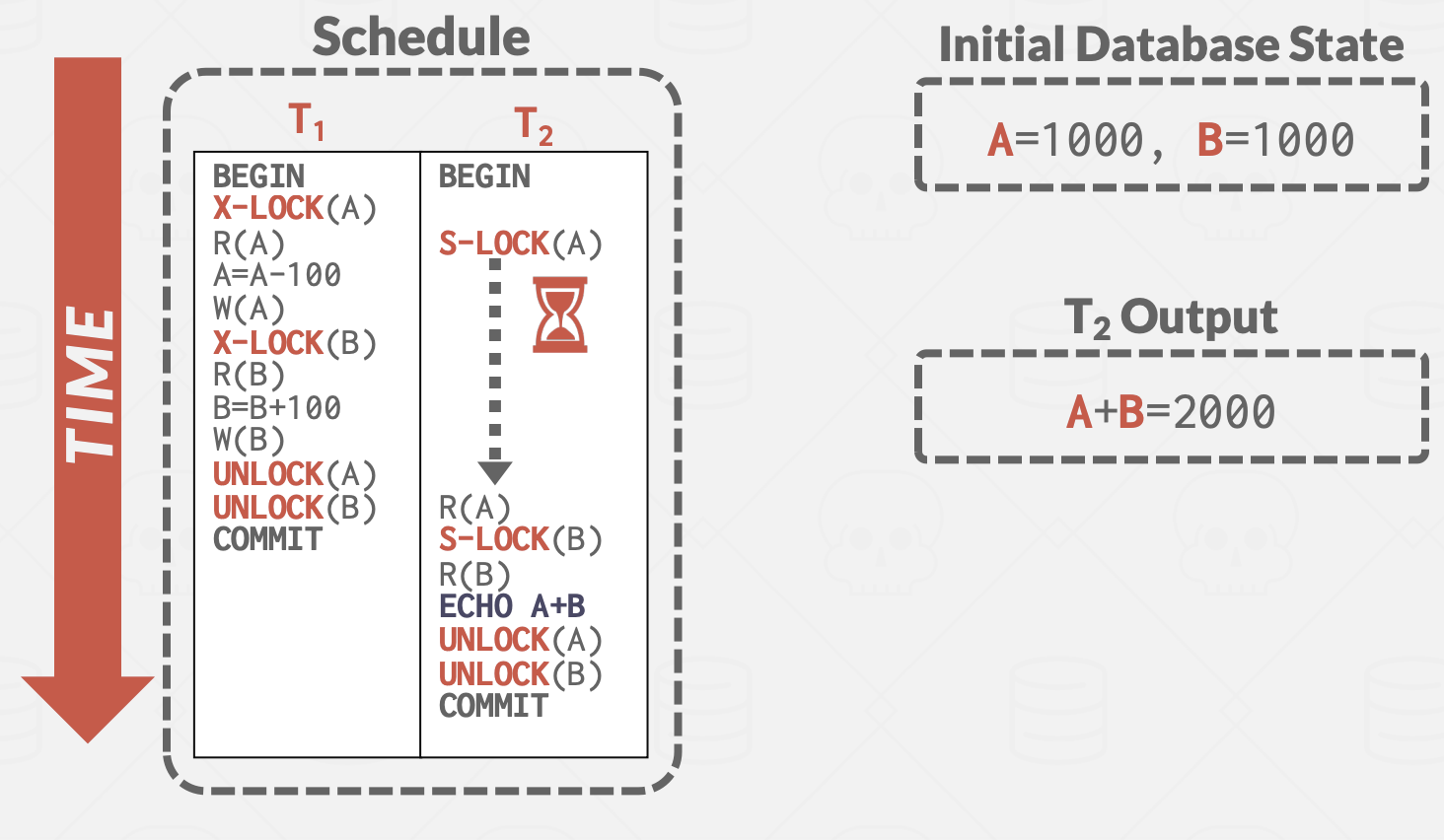
- +解决了前面提到的级联ABORT问题(写事务提交才释放锁,避免依赖事物提交前读取同一对象)
- +仅需将修改元组恢复为原始值,就可以撤销ABORT事务的更改(无需查找事务依赖)
- -严格2PL生成的调度更加谨慎/悲观,限制了并发性
调度的包含关系: 串行调度 ⊂ 强严格2PL ⊂ 冲突可串行化调度 ⊂ 所有调度
死锁处理
死锁是事务等待彼此释放锁的循环。处理2PL中的死锁有两种方法:检测和预防。
死锁检测
为了检测死锁,DBMS创建一个等待图(waits-for graph):
- 事务是节点
- 如果事务Ti等待事务Tj释放锁,则存在从Ti到Tj的有向边
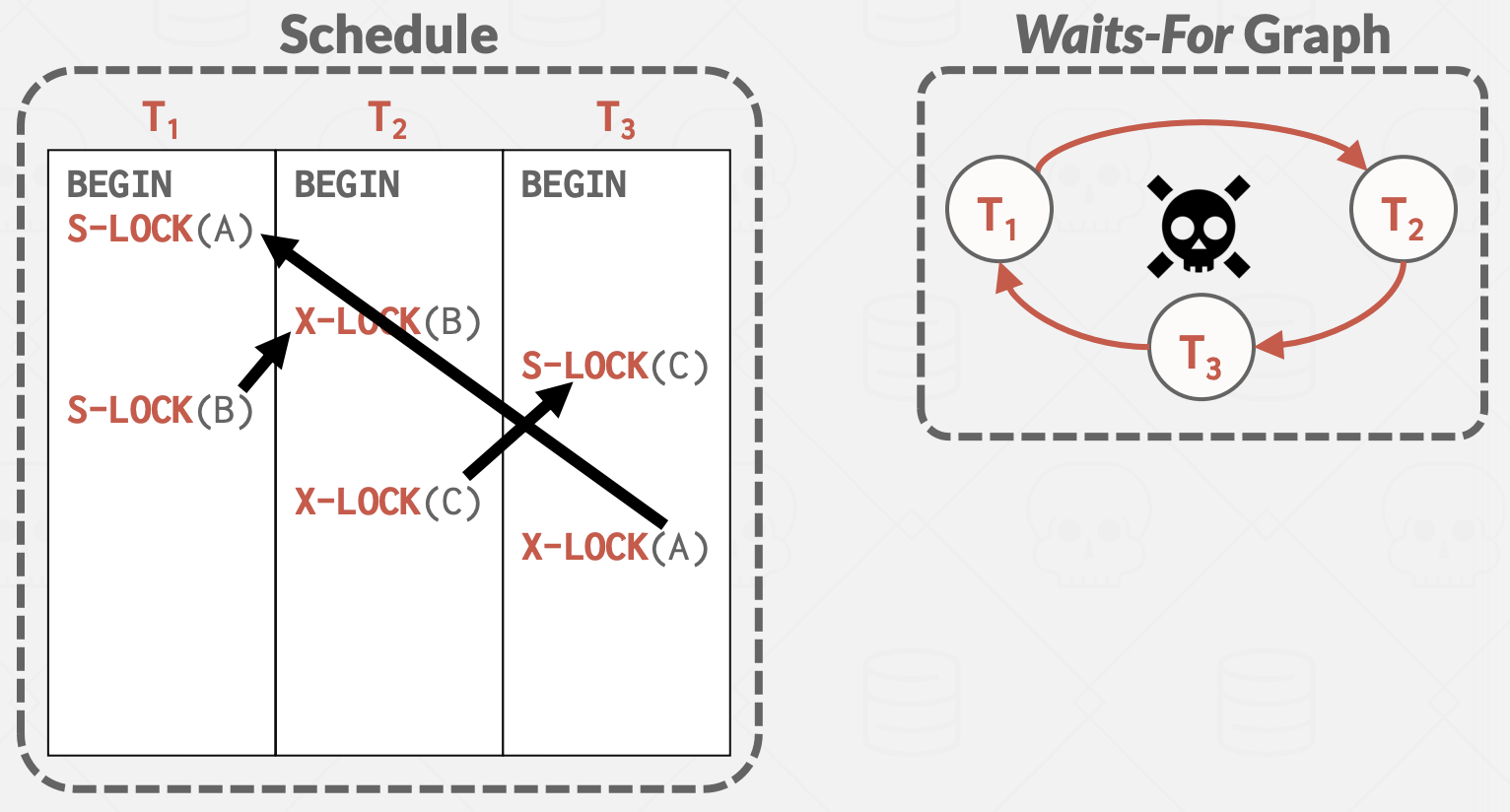
系统会定期检查等待图中的循环(通常使用后台线程),然后决定如何打破它。 在构建图时无需latch,因为如果DBMS在一次传递中错过了死锁,它将在随后的传递中找到它。 权衡: 死锁检查的频率(使用CPU周期)和 死锁被打破的等待时间。
当DBMS检测到死锁时,它会选择和ABORT一个“受害者”事务以打破循环。 受害者事务将根据应用程序的调用方式重新启动或ABORT。 选择依据:
- 按年龄(最新或最老的时间戳)。
- 按进度(已执行的查询最少/最多)。
- 已锁的对象数量。
- 需要与其一起回滚的事务数量。
- 事务过去重启的次数(避免饥饿)。
许多系统组合考虑这些因素。
在选择受害者事务进行ABORT后,DBMS还可以决定回滚事务更改的程度:
- 回滚整个事务
- 只回滚足以打破死锁的查询
死锁预防
Deadlock Prevention 2PL: 在事务可能引起死锁之前阻止它们。 当事务尝试获取另一个事务持有的锁时(这可能导致死锁),DBMS可以杀死其中一个。 为了实现这一点,事务被分配优先级(可能基于时间戳,较旧的事务具有更高的优先级)。 由于等待锁时只允许一种方向,可以保证不出现死锁。 当事务重新启动时,DBMS重用相同的时间戳。
杀死事务的方式:
- 等待-死亡(“老者等待年轻者”):如果请求事务的优先级高于持有锁的事务,则请求事务等待;优先级较低,则请求事务ABORT(死亡)。
- 受伤-等待(“年轻者等待老者”):如果请求事务的优先级高于持有锁的事务,持有锁的事务ABORT(受伤)并释放锁;优先级较低则请求事务等待。
协议命名X-Y,指如果请求事务具有更高的优先级,执行X,如果请求事务具有较低的优先级,它将执行Y。
锁粒度
如果一个事务想要更新十亿个元组,它必须向DBMS的锁管理器请求十亿个锁。这很慢,因为事务在获取/释放锁时必须在锁管理器的内部锁表数据结构中获取latch。
或者,如果一个事务只需要读取一个值,却锁了整个表,那么并行性的机会就会减少。
为了权衡,DBMS使用 锁层次结构 来同时处理不同粒度级别的锁。
当事务在某个层次结构中获取对象的锁时,它隐式地获取了所有其子对象的锁。
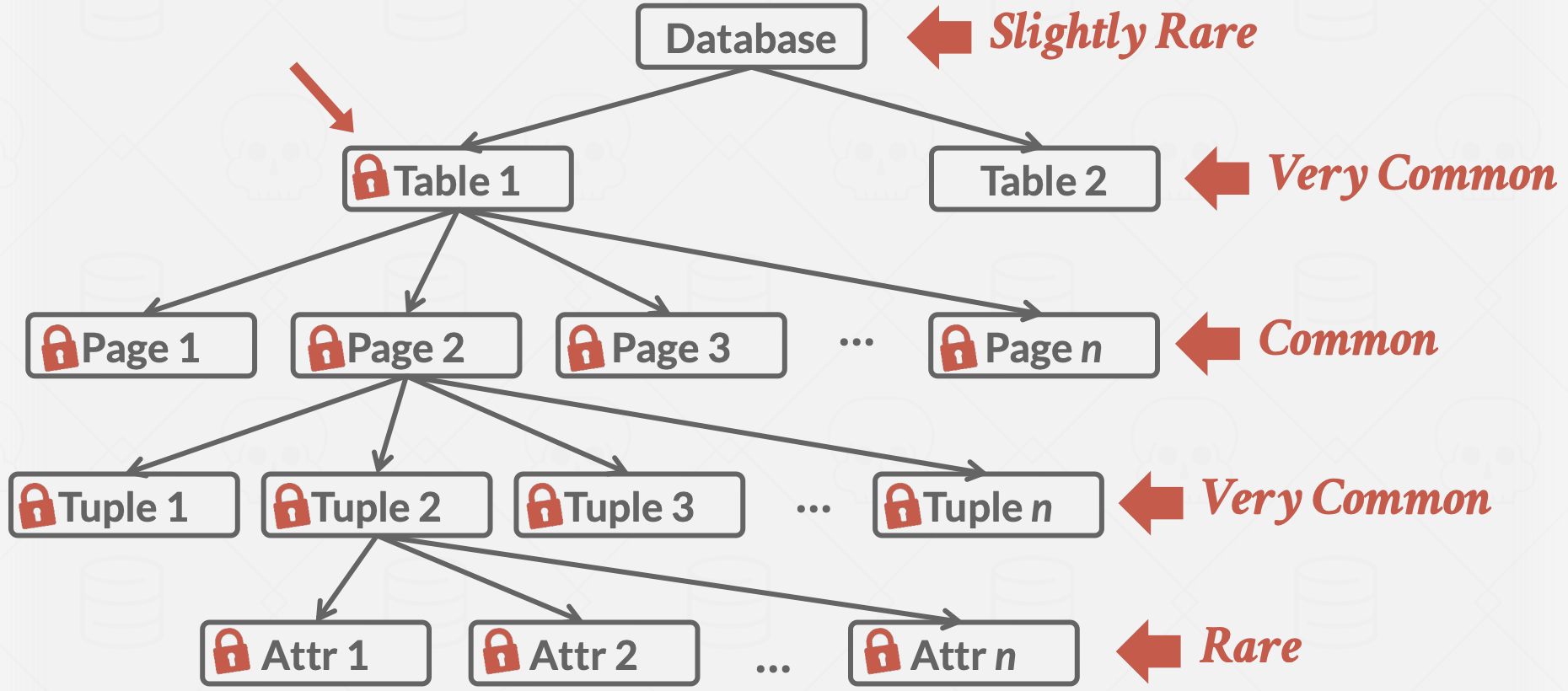
数据库锁层次结构:
- 数据库级别(很少见)
- 表级别(非常常见)
- 页面级别(常见)
- 元组级别(非常常见)
- 属性级别(罕见)
意向锁
如果事务正在使用元组级锁,则其他事务不能获取页面级(及更高级别)的锁。为了避免搜索子树才能判定是否可加锁: 意向锁是隐式锁,声明在更低级别持有显式锁。 在一个结点显式加锁之前,该结点的全部祖先结点均加上相应类型的意向锁。 类别:
- 意向共享(Intention-Shared, IS):表示在更低级别有共享锁的显式锁。
- 意向排他(Intention-Exclusive, IX):表示在更低级别有排他或共享锁的显式锁。
- 共享意向排他(Shared and Intention-Exclusive, SIX):即S-Lock与IX的组合,以该节点为根的子树有显式的共享锁,并且在更低级别有排他锁。
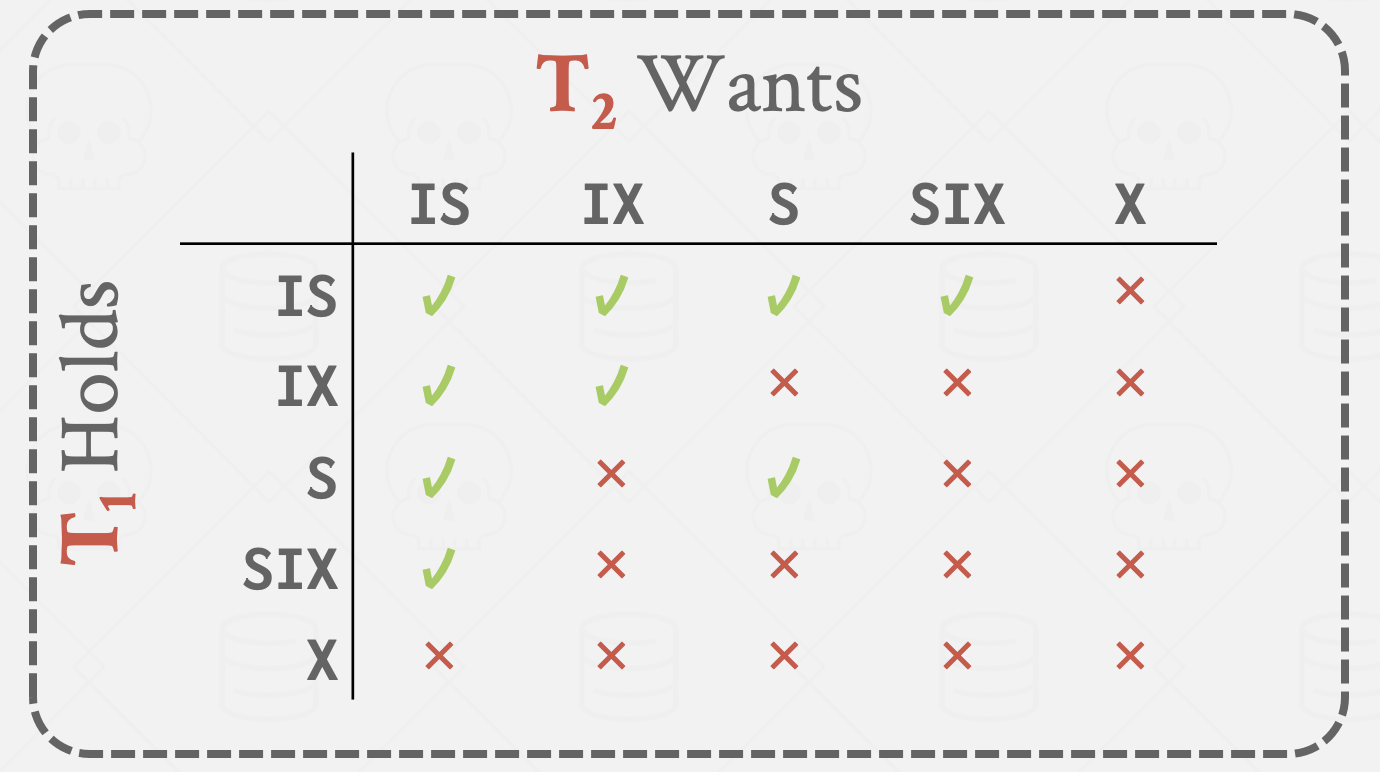
多粒度加锁协议
- 必须遵守锁间的相容性规则;
- 根节点必须首先加锁,可以加任意类型的锁;
- 仅当事务对当前节点的父节点持有IX或IS锁时,才可以对当前节点加S或IS锁;
- 仅当事务对当前节点的父节点持有IX或SIX锁时,才可以当前节点加X、SIX或IX锁;
- 仅当事务未曾对任何节点释放锁时,才可对节点加锁(也是两阶段);
- 仅当事务不持有当前节点的子节点的锁时,才可释放当前节点的锁。
多粒度加锁协议要求加锁按照从上到下的顺序,释放锁按照从下到上的顺序。
为什么IX和S是不相容的 事务T1持有节点的S锁意味着其所有后代节点都持有了S锁,如果T2同时也持有了该节点的IX锁并在更后代节点中加了X锁,那么就违反了S锁和X锁不相容的规则。同理,IX和SIX也是不相容的,因为SIX也显示的给它的后代节点加了S锁。
为什么需要SIX锁 事务T1做全表扫描,并对一部分数据做更新。事务T2扫描表中的一部分数据,并且与T1更新的数据没有交集。因为事务T1要做全表扫描,那么它应该对root节点加S锁以防止其他事务去更新,而由于它还要对部分低层次节点锁修改,所以接下来还需要加排他锁,以防止其他事务读到他未提交的修改。这正是SIX锁的意义,T1和T2可以并发。这也就是SIX和IS是相容的原因。 SIX其实是一个锁升级的过程: S -> S+IX
时间戳排序并发控制
介绍
时间戳排序(Timestamp Ordering Concurrency Control, T/O)是一种乐观的并发控制协议类别,其假设事务冲突很少发生。不要求事务在读写数据库对象之前获取锁,而是使用时间戳来确定事务的可串行化顺序。
每个事务Ti被分配一个唯一的固定时间戳TS(Ti),该时间戳是单调递增的。 不同的方案在事务的不同阶段分配时间戳。一些高级方案甚至为每个事务分配多个时间戳。
如果TS(Ti) < TS(Tj),那么DBMS必须确保 执行schedule 等同于Ti在Tj之前的串行schedule。
有多种时间戳分配实现策略。DBMS可以使用系统时钟作为时间戳,但像夏令时这样的边缘情况会引发问题。 另一个选择是使用逻辑计数器。然而,这在溢出问题以及在具有多台机器的分布式系统中维护计数器方面存在问题。 还有一些策略结合了这两种方法。
基本时间戳排序
基本时间戳排序协议(Basic Timestamp Ordering, BASIC T/O)允许在不使用锁的情况下对数据库对象进行读取和写入。 每个数据库对象X都被标记为最后成功执行读取(表示为R-TS(X))或写入(表示为W-TS(X))的事务的时间戳。 然后DBMS检查每个操作的时间戳。如果事务试图以违反时间戳排序的方式访问对象,事务将被ABORT并重新启动。 潜在的假设是违反将很少发生,因此这些重新启动也将很少发生。
读取操作
对于读取操作,如果TS(Ti) < W-TS(X),这违反了Ti与X的前一个写入者的时间顺序(不希望读取“未来”写入的内容)。 因此,Ti被ABORT并重新启动,并赋予一个新的时间戳。 否则,读取是有效的,Ti被允许读取X。 然后DBMS将R-TS(X)更新为R-TS(X)和TS(Ti)的最大值。 它还必须在私有工作区中为X制作一个本地副本,以确保Ti的可重复读。
写入操作
对于写入操作,如果TS(Ti) < R-TS(X)或TS(Ti) < W-TS(X),Ti必须被重新启动(不希望覆盖“未来”的更改)。 否则,DBMS允许Ti写入X并更新W-TS(X)。 同样,它需要为X制作一个本地副本,以确保Ti的可重复读。
托马斯写规则
对于写操作的一个优化是,如果TS(Ti) < W-TS(X),DBMS可以忽略这次写操作并允许事务继续进行,而不是ABORT并重新启动它。这被称为托马斯写规则。 请注意,这违反了Ti的时间戳顺序,但这是可以接受的,因为没有其他事务会读取Ti对对象X的写操作。 如果事务Ti后续对对象X有读取操作,它可以读取它自己的本地副本。
如果不使用托马斯写规则,基本时间戳排序(T/O)协议生成的调度是冲突可串行化的。它不可能出现死锁,因为没有事务会等待。 然而,长时间运行的事务更有可能饥饿,因为它们更有可能读取来自更新事务的对象。 它还允许不可恢复调度: 如果事务在它们读取的所有更改的事务提交后才提交,则调度是可恢复的。否则,DBMS无法保证事务读取的数据在从崩溃中恢复后会被恢复。
潜在问题:
- 每次读取对象都需要写入时间戳。
- 将数据复制到事务的工作区以及更新时间戳的开销高。
- 长时间运行的事务可能会饥饿。
- 在高并发系统中,受到时间戳分配瓶颈的影响。
- 允许不可恢复调度。
乐观并发控制(OCC)
乐观并发控制(Optimistic Concurrency Control, OCC)是另一种乐观的并发控制协议,它也使用时间戳来验证事务。 当冲突数量较低时,OCC工作效果最佳。这种情况发生在所有事务都是只读的,或者事务访问的数据子集不重叠。如果数据库很大且工作负载不偏斜,那么冲突的概率很低,这使得OCC成为一个不错的选择。
在OCC中,DBMS为每个事务创建一个私有工作区。事务的所有修改都应用于这个工作区。任何读取的对象都被复制到工作区,任何写入的对象都被复制到工作区并在那里修改。其他事务无法读取另一个事务在其私有工作区中所做的更改。
当事务提交时,DBMS比较事务的工作区写集,以查看是否与其他事务冲突。如果没有冲突,写集就会被安装到“全局”数据库中。
OCC包括三个阶段:
- 读取阶段:DBMS跟踪事务的读写集,并将它们的写入存储在私有工作区。
- 验证阶段:当事务提交时,DBMS检查它是否与其他事务冲突。
- 写入阶段:如果验证成功,DBMS将私有工作区的更改应用到数据库。否则,它会ABORT并重新启动事务。
验证阶段
DBMS在事务进入验证阶段时为它们分配时间戳。为了确保只允许可串行化的schedule,DBMS检查Ti与其他事务的读-写冲突(“不可重复读”)和写-写冲突(“丢失更新”),并确保所有冲突都是单向的。
- 方法1:向后验证(从较新的事务到较旧的事务)
- 方法2:向前验证(从较旧的事务到较新的事务)
以向前验证为例:DBMS检查提交事务与其他所有运行中的事务的时间戳顺序。尚未进入验证阶段的事务被分配一个时间戳 ∞ 。
如果TS(Ti) < TS(Tj),那么以下三个条件之一必须成立:
- Ti在Tj开始执行之前完成所有三个阶段(串行排序)。
- Ti在Tj开始写入阶段之前完成,并且Ti没有写入Tj读取的任何对象。 WriteSet(Ti) ∩ ReadSet(Tj) = ∅。
- Ti在Tj完成读取阶段之前完成其读取阶段,并且Ti没有写入Tj读取或写入的任何对象。 WriteSet(Ti) ∩ ReadSet(Tj) = ∅,且 WriteSet(Ti) ∩ WriteSet(Tj) = ∅。
潜在问题
- 将数据复制到事务的私有工作区的开销高。
- 验证/写入阶段瓶颈。
- ABORT可能比其他协议更浪费,因为它们只在事务已经执行后才发生。
- 受到时间戳分配瓶颈的影响。
多版本并发控制
隔离级别
串行化允许程序员忽略并发问题,但强制执行它可能限制了并行性。DBMS提供较弱的一致性级别。
异常:
- 脏读:读取未提交的数据。
- 不可重复读:重新读取检索到不同的结果。
- 幻影读:插入或删除导致相同范围扫描查询的结果不同。
隔离级别(从最强到最弱):
- 串行化:没有幻影,所有读取可重复,没有脏读。 可能的实现:索引锁定 + 严格2PL。
- 可重复读:可能发生幻影。 可能的实现:严格2PL。
- 读已提交:可能发生幻影和不可重复读。 可能的实现:独占锁的严格2PL,读取后立即释放共享锁。
- 读未提交:所有异常都可能发生。 可能的实现:独占锁的严格2PL,读取没有共享锁。
SQL-92标准定义的隔离级别只关注在基于2PL的DBMS中可能发生的异常。还有两个额外的隔离级别:
- 游标稳定性 在可重复读和读已提交之间。 防止丢失更新异常。 IBM DB2的默认隔离级别。
- 快照隔离 保证事务中所有读取看到的数据库一致快照,该快照存在于事务开始时。 只有在事务的写入与自该快照以来的任何并发更新没有冲突时,事务才会提交。 易受写偏异常影响。
幻影问题
事务只对现有记录加锁,忽略了正在创建中的记录,会出现幻影问题。这可能导致执行非串行化。
解决方法:
重新执行扫描
事务可能在提交时重新运行查询,以检查不同的结果,防止由于新记录或已删除记录而错过了更改。 DBMS跟踪事务执行的所有查询的WHERE子句。在提交时,它重新执行扫描以确保结果保持一致。
谓词锁
根据查询的谓词获取锁,确保其他事务不能修改满足谓词的数据。 最初在System R中提出,这种方案没有被广泛实现。然而,像HyPer这样的系统利用了一种类似于谓词锁的精确锁。
索引锁
利用索引键来保护数据范围,通过确保没有新数据可以落入加锁范围内来防止幻影。 方案:
- 键值锁:在索引中对单个键值加锁,包括不存在值的虚拟键。
- 间隙锁:对键值后的间隙加锁,防止在这些间隙中插入。
- 键范围锁:锁定从现有键到下一个键的范围。
- 层次锁:允许事务持有具有不同模式的更广泛的键范围锁,减少锁管理器开销。
如果没有合适的索引,事务必须锁定表中的每个页面或整个表本身,以防止可能导致幻影的更改。
多版本并发控制
多版本并发控制(MVCC)是一个比并发控制协议更广泛的概念。它涉及DBMS设计和实现的所有方面。MVCC 是目前数据库系统中使用最广泛的方案。在过去10年中,几乎所有新实现的DBMS都使用了它。甚至一些不支持多语句事务的系统(例如,NoSQL)也使用了它。
在MVCC中,DBMS 在数据库中为单个逻辑对象维护多个物理版本。当事务写入对象时,DBMS 会创建该对象的新版本。当事务读取对象时,它会读取在事务开始时存在的最新版本。
MVCC 的根本概念/好处是写者不会阻塞读者,读者也不会阻塞写者。这意味着一个事务可以在其他事务读取旧版本的同时修改对象。如果它们正在写入相同的对象,写者仍然可能会阻塞其他写者,因为数据库对象相关的版本上仍然有锁。
使用MVCC的一个优点是,只读事务可以在不使用任何锁的情况下读取数据库的一致快照。此外,多版本数据库系统可以轻松支持Time-Travel查询,这些查询基于数据库在其他时间点的状态(例如,执行查询以查看3小时前数据库的状态)。
典型的基于MVCC的数据库设计将包括:
- 有一个版本化存储,用于存储同一逻辑对象的不同版本。
- 当事务开始时,DBMS 会获取数据库的快照(通过复制事务状态表)。
- DBMS 使用快照来确定事务可见的对象版本。
有五个重要的MVCC设计决策:
- 并发控制协议
- 版本存储
- 垃圾回收
- 索引管理
- 删除
并发协议的选择是在前面讲座中讨论的方法之间(两阶段锁定、时间戳排序、乐观并发控制)。
快照隔离 快照隔离涉及在事务开始时提供一个数据库的一致快照。快照中的数据值只包含已提交事务的值,并且事务在完成前完全独立于其他事务。这对于只读事务非常理想,因为它们不需要等待其他事务的写操作。写操作在事务的私有工作区中维护,或者带有事务元数据写入存储,并且只有在事务成功提交后才对数据库可见。
写冲突 如果两个事务更新同一个对象,第一个写者获胜。
写偏异常 在快照隔离中,当两个并发事务修改不同的对象导致非串行化调度时,可能会发生写偏异常。例如,如果一个事务将所有白色弹珠变成黑色,另一个将所有黑色弹珠变成白色,结果可能不对应任何串行化调度。
版本存储
这是DBMS如何存储逻辑对象的不同物理版本以及事务如何找到对它们可见的最新版本。 DBMS 使用元组的指针字段为每个逻辑元组创建一个版本链,这实际上是按时间戳排序的版本链的链接列表。这允许DBMS在运行时找到对特定事务可见的版本。索引始终指向链的“头部”,这取决于实现,要么是最新版本,要么是最旧版本。线程遍历链直到找到正确的版本。不同的存储方案决定了每个版本存储的位置/内容。
仅追加存储
所有物理版本的逻辑元组都存储在同一个表空间中。版本混合在表中,每个更新只是在表中追加元组的新版本并更新版本链。链可以是按最旧到最新排序(O2N),这需要在查找时遍历链,或者是最新到最旧(N2O),这需要为每个新版本更新索引指针。
Time-Travel存储
DBMS 维护一个名为Time-Travel表的单独表,用于存储元组的旧版本。每次更新时,DBMS 将元组的旧版本复制到Time-Travel表中,并用新数据覆盖主表中的元组。主表中的元组指针指向Time-Travel表中的过去版本。
增量存储
与Time-Travel存储类似,但DBMS 不是存储整个过去的元组,而是只存储元组之间的增量,或者称为增量存储段中的变化。事务可以通过反向迭代增量并应用它们来重建旧版本。这导致写操作比Time-Travel存储更快,但读取速度更慢。
垃圾回收
DBMS 需要随着时间的推移从数据库中移除可回收的物理版本。如果没有任何活跃事务可以“看到”某个版本,或者它是由已中止的事务创建的,那么这个版本就是可回收的。
元组级 GC
通过元组级垃圾回收,DBMS 通过直接检查元组来找到旧版本。实现这一目标有两种方法:
- 后台Vacuuming:独立的线程定期扫描表,寻找可回收的版本。这适用于任何版本存储方案。一个简单的优化是维护一个“脏页位图”,它跟踪自上次扫描以来哪些页面已被修改。这允许线程跳过未更改的页面。
- 协作清理:Worker线程在遍历版本链时识别可回收的版本。这只适用于 O2N 链。如果数据不被访问,它将永远不会被清理。
事务级 GC
在事务级垃圾回收中,每个事务负责跟踪自己的旧版本,这样 DBMS 就不必扫描元组。每个事务维护自己的读写集合。当事务完成时,垃圾回收器可以使用这些信息来确定哪些元组可以回收。DBMS 确定由已完成事务创建的所有版本何时不再可见。
索引管理
所有主键(pkey)索引始终指向版本链的头部。DBMS 需要多频繁地更新 pkey 索引取决于系统在元组更新时是否创建新版本。如果事务更新了 pkey 属性,则这被视为 DELETE 后跟 INSERT。
管理二级索引更为复杂。处理它们有两种方法。
逻辑指针
DBMS 为每个元组使用一个不变的固定标识符。这需要一个额外的间接层,将逻辑 ID 映射到元组的物理位置。然后,元组的更新只需在间接层中更新映射。
物理指针
DBMS 使用指向版本链头部的物理地址。这需要在版本链头部更新时更新每个索引,这可能非常昂贵。
MVCC DBMS 索引(通常)不在其键旁边存储有关元组的版本信息。相反,每个索引必须支持来自不同快照的重复键,因为相同的键可能指向不同快照中的不同逻辑元组。
MVCC 重复键问题
描述了在多个事务需要同一逻辑元组的多个版本时,MVCC DBMS 索引需要支持重复键的需求。例如,假设 TXN 1 指向逻辑元组的版本 0,而 TXN 2 创建了该相同逻辑元组的版本 1。我们的索引需要为两个事务指向这两个版本,以便每个事务在任何时候都能访问到适当的物理版本。
Workers可能会为单个获取操作返回多个条目,然后他们必须跟随指针找到他们适当的物理版本。
日志
崩溃恢复
恢复算法是确保数据库一致性、事务原子性和持久性的技术,尽管存在故障。当崩溃发生时,所有未提交到磁盘的内存中的数据都有丢失的风险。恢复算法的作用是在崩溃后防止信息丢失。
每个恢复算法都有两个部分:
- 正常事务处理期间的行动,以确保DBMS能够从故障中恢复。
- 故障后的行动,以恢复数据库到确保原子性、一致性和持久性的状态。
恢复算法中使用的关键原语是 UNDO 和 REDO。并非所有算法都使用这两种原语。
- UNDO:移除未完成或中止事务的效果的过程。
- REDO:重新应用已提交事务的效果以确保持久性的过程。
存储类型
- 易失性存储
- 数据在断电或程序退出后不会持久化。
- 示例:DRAM, SRAM。
- 非易失性存储
- 数据在失去电源或程序退出后仍然持久化。
- 示例:HDD, SSD。
- 稳定存储
- 一种不存在的非易失性存储形式,能够在所有可能的故障情况下存活。- 使用多个存储设备来近似。
动机
DBMS 使用易失性存储来存储Buffer Pool页面的内容,因为与非易失性存储相比,易失性存储的读写速度显著更快。然而,DBMS 希望存储持久状态,因此我们出于性能原因允许在我们的 Buffer Pool Manager 中有脏页面,并在必要时刷新到非易失性存储。然而,这提出了一个问题:DBMS 如何处理易失性存储故障?
故障分类
由于 DBMS 基于底层存储设备的不同组件进行划分,因此 DBMS 需要处理多种不同类型的故障。其中一些故障是可以恢复的,而另一些则不是。
事务失败
事务失败发生在事务遇到错误并必须中止时。导致事务失败的两种错误类型是逻辑错误和内部状态错误。
- 逻辑错误:事务由于某些内部错误条件(例如,完整性,约束违反)无法完成。
- 内部状态错误:由于错误条件(例如,死锁),DBMS 必须终止一个活动事务。
系统故障
系统故障是 DBMS 所依赖的底层软件或硬件中发生的意外故障。这些故障必须在崩溃恢复协议中考虑。
- 软件故障:DBMS 实现存在问题(例如,未捕获的除以零异常),系统必须停止。
- 硬件故障:托管 DBMS 的计算机崩溃(例如,电源插头被拔出)。我们假设非易失性存储内容不会被系统崩溃破坏。这被称为“Failstop”假设,简化了恢复过程。
存储媒介故障
存储媒介故障是当物理存储设备损坏时发生的不可修复的故障。当存储媒介失败时,DBMS 必须从一个存档版本中恢复。DBMS 无法从存储故障中恢复,需要人为干预。
- 非可修复硬件故障:磁头碰撞或类似的磁盘故障破坏了非易失性存储的全部或部分。假设破坏是可以检测到的。
Buffer Pool管理策略
DBMS 需要确保以下保证:
- 一旦 DBMS 告诉某人事务已提交,任何事务的更改都是持久的。
- 如果事务中止,则没有部分更改是持久的。
STEAL策略规定 DBMS 是否允许未提交的事务覆盖非易失性存储中对象的最新提交值(事务是否可以将属于不同事务的未提交更改写入磁盘?)。
- STEAL: 允许
- NO-STEAL: 不允许
强制策略规定 DBMS 是否要求事务所做的所有更新在事务被允许提交之前(即向客户端返回提交消息)反映在非易失性存储上。
- FORCE: 必需
- NO-FORCE: 不必需
强制写入使得恢复更容易,因为所有更改都被保存,但会导致运行时性能下降。
最容易实现的Buffer Pool管理策略称为 NO-STEAL + FORCE。在这种策略中,DBMS 永远不需要Undo已中止事务的更改,因为更改没有写入磁盘。同时,也永远不需要Redo已提交事务的更改,因为所有更改都保证在提交时写入磁盘。图1展示了 NO-STEAL + FORCE 的一个例子。
图1: 使用 NO-STEAL + FORCE 的 DBMS 示例 - 事务的所有更改只在事务提交时写入磁盘。一旦在步骤 #1 开始调度,T1 和 T2 的更改被写入Buffer Pool。由于 FORCE 策略,当 T2 在步骤 #2 提交时,其所有更改必须写入磁盘。为此,DBMS 复制内存到磁盘,仅应用 T2 的更改,并将其写回磁盘。这是因为 NO-STEAL 防止了 T1 的未提交更改被写入磁盘。在步骤 #3,对于 DBMS 来说,回滚 T1 是微不足道的,因为磁盘上没有 T1 的脏更改。
NO-STEAL + FORCE 的限制在于,内存必须能够容纳事务需要修改的所有数据(即写集)。否则,该事务无法执行,因为 DBMS 不允许在事务提交前将脏页面写入磁盘。
影子分页
影子分页是对前面方案的改进,其中 DBMS 在写时复制页面,以维护数据库的两个独立版本:
- 主数据库:仅包含已提交事务的更改。
- 影子数据库:包含未提交事务所做的更改的临时数据库。
更新仅在影子副本中进行。当事务提交时,影子副本原子地切换成为新的主数据库。旧的主数据库最终会被垃圾回收。这是一个 NO-STEAL + FORCE 系统的例子。图2展示了影子分页的高级示例。
图2: 影子分页 - 数据库根指向主页面表,该表又指向磁盘上的页面(所有页面都包含已提交的数据)。当发生更新事务时,会创建一个影子页面表,指向与主数据库相同的页面。修改在磁盘上的临时空间进行,影子表被更新。为了完成提交,数据库根指针被重定向到影子表,它成为新的主数据库。
实现
DBMS 以树结构组织数据库页面,根是单个磁盘页面。主数据库和影子数据库有两个副本。根始终指向当前的主数据库副本。当事务执行时,它只对影子副本进行更改。
当事务想要提交时,DBMS 必须安装其更新。为此,它只需覆盖根,使其指向数据库的影子副本,从而交换主数据库和影子数据库。在覆盖根之前,事务的更新不是磁盘上数据库的一部分。覆盖根后,事务的所有更新都成为磁盘上数据库的一部分。这种覆盖根的操作可以原子地完成。
恢复
- Undo:移除影子页面。保留主数据库和数据库根指针不变。
- Redo:根本不需要。
缺点
影子分页的一个缺点是复制整个页面表成本高昂。实际上,只需要复制导致更新叶节点的树路径,而不是整个树。 此外,影子分页的提交开销很高。提交需要页面表、根页面和每个更新页面都被刷新。这种方法导致大量随机非连续页面的写入。此外,这种方法导致数据碎片化,因为潜在相关的数据被分割在不同的页面上。它还需要垃圾回收,因为随着数据的更新,对不同页面的引用将被取消,这些引用需要更新,以便没有页面引用旧的、未更新的数据。另一个问题是,这种方法只支持一次一个写入事务或批量事务。
日志文件
当事务修改页面时,DBMS 在覆盖主版本之前将原始页面复制到单独的日志文件中。在重启后,如果存在日志文件,DBMS 将恢复它以Undo未提交事务的更改。 这种技术在2010年之前的 SQLite 中得到了实现。然而,在2010年之后,他们转而使用预写式日志(WAL)来跟踪更改。
预写式日志(WAL)
在预写式日志中,DBMS 在将更改应用到磁盘页面之前,将对数据库所做的所有更改记录到一个日志文件(在稳定存储上)。日志包含足够的信息来执行必要的Undo和Redo操作,以便在崩溃后恢复数据库。DBMS 必须在将对象刷新到磁盘之前,将与更改相关的日志文件记录写入磁盘。WAL 是 STEAL + NO-FORCE 系统的一个例子。
在影子分页中,DBMS 需要对磁盘上的随机非连续页面进行写入。预写式日志允许 DBMS 将随机写入转换为顺序写入,以优化性能。因此,几乎所有的 DBMS 都使用预写式日志(WAL),因为它具有最快的运行时性能。但是,使用 WAL 的 DBMS 的恢复时间比影子分页慢,因为它需要重放日志。
图3: 预写式日志 - 当事务开始时,所有更改都记录在内存中的 WAL 缓冲区中,然后在对Buffer Pool进行更改。在提交时,WAL 缓冲区被刷新到磁盘。一旦 WAL 缓冲区安全地在磁盘上,事务结果就可以写入磁盘。
实现
DBMS 首先将事务的所有日志记录暂存到易失性存储中。然后,在允许页面本身在非易失性存储中被覆盖之前,将所有与更新页面相关的日志记录写入非易失性存储。在事务被认为是提交之前,必须将所有日志记录刷新到磁盘。
当事务开始时,为每个事务写入一个 <BEGIN> 记录到日志中,以标记其起始点。
当事务完成时,写入一个 <COMMIT> 记录到日志,并确保在向应用程序返回确认之前所有日志记录都已刷新。
每个日志条目包含必要的信息,以便回滚或重放对单个对象的更改:
- 事务 ID。
- 对象 ID。
- 原始值(用于 UNDO)。
- 新值(用于 REDO)。
DBMS 必须在告诉外界事务已成功提交之前,将所有事务的日志条目刷新到磁盘。 系统可以使用“组提交”优化,将多个日志刷新批处理在一起,以分摊开销。刷新操作发生在日志缓冲区满时,或者在连续刷新之间经过足够时间后。DBMS 可以随时将脏页面写入磁盘,只要它是在刷新相应的日志记录之后。
Log-Structured系统 在Log-Structured的 DBMS 中,事务的日志记录被写入一个名为 MemTable 的内存缓冲区。当这个缓冲区满了,它会被刷新到磁盘。这种方法仍然需要一个独立的预写式日志。这是因为 WAL 的刷新通常比 MemTable 的刷新更频繁,而且 WAL 可能包含未提交的事务。在从崩溃中恢复时,WAL 被用来重新创建内存中的 MemTable。
日志方案
日志记录的内容可以根据实现而有所不同。
Physical Logging
- 记录对数据库特定位置进行的字节级更改。
- 示例:git diff
Logical logging
- 记录事务执行的高级操作。
- 不一定限制在单个页面上。
- 由于每个记录可以更新多个页面上的多个元组,因此每个日志记录需要写入的数据比Physical Logging少。然而,在非确定性并发控制方案中,当有并发事务时,实现Logical logging的恢复比较困难。此外,恢复时间更长,因为必须重新执行每个事务。
- 示例:事务调用的 UPDATE、DELETE 和 INSERT 查询。
Physiological Logging
- 混合方法,其中日志记录针对单个页面,但不指定页面的数据组织。也就是说,根据页面中的插槽号识别元组,而不指定更改在页面中的确切位置。因此,DBMS 可以在日志记录写入磁盘后重新组织页面。
- 在 DBMS 中使用最普遍的方法。
检查点
基于 WAL 的 DBMS 的主要问题是日志文件会不断增长。崩溃后,DBMS 必须重放整个日志,如果日志文件很大,这可能需要很长时间。因此,DBMS 可以定期进行检查点,将所有缓冲区刷新到磁盘。
DBMS 应该多久进行一次检查点取决于应用程序的性能和停机时间要求。检查点太频繁会导致 DBMS 的运行时性能下降。但是,等待很长时间再进行检查点可能同样糟糕,因为系统重启后的恢复时间会增加。
阻塞检查点实现
- DBMS 停止接受新事务,等待所有活动事务完成。
- 将当前存储在主内存中的所有日志记录和脏块刷新到稳定存储。
- 写入一个
<CHECKPOINT>记录到日志并刷新到稳定存储。
崩溃恢复
崩溃恢复
DBMS依赖其恢复算法来确保数据库的一致性、事务的原子性和持久性,即使在发生故障的情况下也是如此。每个恢复算法由两部分组成:
- 在正常事务处理期间采取的行动,以确保DBMS能够从故障中恢复
- 在故障后采取的行动,以恢复数据库到一个状态,确保事务的原子性、一致性和持久性。
数据库弹性的关键是管理事务的完整性和持久性,特别是在故障场景中。这个基础概念为引入ARIES恢复算法奠定了基础。基于语义的恢复与隔离算法(Algorithms for Recovery and Isolation Exploiting Semantics, ARIES)是在1990年代初为DB2系统开发的IBM研究的恢复算法。
ARIES恢复协议有三个关键概念:
- 预写式日志记录:在将数据库更改写入磁盘之前,任何更改都记录在稳定存储的日志中(STEAL + NO-FORCE)。
- 在Redo期间重复历史:在重启时,追溯行动并恢复数据库到崩溃前确切的状态。
- 在Undo期间记录更改:记录Undo行动到日志,以确保在重复故障的情况下不会重复行动。
WAL记录
预写式日志记录扩展了DBMS的日志记录格式,包括一个全局唯一的日志序列号(LSN)。所有日志记录都有一个LSN。图1展示了带有LSN的日志记录如何被写入的高级图示。
图 1:写入日志记录 - 每个WAL都有一个LSN计数器,该计数器在每个步骤中递增。页面还保持一个pageLSN和一个recLSN,recLSN存储使页面变脏的第一个日志记录。flushedLSN是一个指向最近写入磁盘的LSN的指针。在DBMS可以将页面i写入磁盘之前,它必须至少将日志刷新到pageLSNi ≤ flushedLSN的点。MasterRecord指向最后一次成功的检查点。
每个数据页包含一个pageLSN,这是该页最近一次更新的LSN。每当事务修改页面中的记录时,pageLSN就会更新。
DBMS还跟踪到目前为止已刷新的最大LSN(flushedLSN)。内存中的flushedLSN在DBMS将WAL缓冲区写入磁盘时更新。
系统中的各种组件跟踪与它们相关的LSN。这些LSN的表格如下所示。
| 名称 | 位置 | 定义 |
|---|---|---|
| flushedLSN | 内存 | 最后一个写入磁盘的日志的LSN |
| pageLSN | 页面 | 最近一次更新页面的LSN |
| recLSN | 页面 | 自上次刷新以来页面的最旧更新的LSN |
| lastLSN | 活动事务表 | 事务Ti的最新记录(由事务管理) |
| MasterRecord | 磁盘 | 最后一个成功检查点的LSN |
正常执行
每个事务都会调用一系列的读取和写入操作,然后是提交或中止。正是这一系列事件,恢复算法必须拥有。
事务提交
当一个事务准备提交时,DBMS首先将提交(COMMIT)记录写入内存中的日志缓冲区。然后,DBMS将所有日志记录(包括事务的提交记录)刷新到磁盘。请注意,这些日志刷新是顺序的、同步写入磁盘的操作。每个日志页面可以有多个日志记录。事务提交的示意图见图2。
图 2:事务提交 - 在事务提交(015)之后,日志被刷新,并且flushedLSN被修改为指向生成的最后一个日志记录。在某个后续时间点,会写入一个事务结束消息,以在日志中表示这个事务不会再出现。然后我们可以将内存中的日志裁剪到flushedLSN。
一旦COMMIT记录安全地存储在磁盘上,DBMS就会向应用程序返回一个确认,表明事务已提交。在某个后续时间点,DBMS将写入一个特殊的TXN-END记录到日志。这表示事务在系统中已经完全完成,不会再有该事务的日志记录。这些TXN-END记录用于内部账务处理,不需要立即刷新到磁盘。
事务中止
中止一个事务是ARIES Undo操作的一个特殊情况,只应用于一个事务。 在日志记录中添加了一个名为prevLSN的额外字段。这对应于事务的前一个LSN。DBMS使用这些prevLSN值来维护每个事务的链表,这使得遍历日志以查找其记录变得更加容易。
还引入了一种新类型的记录,称为补偿日志记录(CLR)。CLR描述了Undo前一个更新记录的操作。它具有更新日志记录的所有字段,加上undoNext指针(即下一个要Undo的LSN)。DBMS像添加其他记录一样将CLR添加到日志中,但它们永远不需要被Undo。此外,DBMS在通知应用程序事务已被中止之前,不会等待CLR刷新到磁盘。这种方法确保了高效的事务管理,特别是在涉及事务回滚的场景中。
要中止一个事务,DBMS首先将一个ABORT记录追加到内存中的日志缓冲区。然后,它按相反的顺序Undo事务的更新,以从数据库中移除它们的效果。对于每个Undo的更新,DBMS在日志中创建CLR条目并恢复旧值。在所有被中止事务的更新都被Undo之后,DBMS然后写入一个TXN-END日志记录。这的示意图见图3。
图 3:事务中止 - DBMS 为事务创建的每个日志记录维护一个LSN和prevLSN。当事务中止时,所有之前的更改都会被Undo。在Undo更改的日志条目被写入磁盘后,DBMS 会为已中止的事务在日志中追加一个TXN-END记录。
检查点
DBMS定期进行检查点操作,将其缓冲池中的脏页写入磁盘。这用于最小化恢复时需要重放的日志量。
下面讨论的前两种阻塞检查点方法在检查点过程中暂停事务和查询的执行。这种暂停是必要的,以确保DBMS在检查点期间不会错过对页面的更新。然后,提出了一种更好的方法,它允许事务在检查点期间继续执行,但要求DBMS记录额外的信息以确定它可能错过的更新。
非模糊检查点
DBMS在进行检查点时停止事务和查询的执行,以确保它将数据库的一致快照写入磁盘。这与之前讲座中讨论的方法相同: • 停止任何新事务的开始。 • 等待所有活动事务完成执行。 • 将脏页刷新到磁盘。
虽然这个过程会影响运行时性能,但它显著简化了恢复过程。在非模糊检查点期间,DBMS确保在检查点时数据库处于一致状态。这意味着在恢复时,DBMS只需要重放自上次检查点以来的日志记录,而不是整个事务日志。这减少了恢复所需的时间和资源,因为DBMS不需要处理自检查点以来所有事务的日志记录。然而,暂停所有事务和查询会导致系统在检查点期间暂时不可用,这可能会影响用户体验和系统的整体性能。
稍微改进的阻塞检查点
与之前的检查点方案类似,但DBMS不需要等待活动事务完成执行。DBMS现在记录检查点开始时的内部系统状态。
• 停止任何新事务的开始。 • 在DBMS进行检查点时暂停事务。
检查点过程需要记录其开始时的内部状态。这包括两个关键组件:活动事务表(ATT),它跟踪正在进行的事务,以及脏页表(DPT),它列出了所有尚未写入磁盘的修改过的页面。
活动事务表(ATT) ATT代表了在DBMS中积极运行的事务的状态。事务的条目在DBMS完成该事务的提交/中止过程后被移除。对于每个事务条目,ATT包含以下信息: • transactionId:唯一的事务标识符 • status:事务的当前“模式”(运行中,提交中,Undo候选)。 • lastLSN:事务写入的最新LSN
请注意,ATT包含了每个事务,但不包括TXN-END日志记录。这包括已经提交或中止的事务。
脏页表(DPT) DPT包含了关于缓冲池中被未提交事务修改的页面的信息。每个脏页都有一个条目,包含recLSN(即,首先使页面变脏的日志记录的LSN)。 DPT包含了缓冲池中所有脏页。不管这些更改是由正在运行的事务、已提交的事务还是已中止的事务引起的,DPT都会记录。
总的来说,ATT和DPT在检查点和恢复过程中都至关重要。在进行检查点时,它们捕捉数据库的当前状态,ATT跟踪活动事务,而DPT列出未刷新的修改过的页面。在恢复过程中,例如使用ARIES协议,这些表有助于将数据库恢复到崩溃前一致的状态。通过这些表,DBMS可以确定哪些事务已经完成,哪些页面需要刷新到磁盘,以及在崩溃后需要Undo哪些操作,以确保数据库的一致性和完整性。
模糊检查点
模糊检查点是DBMS允许其他事务继续运行的一种检查点方式。这是ARIES协议中使用的方法。
DBMS使用额外的日志记录来跟踪检查点的边界:
•
检查点完成后,
ARIES恢复
ARIES协议由三个阶段组成。在崩溃后启动时,DBMS将执行以下阶段,如图4所示:
图 4:ARIES恢复:DBMS通过检查MasterRecord中找到的最后一个BEGIN-CHECKPOINT开始恢复过程。然后,它开始分析阶段,通过向前扫描时间来构建ATT和DPT。在Redo阶段,算法跳转到最小的recLSN,这是可能修改了未写入磁盘的页面的最老的日志记录。然后DBMS应用从最小的recLSN开始的所有更改。Undo阶段从崩溃时活跃的事务的最老日志记录开始,撤销到那一点的所有更改。
- 分析:读取WAL以识别缓冲池中的脏页和崩溃时的活动事务。在分析阶段结束时,ATT告诉DBMS哪些事务在崩溃时是活动的。DPT告诉DBMS哪些脏页可能没有写入磁盘。
- Redo:从日志中的适当点开始重复所有操作(即使是将要中止的事务)。
- Undo:Undo在崩溃前未提交的事务的操作。
分析阶段
从数据库的MasterRecord LSN找到的最后一个检查点开始。
- 从检查点向前扫描日志。
- 如果DBMS找到一个TXN-END记录,将其事务从ATT中移除。
- 对于所有其他记录,将事务添加到ATT中,状态设置为UNDO,并且在提交时,将事务状态更改为COMMIT。
- 对于UPDATE日志记录,如果页面P不在DPT中,那么将P添加到DPT中,并将P的recLSN设置为日志记录的LSN。
Redo阶段
这个阶段的目标是让DBMS重复历史,以重建其状态,直到崩溃的那一刻。它将重新应用所有更新(即使是已中止的事务)并RedoCLR。
DBMS从DPT中包含最小recLSN的日志记录开始向前扫描。对于每个具有给定LSN的更新日志记录或CLR,DBMS将重新应用更新,除非:
在Redo阶段,DBMS会重新应用日志记录中的更改,然后设置受影响页面的pageLSN为该日志记录的LSN。如果满足以下条件,则不会重新应用更新:
- 受影响的页面不在DPT中,或者
- 受影响的页面在DPT中,但该记录的LSN小于DPT中页面的recLSN,或者
- 受影响的页面LSN(在磁盘上)≥ LSN。
要Redo操作,DBMS重新应用日志记录中的更改,然后将受影响页面的pageLSN设置为该日志记录的LSN。在Redo阶段结束时,为所有状态为COMMIT的事务写入TXN-END日志记录,并将它们从ATT中移除。
Undo阶段
在最后一个阶段,DBMS撤销在崩溃时活跃的所有事务。这些是在分析阶段后ATT中具有UNDO状态的所有事务。
DBMS使用lastLSN以逆LSN顺序处理事务,以加快遍历速度。在每一步中,选择ATT中所有事务的最大lastLSN。在撤销事务的更新时,DBMS为每个修改写入CLR条目到日志。
一旦最后一个事务成功中止,DBMS将日志刷新,然后准备开始处理新事务。这个过程确保了数据库在崩溃后能够恢复到一致的状态,并且所有已提交的事务都得到了正确的处理,而未完成的事务则被Undo。
分布式数据库
简介
分布式DBMS将单一的逻辑数据库分散到多个物理资源上。应用程序(通常)不知道数据被分散在不同的硬件上。系统依赖于单节点DBMS的技术和算法来支持分布式环境中的事务处理和查询执行。设计分布式DBMS的一个重要目标是容错性(即避免单一节点故障导致整个系统瘫痪)。
系统架构
DBMS的系统架构指定了哪些共享资源可以直接被CPU访问。它影响CPU如何相互协调以及它们在哪里检索和存储数据库中的对象。
图 1: 数据库系统架构 - 四种系统架构方法,从共享一切(非分布式系统使用)到共享内存、磁盘或什么都不共享。
单节点DBMS使用的是所谓的共享一切架构。这个单一节点在本地CPU(s)上执行工作,拥有自己的本地内存地址空间和磁盘。
共享内存
在分布式系统中,共享一切架构的替代方案是共享内存。CPU通过快速的互连访问共同的内存地址空间。CPU还共享同一个磁盘。
实际上,大多数DBMS不使用这种架构,因为它是在操作系统/内核级别提供的。它也会引起问题,因为每个进程的内存范围是相同的内存地址空间,可以被多个进程修改。
每个处理器对所有内存中的数据结构有一个全局视图。每个处理器上的DBMS实例必须“知道”其他实例。
共享磁盘
在共享磁盘架构中,所有CPU都可以通过互连直接读取和写入单一的逻辑磁盘,但每个CPU都有自己的私有内存。每个计算节点上的本地存储可以作为缓存。这种方法在基于云的DBMS中更为常见。
数据库管理系统的执行层可以独立于存储层进行扩展。添加新的存储节点或执行节点不会影响另一层数据的布局或位置。
节点必须相互发送消息以了解其他节点的当前状态。也就是说,由于内存是本地的,如果数据被修改,必须将更改通知其他CPU,特别是当那部分数据在其他CPU的主内存中时。
节点有自己的缓冲池,并且被认为是无状态的。节点崩溃不会影响数据库的状态,因为状态是单独存储在共享磁盘上的。在崩溃的情况下,存储层会持久化状态。
无共享
在无共享环境中,每个节点都有自己的CPU、内存和磁盘。节点仅通过网络相互通信。在云存储平台兴起之前,无共享架构曾被认为是构建分布式DBMS的正确方式。
在这种架构中增加容量更加困难,因为DBMS必须物理地将数据移动到新节点。同时,确保DBMS中所有节点的一致性也很困难,因为节点必须就事务的状态相互协调。然而,优势在于无共享DBMS可能实现更好的性能,并且比其他类型的分布式DBMS架构更高效。
设计问题
分布式DBMS旨在维护数据透明性,意味着用户不应该需要知道数据物理上位于何处,或者表是如何分区或复制的。存储数据的细节对应用程序来说是隐藏的。换句话说,一个在单节点DBMS上工作的SQL查询应该在分布式DBMS上以相同的方式工作。
分布式数据库系统必须解决的关键设计问题包括:
- 应用程序如何找到数据?
- 分布式数据上的查询应该如何执行?是将查询推送到数据所在的位置?还是应该将数据汇集到一个共同的位置来执行查询?
- DBMS如何确保正确性?
另一个设计决策涉及决定节点如何在其集群中相互作用。两种选择是同质节点和异质节点,这两种都在现代系统中使用。
同质节点
集群中的每个节点都可以执行相同的任务集(尽管可能在不同的数据分区上),这非常适合无共享架构。这使得资源配置和故障转移“更容易”。失败的任务被分配给可用的节点。
异质节点
节点被分配特定的任务,因此必须在节点之间进行通信以执行给定的任务。这允许单个物理节点托管多个“虚拟”节点类型,这些节点可以独立地从一个节点扩展到其他节点。一个例子是MongoDB,它有路由节点将查询路由到分片,配置服务器节点存储键到分片的映射。
分区方案
分布式系统必须将数据库分区到多个资源上,包括磁盘、节点、处理器。这个过程有时在NoSQL系统中被称为分片。当DBMS接收到查询时,它首先分析查询计划需要访问的数据。DBMS可能会将查询计划的片段发送到不同的节点,然后将结果组合起来产生单一的答案。
分区方案的目标是最大化单节点事务,或者只访问一个分区上的数据的事务。这允许DBMS不需要协调在其他节点上运行的并发事务的行为。另一方面,分布式事务访问一个或多个分区上的数据。这需要昂贵的、困难的协调,下面将讨论。
对于逻辑分区的节点,特定的节点负责访问共享磁盘上的特定元组。对于物理分区的节点,每个无共享节点在其自己的本地磁盘上读取和更新它包含的元组。
实现
最简单的分区表的方式是朴素数据分区。每个节点存储一个表,假设给定节点有足够的存储空间。这很容易实现,因为查询只是被路由到特定的分区。这可能是不好的,因为它不可扩展。如果一个分区的资源被频繁查询,那么该分区的资源可能会耗尽,而不会使用所有可用的节点。参见图2的例子。
图 2: 简单表分区 - 给定两个表,将表一中的所有元组放入一个分区,将表二中的元组放入另一个分区。
另一种分区方式是垂直分区,它将表的属性分割成不同的分区。每个分区还必须存储元组信息以重建原始记录。
更常见的是水平分区,它将表的元组分割成不相交的子集。选择列(s)根据大小、负载或使用情况将数据库平均分割,称为分区键(s)。
DBMS可以根据哈希、数据范围或谓词来物理分区(无共享)或逻辑分区(共享磁盘)。参见图 3 的例子。哈希分区的问题在于,当添加或移除一个节点时,需要大量地重新分配数据。解决这个问题的方法是一致性哈希。
图 3: 水平表分区 - 使用哈希分区来决定将数据发送到哪里。当DBMS接收到查询时,它会使用表的分区键来找出数据的位置。
一致性哈希将每个节点分配到某个逻辑环上的一个位置。然后,每个分区键的哈希映射到环上的一个位置。在顺时针方向上最接近该键的节点负责该键。参见图 4 的例子。当添加或移除一个节点时,只有与新/移除节点相邻的节点之间的键会被移动,因此只有 1/n 分数的键被移动。
图 4: 一致性哈希 - 所有节点负责哈希环上的某一部分。这里,节点 P1 负责存储键 key1,节点 P3 负责存储键 key2。
复制因子k:每个键在顺时针方向上的 k 个最近节点处被复制。
逻辑分区 一个节点负责一组键,但它实际上并不存储这些键。这通常用于共享磁盘架构。
物理分区 一个节点负责一组键,并且它物理上存储这些键。这通常用于无共享架构。
分布式并发控制
分布式事务访问一个或多个分区上的数据,这需要昂贵的协调。
集中式协调器
集中式协调器充当全局“交通警察”,协调所有行为。参见图5。
图 5: 集中式协调器 - 客户端与协调器通信以获取客户端想要访问的分区上的锁。一旦从协调器接收到确认,客户端就将其查询发送到这些分区。一旦给定事务的所有查询完成,客户端就向协调器发送提交请求。然后协调器与参与事务的分区通信,以确定事务是否被允许提交。
中间件
集中式协调器可以用作中间件,接受查询请求并将查询路由到正确的分区。
去中心化协调器
在去中心化的方法中,节点自行组织。客户端直接将查询发送到一个分区。这个主分区将结果返回给客户端。主分区负责与其他分区通信并相应地提交。
集中式方法在多个客户端尝试获取同一分区上的锁时会导致瓶颈。然而,对于分布式2PL(两阶段锁定协议),它可以更好地处理死锁,因为它对锁有中心视图,可以更快地处理死锁。这对于去中心化方法来说是不容易的。